作者:张凌峰,张欣雅,郝帅,徐沁文,张强,王鹏伟,张静,王中原,张尚航,徐人静
时间:2025.7
来源:ACL 2025
单位:1 香港科技大学(广州);2 北京人工智能研究院;3 清华大学;
研究背景
任务定义:视觉语言导航( VLN)要求智能体根据自然语言指令,在未见的陌生环境中进行导航。
现有挑战:
·存储与计算开销:传统的端到端模型,通常依赖“历史观测序列”)作为记忆。随着导航步数增加,内存占用和计算负担呈线性增长。
·空间感知缺失:仅靠堆叠历史图像,模型难以理解环境的拓扑结构和物理约束,容易产生空间位置的“幻觉”,导致导航效率低或碰撞。
·跨模态理解鸿沟:VLM虽然强大,但很难将抽象的色块与具体的指令描述精准对应。
核心贡献
1、提出 ASM :设计了一种新型的记忆表征方式——“标注语义地图”。它将复杂的 3D 环境信息压缩成带有文字标注的 2D 俯视图,有效替代了昂贵的视频帧记忆。
2、构建 MapNav 框架:开发了一个端到端的导航模型,能够同时处理当前视角图像、ASM 地图和语言指令。
3、极高的效率:MapNav 将推理时间减少了约 79.5%,且无论路径多长,内存占用始终固定在 0.17MB。
4、SOTA 性能:在 R2R-CE 和 RxR-CE 等主流连续环境基准测试中,性能全面超越了以往的 SOTA 模型(如 NaVid)。
核心方法
MapNav 的工作流程主要分为 ASM 生成 和 导航推理 两个部分:
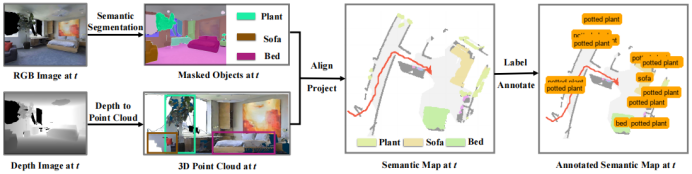
一、ASM 生成流程——ASM 是一张既有物理轮廓,又有明确文字说明的导航图。
1、3D 点云构建 :
智能体获取当前的 RGB-D 图像和相机位姿。
将这些 2D 像素根据深度信息还原到 3D 空间,生成点云。
2、2D 投影与映射:
将 3D 点云从正上方投影到 2D 平面上,生成顶视角的语义地图。
3、文本标注 :
系统利用语义分割识别出物体,计算其中心点,并在地图对应的位置显式地写上文字标签。
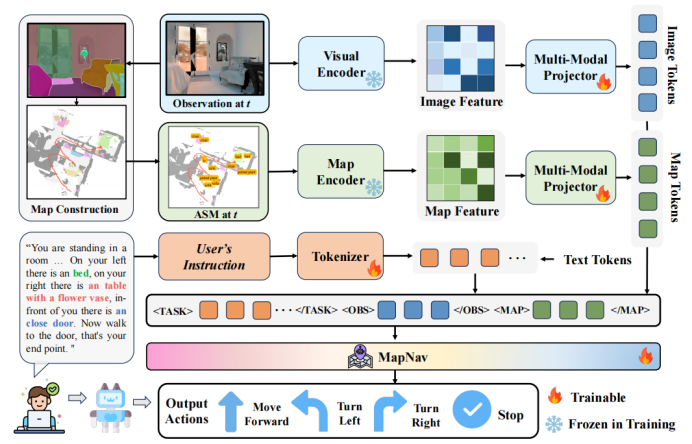
二、导航决策
1、多模态输入: 模型同时接收 当前视角图像、实时更新的 ASM 地图、用户语言指令 三个输入。
2、双流编码器:
使用视觉编码器分别提取“当前图像”和“ASM 地图”的特征。
3、大语言模型推理:
将对齐后的视觉特征与指令特征输入到 Qwen2 等大模型中,模型直接输出下一步的自然语言动作指令。
实验结果
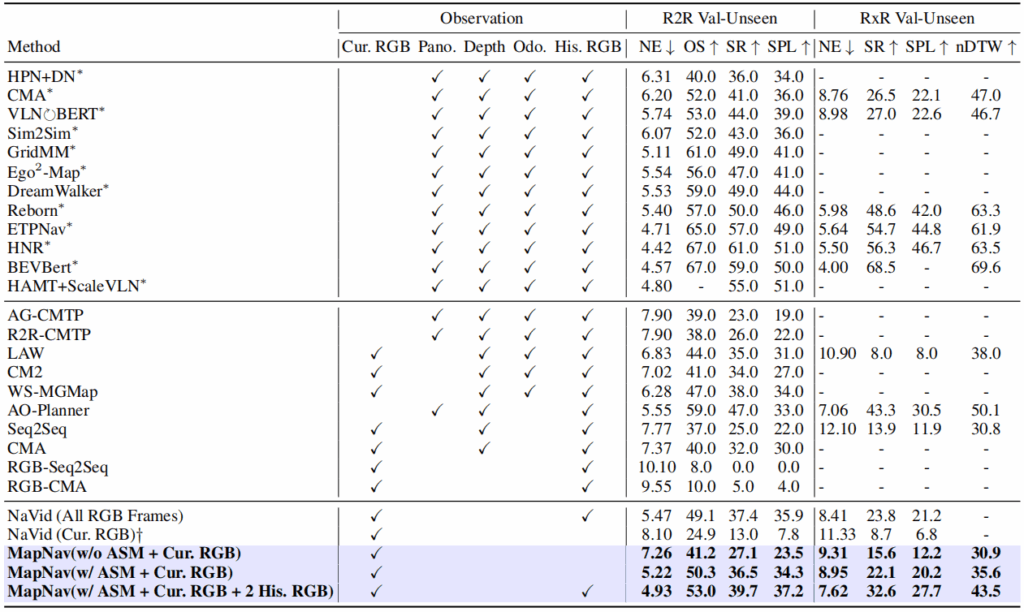
A. 性能对比
仿真环境:在 Habitat 仿真器上,MapNav 在成功率(SR)和成功加权路径长度(SPL)上显著优于此前的最强模型 NaVid。

真实环境测试:在办公楼、会议室等真实场景中,使用宇树 Go2 四足机器人进行实测,证明了极强的从仿真到现实的迁移能力。

B. 效率分析
内存占用:传统方法随步数增加可能需要几百 MB 内存,MapNav 始终保持在 0.17 MB。
推理速度:单步推理时间从 1.22 秒降至 0.25 秒。
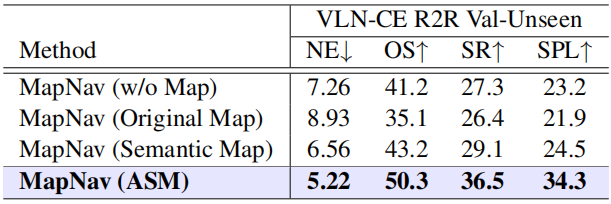
C. 消融实验(证明 ASM 的有效性)
只有地图 vs 带标注的地图:实验证明,如果在地图上删掉文字标注,只剩色块,模型的成功率会大幅下降。
结论:显式的文字标签能显著引导 VLM 的注意力,帮助模型实现语言描述与物理空间的精准锚定。
结论
MapNav 证明了结构化的地图记忆远优于非结构化的图像序列记忆。通过 ASM,它成功解决了 VLM 在导航中的空间幻觉问题,为未来移动机器人在复杂、大规模环境中的自主导航提供了一个高效且精确的新范式。
三维对齐思考
1、方法创新——全域数据拓扑建模
MapNav 的核心贡献在于将传统的、冗余的“视频帧序列记忆”转化为结构化的“标注语义地图(ASM)”,系统不再仅仅被动地记录视觉像素,而是通过深度信息将 3D 点云实时投影为 2D 拓扑网格,并在网格的关键坐标上显式地锚定语义标签。这种建模方式将复杂的空间拓扑关系压缩为大模型易于理解的语义张量,不仅极大地降低了系统对内存的占用,更重要的是实现了一种“空间——语义——文本”三位一体的建模。它使得大模型在处理环境数据时,面对的不再是杂乱的像素块,而是具备清晰物理属性和文化逻辑的拓扑节点,为后续的复杂推理提供了具有全局观的底层数据架构。
2、技术目标——虚实空间孪生推演
参考 MapNav 的投影对齐技术,通过将实时观测视角与底层物理网格精确对齐,可以确保所有虚拟生成的建议或渲染效果都建立在真实的物理约束之上。在这种孪生架构下,系统能够精准识别坡度、障碍物及连通性,从而对大模型的输出进行强制性的物理过滤与纠偏。这意味着,任何基于语言指令生成的交互建议或视觉特效,都能在孪生模型中进行预先的物理校验,从而消除“战车在悬崖部署”或“虚拟特效脱离物理表面”等逻辑错误,实现虚拟信息与物理空间的深度耦合与精确共振。
3、中试产品——埃觅文旅
通过深度图还原与 2D 投影技术,建立严格的虚实映射,解决 AR 装置与风格化渲染中常见的“漂浮感”和“穿模”问题,确保虚拟特效精准贴合真实地形与建筑,消除大模型的空间幻觉。