来源:arXiv
作者:Bernal Jiménez Gutiérrez,Yiheng Shu,Yu Gu,Michihiro Yasunaga 等
单位:俄亥俄州立大学
发表时间: 2024 年4月
一、论文介绍
背景:现有RAG系统因孤立编码,难以关联不同文档的信息(如需结合分散特征时无法有效关联);且多步检索方法(如IRCoT)迭代整合信息时,每步调用大模型导致过程缓慢昂贵。
核心:为解决上述问题,HippoRAG仿生海马体记忆机制,构建单步多跳检索框架——新皮层用LLM抽取构建知识图谱(KG),海马旁回用检索编码器添加同义词边,海马体以PPR图搜索实现单步关联跨文档信息。
二、动机与痛点
痛点:传统RAG系统因孤立编码,无法关联分散文档的信息(如需结合“斯坦福大学教授”与“阿尔茨海默症研究者”这类特征时,除非单篇文档同时提及,否则无法有效关联)。同时,多步检索方法(如IRCoT)虽能迭代整合信息,但每步需调用大模型,导致过程缓慢且成本高昂。
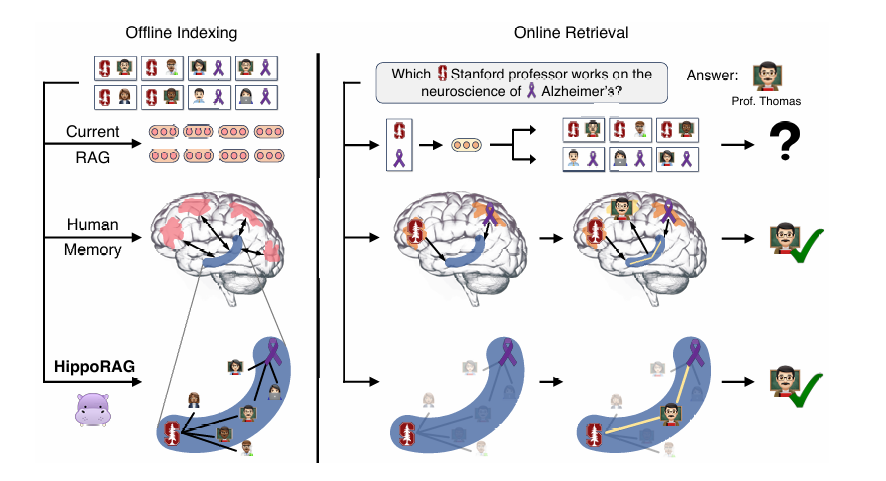
三、方法框架
1、新皮层(Neocortex):用LLM对语料库进行开放信息抽取(OpenIE),将非结构化文本转化为无模式知识图谱(KG)三元组(如“斯坦福”→“教授”→“阿尔茨海默症”);
2、海马旁回(Parahippocampal Regions):用检索编码器(如ColBERTv2)为KG节点生成向量,添加“同义词边”(如“斯坦福大学”与“Stanford”关联),辅助模式补全;
3、海马体(Hippocampus):将KG作为“人工海马体索引”,检索时以问题实体为起点,通过个性化PageRank(PPR)算法传播概率,一次性找到关联性最强的子图和文档。
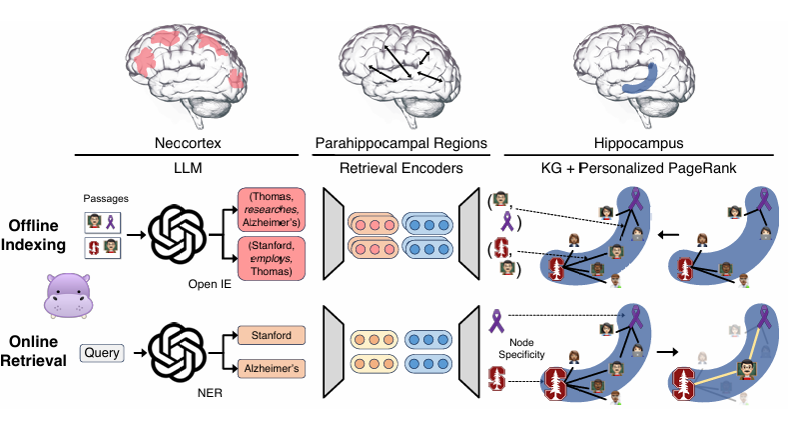
四、案例分析
以“Alhandra出生地”为例,展示HippoRAG如何工作:
索引阶段:LLM从文档中抽取三元组(如“Alhandra”→“出生在”→“Vila Franca de Xira”,“Vila Franca de Xira”→“位于”→“Lisbon District”),构建KG;
检索阶段:问题“Alhandra出生地”提取实体“Alhandra”,通过PPR在KG中传播概率,找到关联文档(如Vila Franca de Xira的文档),最终得出答案“Lisbon”。

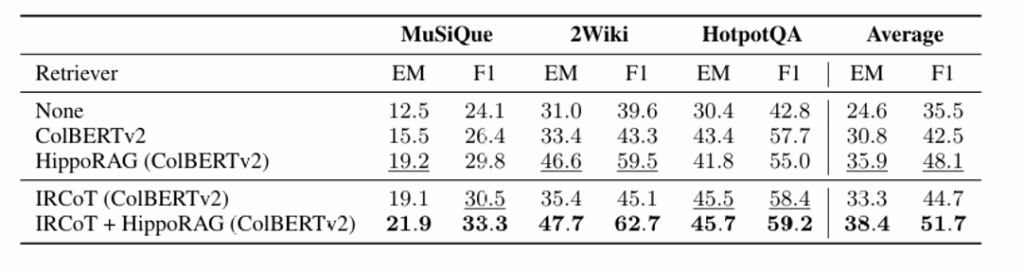
五、实验
HippoRAG在MuSiQue和2WikiMultiHopQA(多跳问答基准)上,R@5召回率比传统RAG(如ColBERTv2)提升3%-20%,证明单步多跳检索的有效性。
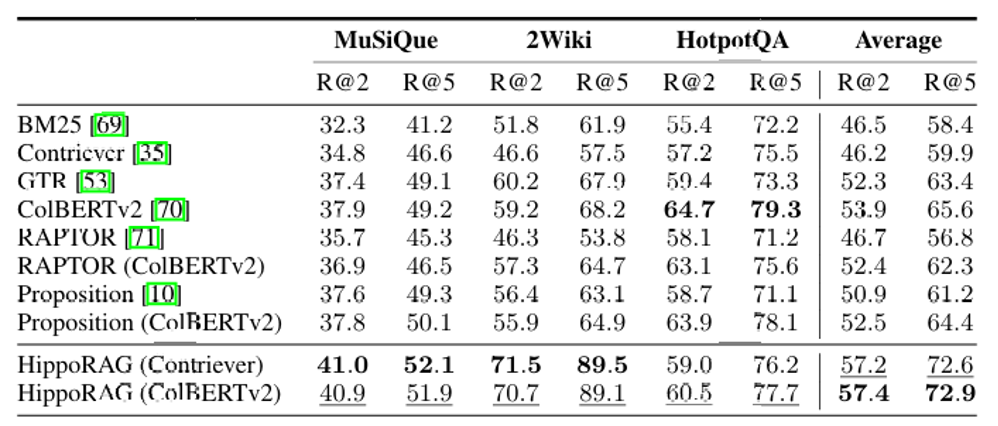
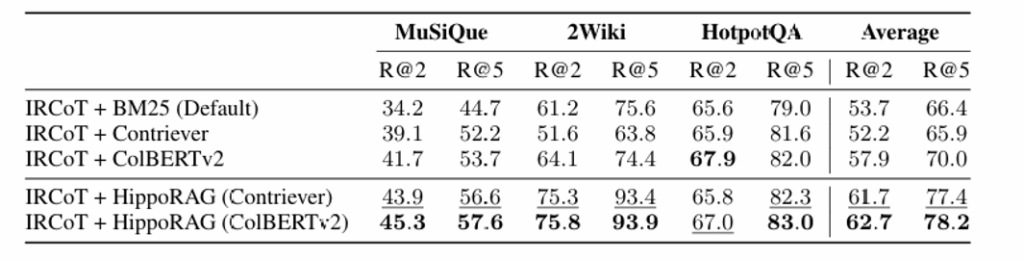
将HippoRAG嵌入IRCoT等多步框架,性能进一步提升(如MuSiQue R@5提升4%),说明其与现有方法互补。基于HippoRAG检索的QA模型,在多跳问答任务上F1分数提升3%-17%,验证了方法对下游任务的增益。
六、论文总结
(1)基于联想记忆图的跨文档知识关联:HippoRAG借鉴海马体理论构建知识图谱,通过图搜索关联分散知识,实现更有效的多跳推理(优于传统RAG的相似度匹配)。
(2)基于图扩散的单步多跳检索:HippoRAG通过PPR图扩散,在单次检索中完成多跳推理,降低传统迭代检索的时间与计算成本。
(3)可扩展的长期记忆组织:HippoRAG以知识图谱为载体,通过新增节点/边持续更新,保留关联路径,增强推理结果的可追溯性与可解释性。
七、对齐思考
技术创新——逻辑思维推理框架:HippoRAG通过关联记忆网络发现隐藏知识路径,而非仅依赖显式关系匹配。受此启发,MERICA可进一步构建经络—免疫联想因果网络,利用图扩散与路径搜索实现疾病、经络、免疫机制和干预措施之间的动态关联推理。
技术目标——跨域知识结构对比:HippoRAG表明复杂知识关联往往依赖关键中介节点。受此启发,MERICA后续可从关系对齐进一步扩展到桥接节点发现,自动识别肠道菌群、HPA轴、NF-κB等连接经络理论与免疫机制的重要中介环节,增强跨域知识融合能力。
场景功能——食养通:HippoRAG能够展示答案背后的关联路径。受此启发,食养通可从“输出调理建议”扩展为“输出调理依据”,同步展示疾病、机制与食养干预之间的推理链条,提升调理建议的透明度和可信度。