- 作者:Ke Yang、Zixi Chen、Xuan He、Jize Jiang 等
- 发表单位:University of Illinois Urbana-Champaign、Tsinghua University、Microsoft Research
- 发表在:ICML 2026
核心内容
- 本文主要围绕 LLM Agent 的长期记忆问题展开:现有 memory module 要么是 task-specific,只适合某一种任务;要么虽然 task-agnostic,但是基本依赖 raw memory retrieval,容易出现上下文爆炸和低相关性问题。
- 作者提出了 PlugMem,一个 task-agnostic 的 plugin memory module。它的核心想法不是把历史轨迹、对话、网页观察这些 raw experience 直接检索回来,而是先把它们抽象成更紧凑的 knowledge-level memory。
- 具体来说,PlugMem 把 agent 的记忆分成三类:
- Episodic memory:原始经验和交互轨迹,用来做证据和溯源;
- Semantic memory:事实型知识,也就是 proposition;
- Procedural memory:流程型知识,也就是 prescription。
- 这篇文章把问题放在了 memory representation 上:真正对决策有用的信息,通常不是原始轨迹,而是从轨迹里抽象出来的事实和流程。
背景
LLM Agent 在长程任务中经常需要长期记忆。比如,一个对话助手要记住用户之前的偏好,一个网页 agent 要记住如何搜索、筛选、下单,一个 QA 系统要从大量文档中找出多跳证据。
最简单的做法是把历史内容都存成 chunk,然后 query 来的时候做 retrieval。但是这样有两个问题:
- Raw memory 太长
原始对话、网页观察、工具调用轨迹往往非常啰嗦,里面大部分 token 对当前决策没有帮助。 - Raw memory 太低层
Agent 真正需要的往往不是“当时网页上完整显示了什么”,而是“面对这类任务应该先搜索,再过滤,再验证结果”。
已有的一些 agent memory 方法会做压缩、总结、图结构组织,但很多方法都和具体任务强绑定。比如长对话记忆方法适合用户画像,网页 agent memory 适合工作流,但很难直接迁移到另一个任务。
PlugMem 想解决的就是这个问题:能不能设计一个通用的 memory backbone,让不同任务都能使用同一套 memory abstraction、retrieval 和 reasoning 机制?
技术方法
论文的方法主要包括三个部分:Structuring Module、Retrieval Module 和 Reasoning Module。
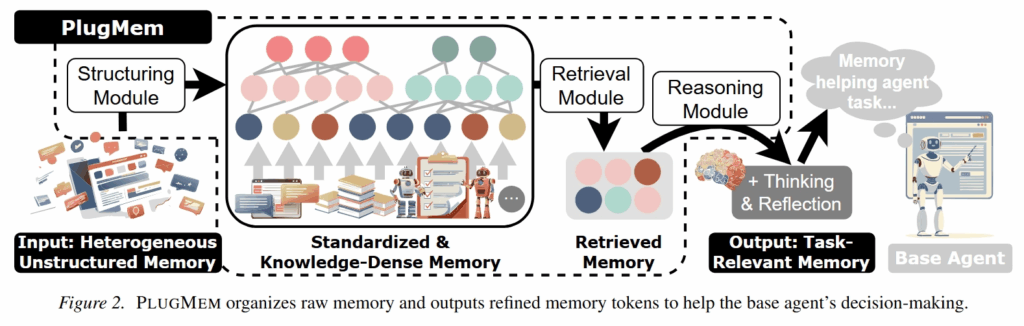
Structuring Module
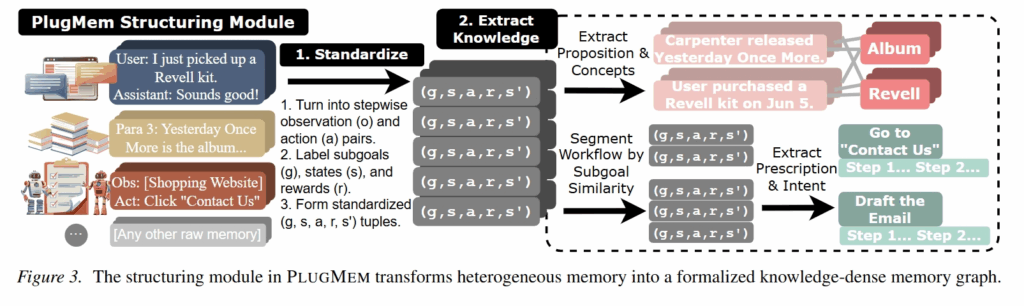
PlugMem 首先把原始记忆标准化成 episodic memory。对于一个原始交互轨迹,它把每一步表示成:
e_t = (o_t, s_t, a_t, r_t, g_t)
其中:
o_t是 observation;s_t是当前 state;a_t是 action;r_t是这个 action 对目标的 reward / evaluation;g_t是 subgoal。
这个设计有点像把 agent trajectory 重新整理成一种轻量 RL-style 的轨迹表示。它不是为了训练 RL,而是为了让后续的知识抽取更标准。
然后 PlugMem 从 episodic memory 里抽取两类知识。
第一类是 semantic memory,也就是 proposition。
比如从历史对话中抽出“用户在 6 月 5 日购买了 Revell kit”,或者从文档中抽出某个实体的事实描述。每个 proposition 会带一组 concept tags,用来做索引。
第二类是 procedural memory,也就是 prescription。
它会先根据 subgoal 的相似度把轨迹切成若干段,然后从每一段里抽取一个 (intent, prescription) 对。intent 表示这段轨迹想完成什么目标,prescription 表示完成这个目标的一套可复用流程。
例如网页购物任务里,系统可能抽出:
Intent: 找到某个商品的最低价格
Prescription: 先搜索商品,再按价格排序,然后检查不同变体中的最低价。
这一步是全文最重要的设计。PlugMem 不再把 memory 当成“历史文本”,而是把 memory 当成“可复用知识”。
Memory Graph
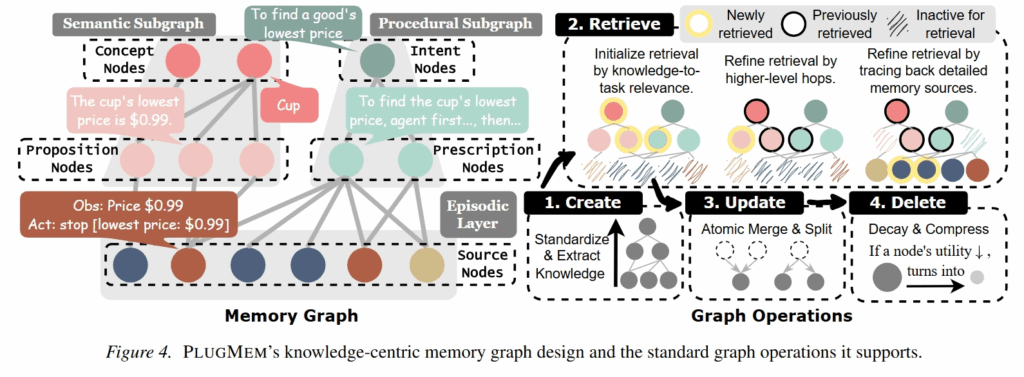
PlugMem 构建了三个互相关联的图:
- Episodic Graph
存储原始经验片段,主要用于 grounding 和 verification。 - Semantic Graph
包含 proposition node 和 concept node。
concept 是轻量索引,proposition 是事实内容。 - Procedural Graph
包含 intent node 和 prescription node。
intent 是任务目标索引,prescription 是可复用流程。
它和传统 GraphRAG 最大的区别在于:传统 GraphRAG 往往以 entity 或 text chunk 作为图节点,而 PlugMem 以 knowledge unit 作为节点。也就是说,图的基本单位不是“实体”,而是“一个完整事实”或者“一套完整流程”。
Retrieval Module
PlugMem 的检索不是简单 embedding top-k。
它先根据当前 query 判断需要哪类 memory:episodic、semantic 还是 procedural。然后主要在 semantic graph 和 procedural graph 上做检索。
检索过程可以理解成两层:
- 低层节点
proposition / prescription,是真正要返回给 agent 的内容。 - 高层节点
concept / intent,不直接作为最终 memory,而是作为路由信号。
比如 HotpotQA 里,query 先检索到一个 proposition,发现关键 bridge entity 是 Jim Croce,然后系统通过 concept 层继续跳到和 Jim Croce 相关的其他 proposition,最后找到出生年份。
所以它的检索逻辑是:
query → low-level candidate → abstract concept / intent → more low-level candidates
这叫 abstraction-specificity interleaving。直觉上就是先找到一个具体线索,再把它提升成抽象路由信号,然后用这个信号去找下一跳证据。
Reasoning Module
检索出来的 memory 即使已经是 proposition / prescription,也可能仍然有重复或噪声。所以 PlugMem 在最终喂给 base agent 之前,还会用 LLM 做一次 reasoning / compression。
对于 semantic memory,它会抽取和问题最相关的事实。
对于 episodic memory,它会让 LLM 基于历史片段进行 step-by-step reasoning。
对于 procedural memory,它会把多个历史流程整合成当前任务下的行动建议。
在 WebArena 里,这个模块尤其重要。PlugMem 不是简单告诉 agent“以前做过类似任务”,而是会根据当前网页状态动态生成下一步 guidance。比如当前还没进入正确类别,它会建议先用 dropdown 找类别;如果已经进入类别页,它会建议应用价格过滤;如果已经过滤完成,它会建议比较 rating 并加入购物车。
实验
论文用了三个任务来验证 PlugMem 的通用性
- LongMemEval:长程对话记忆;
- HotpotQA:多跳知识检索;
- WebArena:网页交互式 agent 任务。
Baseline 包括 No Context、All Context、Vanilla Retrieval、A-Mem、Zep、LiCoMemory、RAPTOR、PropRAG、HippoRAG2、AWM 等。
实现上,embedding 主要用 NV-Embed-v2,structuring 和 reasoning 使用 Qwen2.5-32B/72B-Instruct 和 GPT-4o,不同 benchmark 下设置略有区别。
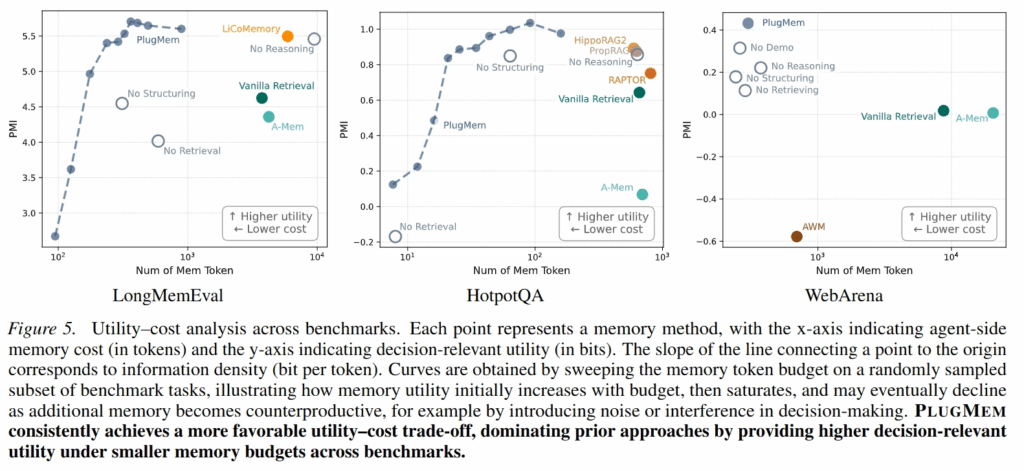
LongMemEval
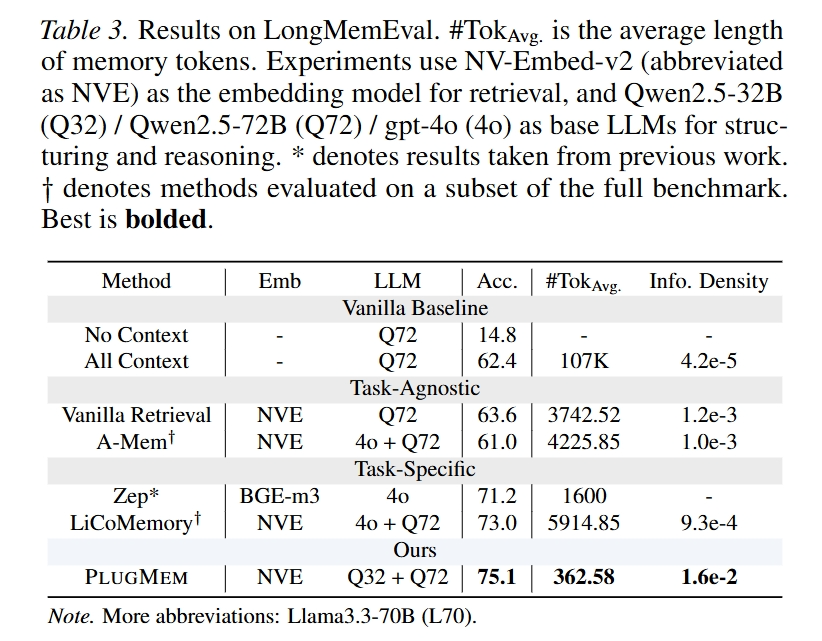
LongMemEval 用来测试长期对话记忆。结果里 PlugMem 的 accuracy 是 75.1,超过了 Vanilla Retrieval、A-Mem、Zep 和 LiCoMemory。
更关键的是 token 数。PlugMem 平均注入 agent 的 memory token 只有 362.58,而 Vanilla Retrieval 是 3742.52,LiCoMemory 是 5914.85。也就是说,它不是靠塞更多上下文赢的,而是靠更高密度的 memory 赢的。
这很符合它的动机:原始对话太长,真正有用的是抽象后的 proposition 和可溯源 episodic evidence。
HotpotQA
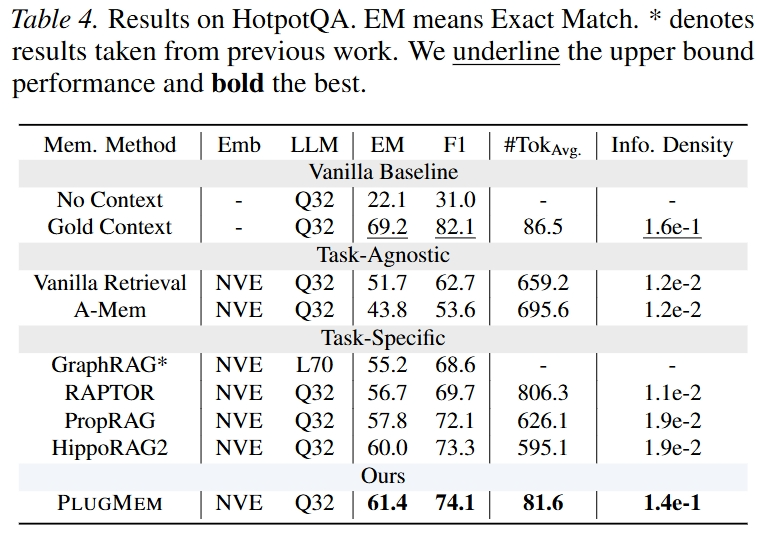
HotpotQA 用来测试多跳语义检索。PlugMem 的 EM/F1 是 61.4 / 74.1,超过 Vanilla Retrieval、A-Mem、RAPTOR、PropRAG 和 HippoRAG2。
比较有意思的是,它平均 memory token 只有 81.6,甚至接近 Gold Context 的 86.5。这说明它的 reasoning module 把检索到的信息压缩得很厉害。
不过这里也要注意:HotpotQA 本质不是 agent trajectory,所以 PlugMem 在这个任务里把每个 corpus text 当成一个单步 trajectory,action、state、reward、intent 这些字段基本是空的。也就是说,在 HotpotQA 上,PlugMem 的“统一 episodic representation”更像是工程接口上的统一,而不是语义上真的有完整 agent 轨迹。
WebArena
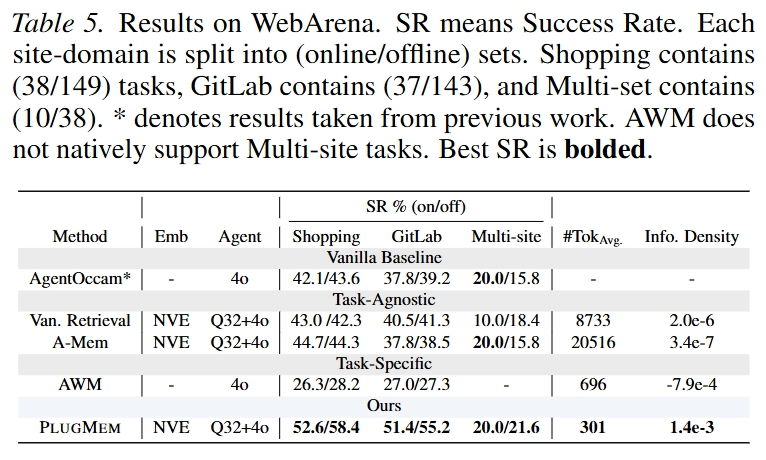
WebArena 用来测试 procedural memory。PlugMem 在 Shopping 和 GitLab 上提升明显。
论文把 WebArena 分成 online set 和 offline set。Online 阶段允许 agent 插入和检索 memory;之后加入少量 human demonstration;Offline 阶段主要测试 memory reuse,也就是新任务能不能继承之前构建好的 memory graph。
结果显示,PlugMem 在 Shopping 和 GitLab 的 offline success rate 都明显高于 AgentOccam 和其他 memory baseline。这说明 procedural memory 对网页任务确实有帮助。
不过这里也有一个需要警惕的点:PlugMem 在 WebArena 里加入了 human demonstrations,而且给 AgentOccam 添加了“要参考 retrieved memory”的额外指令。因此它的收益不完全是 memory structure 本身带来的,也包含一定的 prompt integration 和 demonstration warm-start 效果。
4. 消融实验
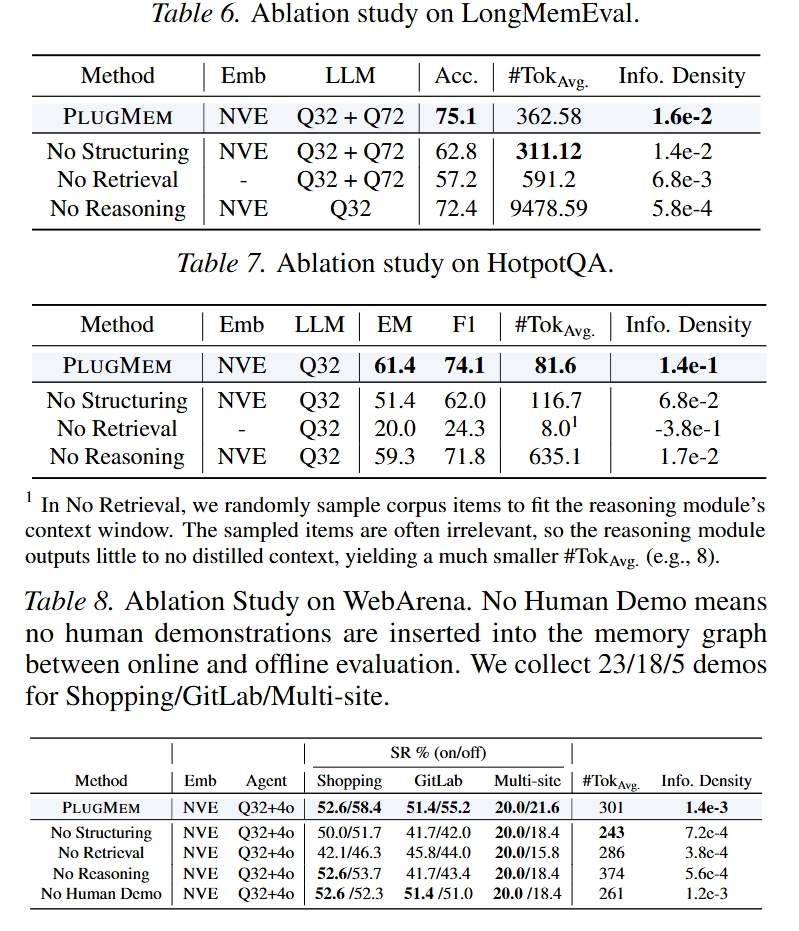
消融实验比较清楚:
- 去掉 retrieval 掉得最明显
说明 memory 有没有用,首先取决于能不能在决策时找到相关 memory。 - 去掉 structuring 也会明显变差
说明 raw memory / chunk memory 的表示方式确实不如 proposition / prescription 这种 knowledge unit。 - 去掉 reasoning 后,性能下降不一定最大,但 token 数会暴涨
比如 LongMemEval 里 No Reasoning 的 memory token 达到 9478.59,而完整 PlugMem 只有 362.58。说明 reasoning module 的主要作用是提高信息密度,而不只是提高准确率。
作者自己的总结也很准确:retrieval 决定 memory 是否能发挥作用,structuring 决定什么东西可以被检索,reasoning 决定检索到的东西能不能高效使用。
评价指标:Memory Information Density
它认为只看 accuracy、F1、success rate 不够,因为 memory module 还要考虑 agent-side cost。一个方法如果提高了准确率,但每次都塞十万 token,那就不一定是好的 memory。
所以作者定义了 Decision Information Gain:
PMI(a*; m | s) = log2 P_mem(a* | s, m) / P_base(a* | s)
意思是:加入 memory m 以后,agent 选择正确动作 a* 的概率提高了多少。
然后再除以 memory token 数:
ρ = PMI / |m|
这就得到 memory information density,单位是 bits/token。
这个指标的直觉很好:一个 memory module 不应该只追求“更有用”,还应该追求“单位 token 更有用”。
不过这个指标在实际计算上也有一点工程味。比如在 QA 任务中,作者会用答案 overlap / F1 近似概率,并且要做 smoothing,避免 log 里出现 0。所以它不是一个特别纯粹的概率测量,更像是一个统一比较 memory utility-cost tradeoff 的分析工具。
结论
- 本文提出了 PlugMem,一个 task-agnostic 的 plugin memory module,目标是让不同类型的 LLM agent 都能复用同一套长期记忆框架。
- PlugMem 的核心不是简单检索历史文本,而是把 raw episodic memory 抽象成 semantic memory 和 procedural memory。前者对应 proposition,后者对应 prescription。
- 它的 memory graph 是 knowledge-centric 的:concept / intent 作为高层索引,proposition / prescription 作为低层知识节点,episodic trace 作为证据层。
- 实验说明,agent memory 的关键不是“存得越多越好”,而是能不能把对决策有用的信息抽象出来,并在任务时用较少 token 检索回来。
- 这篇文章真正有价值的地方,是把 agent memory 的问题从“长上下文检索”推进到了“经验到知识的抽象”。
启发与评价
- 方法创新点【memory-to-knowledge abstraction】
PlugMem 的亮点是把 agent memory 从 raw trajectory 提升成 proposition 和 prescription。这个方向很有意义,因为 agent 长期运行时积累的历史大部分都是低价值噪声,真正可复用的是事实、偏好、规则和流程。 - 技术目标点【task-agnostic memory backbone】
它想做的不是某个任务上的最优 memory,而是一套跨任务的 memory backbone。LongMemEval、HotpotQA、WebArena 分别对应 episodic、semantic、procedural 三种能力,实验设计本身也在服务这个叙事。。 - 中试产品点【食养通 / 个性化建议 Agent】
PlugMem 对食养通也很有启发。用户的长期偏好、禁忌、历史提问可以抽成 semantic memory;食养建议流程、标签解读流程、风险解释流程可以抽成 procedural memory。