作者:Chunyuan Chen, Yunuo Cai, Shujuan Li, Weiyun Liang, Bin Wang, Jing Xu
时间:2025.12
来源:arXiv
背景
伪装目标检测(COD)依赖带像素级标注的伪装场景,但真实数据规模远小于通用检测数据集;用生成模型做 伪装图像生成(CIG) 是自然的补数据路径。现有 CIG 往往卡在两类现象上:要么前景与背景外观不够像,伪装感弱;要么背景纹理看似丰富,却与物体语义、场景常识不一致。RealCamo 把问题明确成「外绘式」生成里 小前景、大背景 带来的 视觉相似性 与 语义/结构合理性 难以同时满足,并用两条互补的控制链来收紧生成过程。
贡献
- 可控的伪装图像合成框架 RealCamo
- 在 Stable Diffusion 1.5 + ControlNet 上,用 布局控制生成器(LCG) 注入 对比度、深度、HED 轮廓 等多路结构先验,约束 全局空间布局,减轻「语义上说不通」的背景。
- 用 面向纹理的背景检索(TOBR) + 文本–视觉条件生成器(TVCG) 构造 多模态条件(统一细粒度英文任务描述 + 类别表征 + 检索到的背景视觉线索),在交叉注意力里引导内容,提升 真实感与前景–背景外观一致性。
- 伪装效果与结构真实性的评价
- 除 FID、KID 外,用 SSIM 衡量生成图与参考图之间的 结构一致性(对应「在尽量保持原场景布局的前提下做背景纹理/色彩调整」的设定)。
- 提出 前景–背景分布差异指标 KL_BF:在 RGB 各通道上比较前景与背景像素分布的 KL 散度 再平均;数值越低 表示 前景与背景外观分布越接近,即「越伪装」。
方法
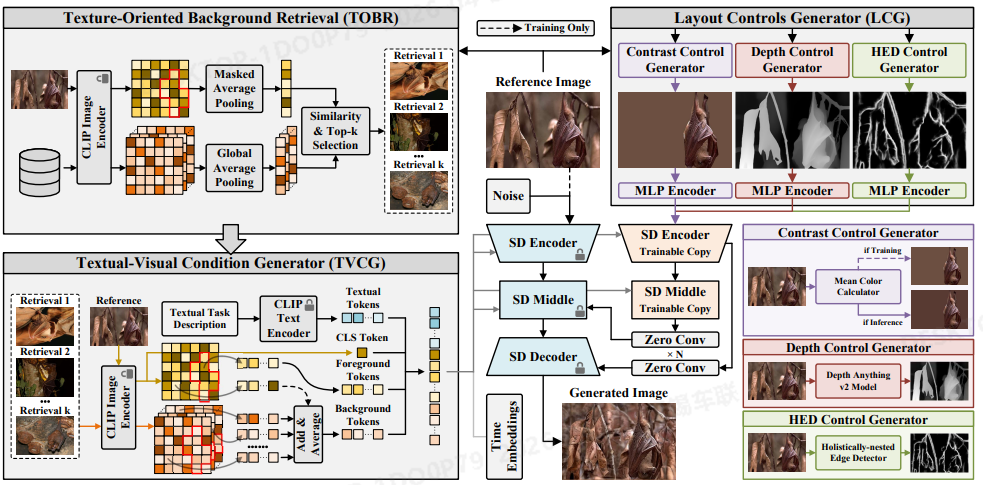
可把 RealCamo 看成两条 并行注入 的信息流:
(1)结构/layout:LCG → ControlNet
对输入图像与前景掩膜,LCG 提取三类控制信号,经 各自 MLP 嵌入 再融合后送入 ControlNet:
- 对比度控制:延续 CamoAny 思路,在训练/推理阶段有不同处理,用于 稳住前景、约束对比。
- 深度控制:用 Depth Anything V2 得到深度图,约束 前后景层次与空间关系。
- HED 控制:Holistically-Nested Edge Detection,约束 主要结构轮廓,避免背景「碎、飘、无主体几何」。
(2)语义与纹理:TOBR + TVCG → 多模态序列条件
- TOBR:不用通用图像 codebook,而以 伪装图像库 为领域知识库;用 CLIP 图像编码 对前景做 掩膜内平均池化 得到纹理敏感查询,与库中候选做相似度,取 top-k 检索图。
- TVCG 拼出三段序列特征再拼接:
- 统一细粒度英文任务描述(避免「fish camouflaged with background」式过简提示,也避免为每个场景手写长描述);经 CLIP 文本编码;
- 物体类别信息:用 CLIP 图像分支的 [CLS] 式表征,不显式依赖人工类名;
- 参考背景视觉线索:把检索样本与当前图在 背景区域 做融合式嵌入(训练与推理在是否包含当前图背景项上略有不同),得到 带背景知识的视觉 token。
实验
数据与设置:在 LAKE-RED 上训练与评测;评测集含伪装 / 显著 / 一般三类各 6473 张,合计 19419 张。指标:FID、KID、SSIM、KL_BF;实现细节含 512 分辨率、batch 4、60 万步、单卡 L20 等。
结果
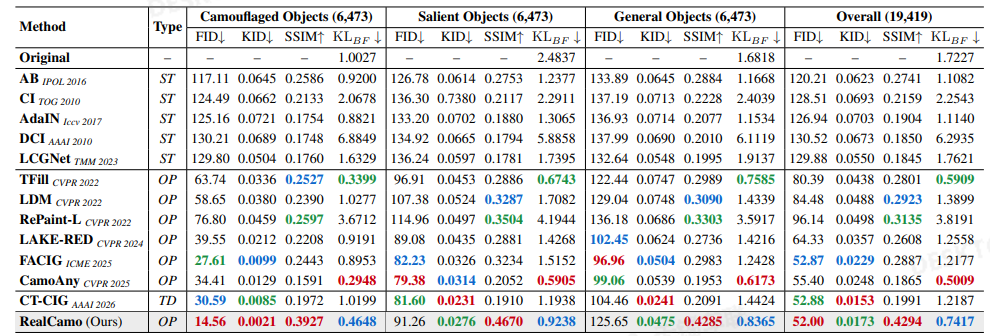
SOTA 对比(Table 1)
- 相对早期风格迁移与多种外绘、文本驱动方法,RealCamo 在 FID/KID 与 SSIM 上整体 明显更优,说明 生成质量与结构保真 强。
- KL_BF:RealCamo 在部分子集上 并非全场最低;论文解释是 CamoAny、TFill 等更低 KL_BF 的方法在视觉上「更融」,但 RealCamo 选择 在伪装强度、结构一致与真实感之间做折中,这与 Fig.4 的定性叙述一致——也反向说明 KL_BF 作为「伪装度」量化是有解释力的,但不能单独当唯一目标。
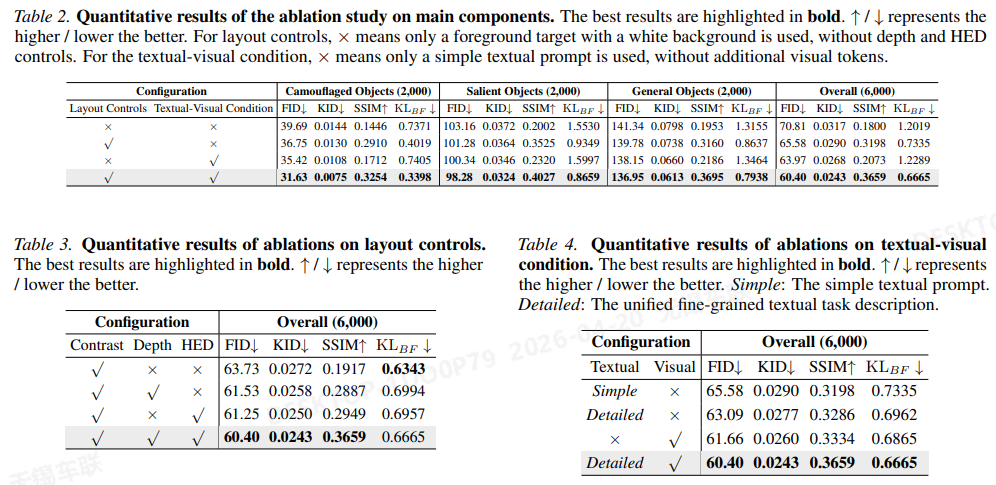
消融(Table 2–4)
- 仅布局 / 仅文本–视觉 都不如 两者全开;说明 几何布局 与 纹理–语义引导 互补。
- 布局子项(Table 3):对比度单独不够;深度与 HED 各带来不同收益,全开最好;附录中还讨论深度偏 层次、HED 偏 轮廓锐利度 的互补性。
- 文本–视觉(Table 4):从简单提示到 统一细粒度任务描述 提升显著;再加 视觉检索线索 进一步拉升 FID/KID/SSIM,并影响 KL_BF。

下游 COD(Table 5)
- 原始 COD 训练数据 + SynCOD12K:在 CHAMELEON、CAMO、COD10K、NC4K 上 多数指标一致提升。
- 把显著/一般子集生成的伪装图加进训练(Ori + Gen S&G) 反而 伤害性能——论文归因于与真实 COD 数据的 域差。
总结
RealCamo 针对外绘式 CIG 的 结构失控 与 纹理–语义弱 两个问题,分别用 多路布局控制(对比度 + 深度 + HED) 和 纹理导向检索 + 统一文本任务 + 视觉 token 收紧扩散生成;同时用 SSIM + KL_BF 把「像真场景」与「像伪装」拆开度量。实验上在 LAKE-RED 上 图像质量与结构指标突出,并 用 SynCOD12K 实证了可服务 COD 增广;也诚实讨论了 KL_BF 与主观真实感之间的张力。
对齐思考
1. 技术创新:多模态拓扑认知
不只盯像素像不像,还要看 目标与地形的空间关系(反斜面、植被嵌套等)。做法:LLM 给出 地形–目标布局 → 落成 拓扑语义图;再配上 3D 拓扑先验码本(某类地形下装备怎么摆的统计模式)。视觉只算 2D 不够时,用 语义–几何交叉注意力:图里的关系对齐到图像里的结构,从 找伪装像素 升到 认整体阵型拓扑,便于判断集结、潜伏这类意图。
2. 技术目标:虚拟声景孪生
Unity 少靠随机调参。用 LLM 战术布局 定场景骨架,用 植被、雾、光斑、伪装网覆盖率 等当旋钮。画面喂给感知模型:太容易认(≈1)或完全瞎(≈0)就 自动改环境,专门往 分数在 0.5 附近、模型最犹豫 的场景收。这样产的数据 难例含量高,也更贴 Sim2Real 要训的那类边界。
3. 场景功能:EchoMie
在「情绪文本驱动画面」之上,把 指示条件 扩成 「情绪 + 文旅叙事」:同一段视频里,LLM 不仅解析心情,还解析 景点/文物/非遗 IP 的讲解词、传说、节令、方言旁白 等文本。码本一侧接 情绪–画风(治愈/热烈),另一侧接 地域与文化视觉原语,用注意力对齐 画面里真实出现的景物(牌匾、器物、地貌),再注入卡通渲染与 AR。