作者:Zirui Shao1, Feiyu Gao, Zhaoqing Zhu, Chuwei Luo, Hangdi Xing, Zhi Yu, Qi Zheng, Ming Yan, Jiajun Bu1
单位:浙江大学浙江省无障碍感知与智能系统重点实验室、阿里巴巴
来源:ACL 2025
时间:2024.11
研究背景
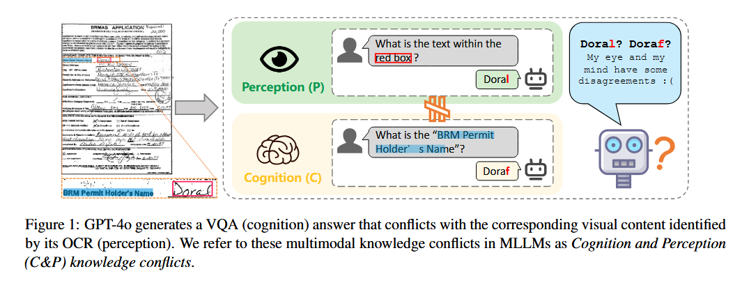
随着多模态大模型(MLLM)的发展,文档理解已经从单纯的 OCR 演进到了复杂的文档问答(DocVQA)。然而,研究人员发现 MLLM 经常出现“逻辑断层”:它能正确回答关于文档内容的问题,但当你让它识别图片中对应的文字时,它却识别错了;反之亦然。这种不一致性限制了模型在金融、医疗等高精度场景的应用。
研究问题
认知与感知的二元对立:作者认为 MLLM 内部存在两个并行的过程。感知(Perception)负责将图像像素转化为文本序列(OCR),认知(Cognition)负责根据指令生成语义答案(VQA)。
训练噪声的根源:论文指出,现有的多模态数据集(如 LAION)通常包含大量的机器生成 OCR 标签或质量参差不齐的众包问答对。当模型同时学习这些不一致的数据时,它实际上是在学习“矛盾”。
解决办法- MKCF 框架
提出了一种名为 Multimodal Knowledge Consistency Fine-tuning (MKCF) 的方法:
数据构建:构造包含感知路径和认知路径的训练数据。
感知路径:给定坐标,要求识别文本。
认知路径:根据图像内容回答问题。
关联路径:要求模型说明答案是在哪个坐标位置找到的。
损失函数优化:在训练中引入一致性偏置,如果感知与认知冲突,会给模型一个较大的惩罚。
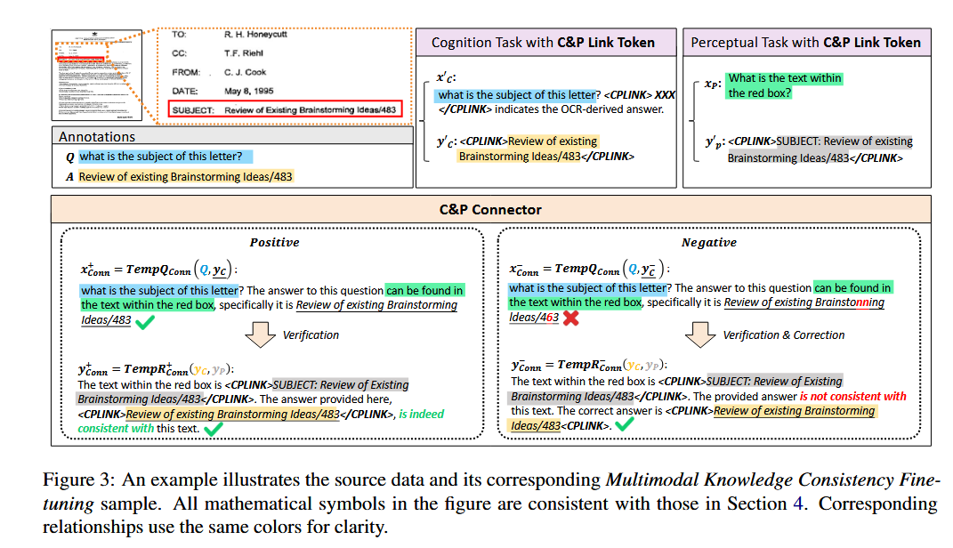
C&P Link Tokens:在模型处理流程中,引入特定的格式化输出。模型必须以 [Location] -> [Text] -> [Answer] 的链式结构进行思考。这种“显式推理”迫使视觉特征在进入语言解码器之前,已经完成了空间上的对齐。
Negative Sample Training(负样本训练):主动喂给模型一些错误的感知结果,训练模型具备“纠错能力”。让模型学会:如果感知输入是有误的(例如由于光照产生的噪声),如何利用语义背景知识进行反向修正。
实验
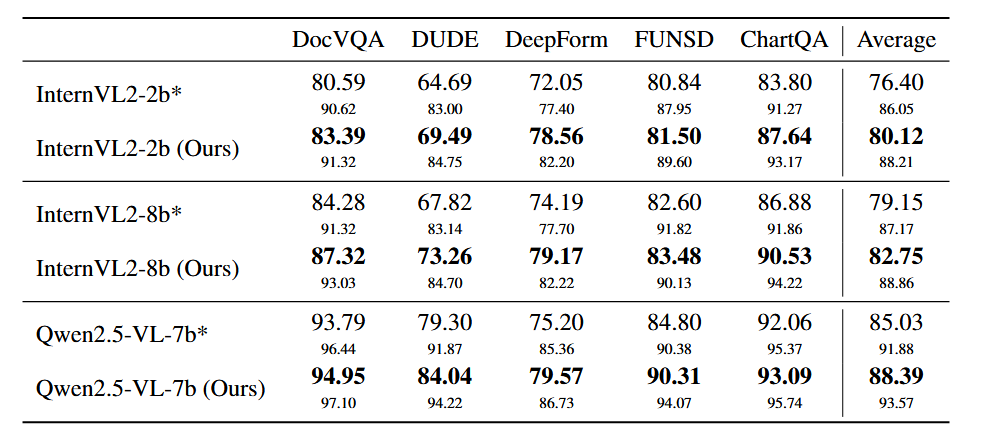
在 DocVQA、DeepForm 等五个主流文档理解数据集上进行测试,覆盖了表格、表单、图表等多种文档形态。
核心内容总结:
1.定义并量化了 C&P (Cognition & Perception) 知识冲突,并提出了“C&P一致性”评估指标。它不再只看 VQA 答对没有,而是强行要求模型先进行一次视觉定位(Pointing/OCR),再看生成的答案是否与定位到的文本内容一致。这为评价模型“幻觉”提供了一个可量化的维度。
2.提出多模态知识一致性微调 (MKCF) 。
坐标锚定(Coordinate Anchoring):在微调时,不仅仅让模型输出答案,还要求输出对应的文本边界框(Bounding Box)。
跨模态链路标签(Link Tokens):通过加入 等标记,人为地在神经网络的注意力机制中埋下“钩子”,迫使认知输出必须向感知输出对齐。