作者:Qingkai Min, Zitian Qu, Qipeng Guo, Xiangkun Hu, Zheng Zhang, Yue Zhang
来源:EMNLP
单位:浙江大学、清华大学、复旦大学等
发表日期:2025.11
论文介绍
背景动机
现实中事件信息分散在多个新闻或文本中,不同文档提供互补细节,需要统一整合才能获得完整事件理解。
已有工作多集中在句子级或单文档级事件抽取,对跨文档信息融合关注不足。
多文档场景存在:长上下文、表达不一致、事件/实体共指复杂、需要强推理能力,这些都超出现有模型能力范围
研究目标
旨在解决多文档事件抽取中信息分散与结构复杂的问题,提出一种结合大语言模型与小语言模型的协同框架。通过利用小模型完成结构化子任务,大模型进行多步推理与全局整合,实现跨文档事件的对齐与融合。同时构建新数据集与评测指标,以系统评估多事件聚合能力,从而提升复杂场景下事件抽取的准确性与完整性。
核心内容
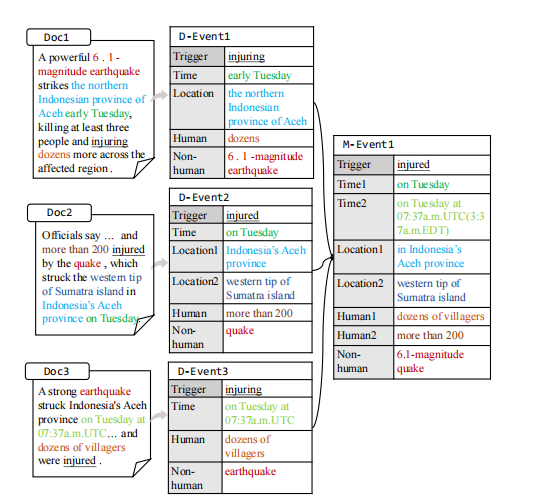
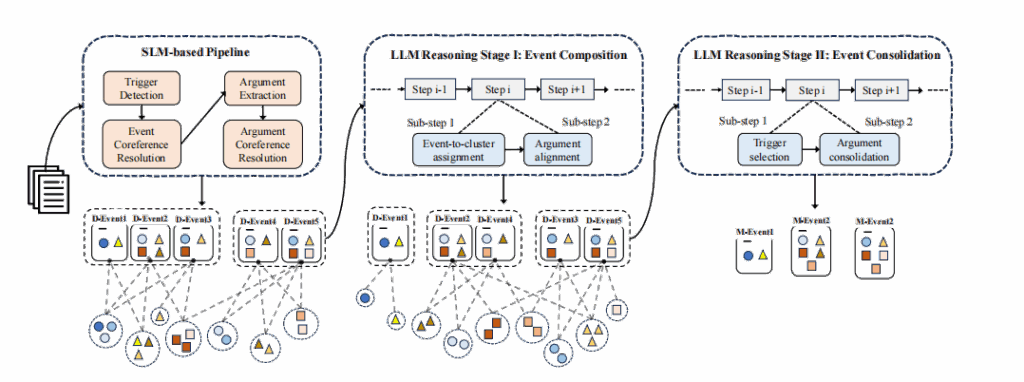
该方法首先利用小语言模型抽取结构化的事件碎片(如trigger和argument),然后通过大语言模型进行两阶段推理:先完成跨文档事件的对齐与组合,再进行事件信息的整合与规范化,从而得到最终统一的事件表示。
实验评估
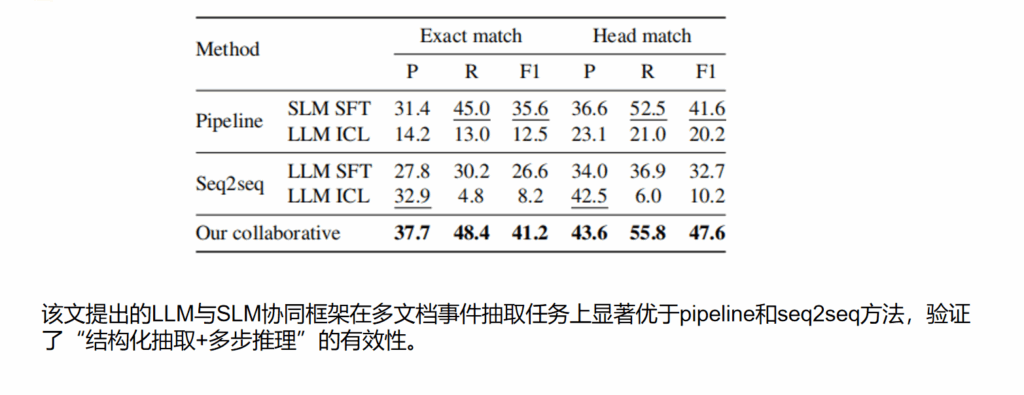
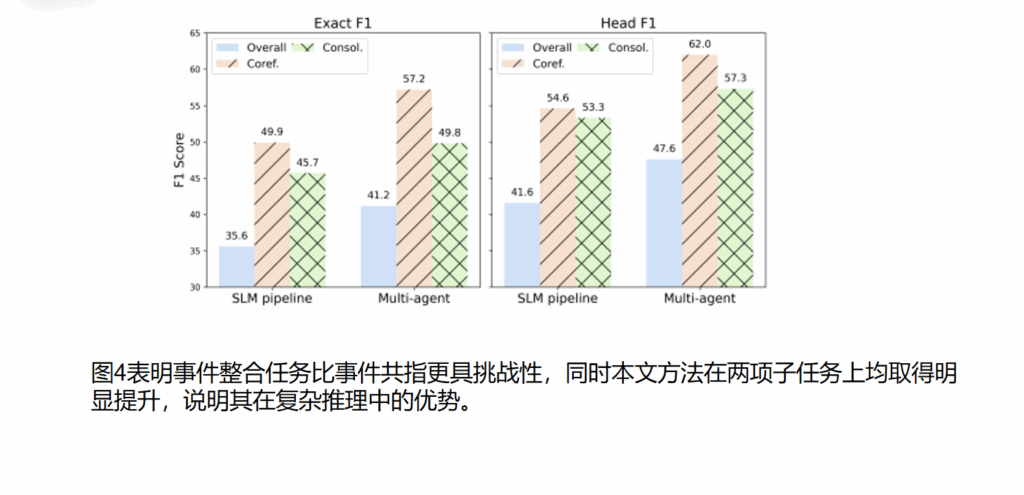
总结思考
论文总结
核心方法:提出一种LLM与SLM协同的多文档事件抽取框架,通过SLM完成触发词检测、参数抽取与共指解析等子任务,再由LLM进行多步推理,实现事件跨文档聚合与结构统一。
实验结果:实验表明,该方法在ECB++数据集上显著优于传统pipeline方法和LLM端到端生成方法,在事件共指与参数整合任务中均取得更高性能。实验在 DocRED、CDR 和 GDA 三个数据集上进行验证,结果表明 ATLOP 在文档级关系抽取任务上显著优于现有方法,在 DocRED 数据集上达到 63.4% F1 的新 SOTA。实验分析还表明,自适应阈值机制能够有效缓解多标签决策问题,而局部上下文聚合可以在实体数量较多的文档中更准确地定位关系证据
优势总结:该方法结合了SLM的结构化能力与LLM的推理能力,有效解决了多文档场景下信息分散、表达不一致和推理复杂的问题,实现了高质量事件聚合。
启发思考
1.1技术创新-逻辑思维推理框架:该文提出了一种“SLM结构化抽取 + LLM多步推理”的协同框架,通过将复杂任务拆解为结构抽取(local)与跨文档推理(global)两个层次,并在后续阶段进行事件对齐与信息整合,实现了复杂信息的逐步构建。这一思路对我的实验具有直接启发:我当前采用LLM对文档分块抽取信息碎片,并以实体为中心进行聚合,再进一步抽取结构信息,本质上与该框架类似。但该文进一步强调了对齐+整合的两阶段推理机制**,说明仅依赖一次聚合仍不足以处理复杂语义关系,需要引入显式的多步推理过程来提升信息融合质量。
2.1技术目标-专业手册公共服务:通过LLM对实体或事件进行跨块对齐判断、语义一致性评估以及冗余信息过滤,从而提升整体抽取结果的准确性与一致性。
3.1场景功能-食养通:结合我的应用场景,可以借鉴本文框架构建“分块抽取 + 聚合对齐 + 结构整合”的多阶段信息抽取流程。例如,在以实体为中心的知识抽取任务中,可以先基于LLM完成局部信息抽取,再通过类似“事件组合”的机制对不同来源的信息进行对齐,最后通过“信息整合”步骤生成统一、规范的知识表示。这种方法不仅能够提升跨文本信息融合能力,还可以增强结果的一致性、完整性与可解释性,为复杂知识服务系统(如RAG或结构化知识库构建)提供更可靠的数据支持。