来源:ACL
作者:Fnu Mohbat、Mohammed J. Zaki
单位:Rensselaer Polytechnic Institute
发表时间:2025 年 5月
一、研究背景
核心背景
食物选择直接影响个体健康、营养摄入和生活方式。
与电影、音乐、电商推荐不同,食物推荐需要考虑更多现实约束:
用户喜欢或不喜欢的食材
饮食禁忌,如无麸质、低脂、低钠、素食等
营养需求,如蛋白质、脂肪、糖、胆固醇、纤维等
健康目标,如控制热量、减少钠摄入、增加高纤维食物
现有问题
很多推荐系统只根据用户历史行为或相似菜谱做推荐。
很多食谱生成模型可以生成做法,但不一定保证符合饮食和营养约束。
很多营养估计方法只关注热量,忽略蛋白质、脂肪、纤维、胆固醇等细粒度营养信息。
食谱推荐本质上是一个“多约束、多目标”的推荐问题。
这篇文章提出构建一个统一的食物智能系统KERL,能够同时完成:
个性化食谱推荐
食谱烹饪步骤生成
微量营养信息生成
二、主要框架
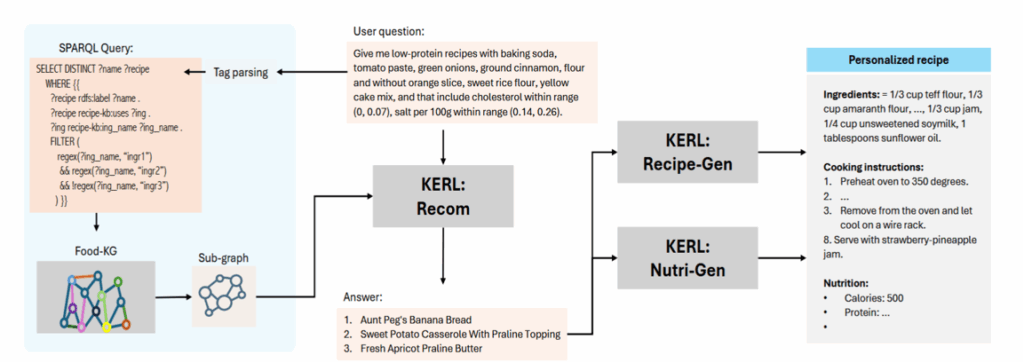
用户问题 → 标签 / 喜欢食材 / 不喜欢食材 / 营养范围 → 推荐结果。
把用户自然语言问题转换为可检索的 KG 子图。
将 KG 子图作为上下文输入 LLM。
用任务专属 LoRA 适配器分别完成推荐、食谱生成和营养生成。
最终形成一个从“用户需求”到“可烹饪、可分析食谱”的完整系统。
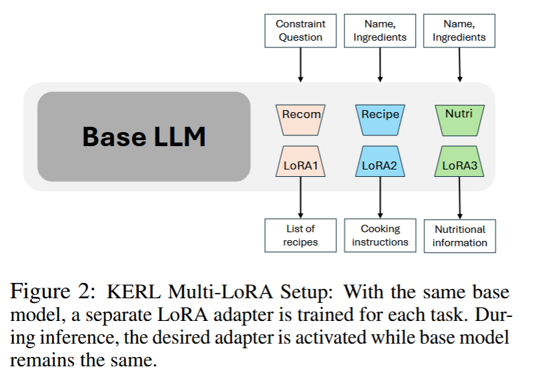
多 LoRA 架构设计
KERL 使用同一个基础模型 Phi-3-mini。
针对三个任务分别训练三个 LoRA adapter:
LoRA1:推荐任务 KERL-Recom
LoRA2:食谱生成任务 KERL-Recipe
LoRA3:营养生成任务 KERL-Nutri。
三、基准数据集构建
食物推荐领域缺少大规模、带复杂约束的自然语言问答数据。
真实用户数据难以获取,尤其是包含饮食偏好、禁忌和营养需求的数据。
基于模板、FoodKG 和 GPT-4 构建了大规模 benchmark。

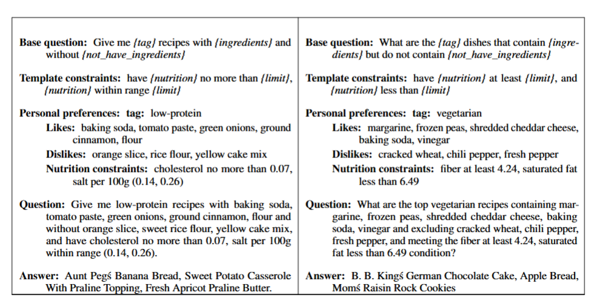
KGQA Benchmark — 用于训练和评估 KERL-Recom。
Nutrition Generation Benchmark — 用于训练和评估 KERL-Nutri。
Recipe Generation Benchmark — 用于训练和评估 KERL-Recipe。
四、实验
- 实验设置与评价指标
实验任务
任务一:个性化食谱推荐
任务二:食谱烹饪步骤生成
任务三:微量营养信息生成
推荐任务评价指标
mAP:衡量推荐结果排序质量。
Precision:推荐出的菜谱中有多少是真正正确的。
Recall:正确答案中有多少被模型找出来。
F1:Precision 和 Recall 的综合指标。
食谱生成任务评价指标
BLEU-1 / BLEU-2 / BLEU-3 / BLEU-4
SacreBLEU
METEOR
ROUGE-1 / ROUGE-2 / ROUGE-L
CIDEr
Perplexity
营养生成任务评价指标
MAE:Mean Absolute Error,平均绝对误差。
对每一种营养指标分别计算预测值与真实值之间的误差。
MAE 越低,说明营养估计越准确。
- 推荐任务结果
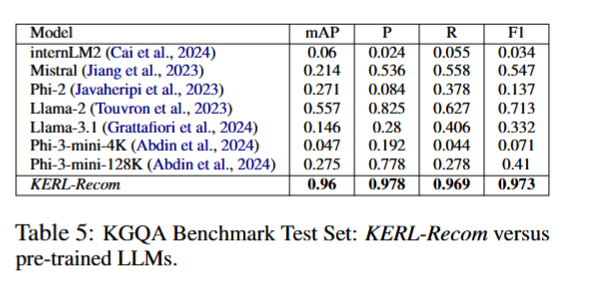
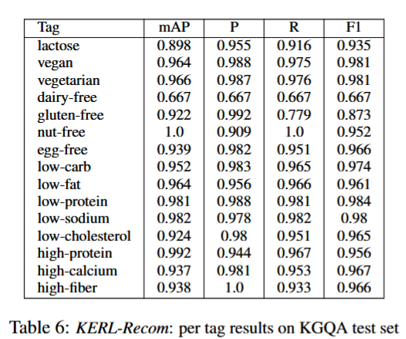
KG 子图 + LoRA 微调才是性能提升的核心来源。单纯扩大上下文长度并不能解决复杂约束推荐问题。
普通 LLM 容易忽略部分约束,尤其是负向食材和数值营养条件。
KERL-Recom 先从 KG 中检索候选子图,再让 LLM 在候选中选择答案。
这种方式减少了模型自由生成错误答案的空间。
- 食谱生成实验结果
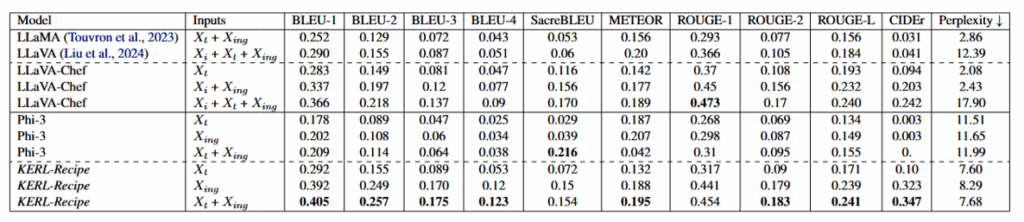
食材输入比单独菜名更重要。
菜名 + 食材的组合效果最好。
KERL-Recipe 只训练 LoRA 参数,而 LLaVA-Chef 涉及更大规模训练。
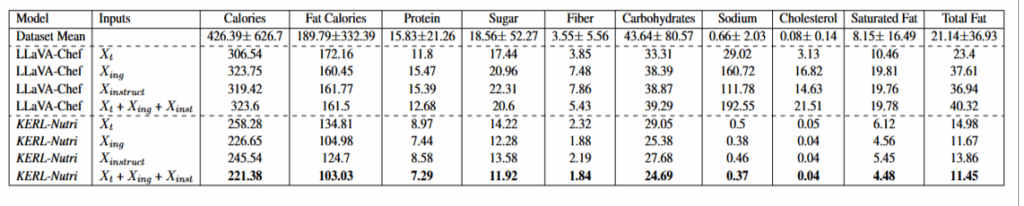
- 营养生成实验结果
KERL-Nutri 在所有输入设置下均显著优于 LLaVA-Chef。
当输入为菜名 + 食材 + 烹饪步骤时,KERL-Nutri 效果最好。
这说明营养预测需要综合使用完整食谱信息。
五、总结与综合对齐思考
(一)论文核心内容
这篇论文把 KG 的精确约束检索能力和 LLM 的语言生成能力结合起来,做成了一个完整、可落地的个性化食物推荐系统。其核心贡献包括:
让 LLM 在可靠知识库支持下完成复杂饮食约束推理:
KERL 不只是做“推荐菜名”,而是把个性化食谱推荐、烹饪步骤生成、营养信息生成 三个任务整合到一个系统里。它用 FoodKG 检索结构化食物知识,再把相关子图作为上下文输入 LLM,从而缓解纯 LLM 容易幻觉、忽略约束的问题。
设计了高效的多 LoRA 任务适配方案,并构建大规模 benchmark 验证有效性:
文章没有为三个任务分别训练完整模型,而是在同一个 Phi-3-mini 基础模型上训练三个独立 LoRA adapter:推荐、食谱生成、营养生成。这样既模块化又节省训练成本。
同时,论文构建了 KGQA 和营养生成两个大规模数据集,并通过实验说明 KERL 在推荐 F1、食谱生成指标、营养 MAE 上都明显优于基线。
(二)三维度对齐思考
1.0 方法创新点-逻辑思维推理框架
这篇论文强化领域知识证据,当前工作已经基于食谱原始字段和任务导向标注构建了多维比选所需的数据基础;而 KERL 进一步表明,在真实应用系统中,可通过外部知识源增强 LLM 的证据获取能力,使 LLM 的多维度比选不仅基于原始字段描述。
2.0 技术目标点-跨域知识结构对齐
构建出高对比比较对:通过框架的检索-排序-LLM推理的pipeline,将高质量的健康候选产品送入比较对推理部分,构建(锚点食谱、候选产品1,候选产品2)的迭代逻辑比选,最终选择出最优食品,这篇论文提出如何去搭建可靠知识库来落地完整的一个系统需求,可以在之后的项目开发中去应用这种知识源增强的对比。
3.0 中试产品点-食养通
在pk比选这个部分进行应用,针对用户选中的食品,在系统中自动推出结合用户个性化的更健康产品,并展示出对比性解释说明提升推荐效果。