作者:Authors: Qiuna Tan, Runqi Qiao, Guanting Dong, YiFan Zhang, Minhui Wu, Jiapeng Wang, Miaoxuan Zhang, Yida Xu, Chong Sun, Chen Li, Honggang Zhang
来源:ACM MM 2025会议
时间:2025.11
背景与研究问题
大模型裁判的兴起:多模态大模型(LMMs)作为评估工具(LMM-as-a-Judge)在粗粒度评估(如对比、排序)中表现优异。但通常仅支持成对比较(Pairwise comparison)或直接打分/排序(Ranking),无法给出具体的定性改进建议。
在OCR 任务的局限性:在低分辨率、不规则排版和视觉歧义场景下,现有模型缺乏细粒度反馈与深度缺陷分析能力。
论文通过对大量开源 OCR 数据集进行错误挖掘发现:当前大模型在 OCR 任务中最大的软肋是图像信息定位(Localization Error),在各类场景中的错误率高达 45% 以上。 经常出现字符遗漏或排版对齐错误。因此,如何让模型具备‘自我诊断’和‘细粒度批评’的能力,是当前多模态 OCR 领域的关键瓶颈。
视觉编码器与文本空间对齐的失效,是制约当前 MLLM 执行高精度视觉文本理解的核心瓶颈。
核心方法:OCR-Critic 框架 (Proposed Solution)
一个核心模型:提出了 OCR-Critic,一个通用、即插即用的多模态裁判模型。两大创新支柱:自动化错误挖掘管道(Mining Pipeline):结合“模型引导标注”与“受控扰动合成”,构建了首个细粒度 OCR 错误分析的指令微调数据集(涵盖 50 种错误类型、30 种能力要求)。渐进式监督微调(Progressive SFT):采用三阶段训练法(单任务 –> 查询-响应解耦 –> 多任务),让模型从易到难掌握判别能力。
方法细节:动态 OCR 错误对齐策略 (Methodology Details)
从粗到细的层次化三阶段优化策略(Dynamic Alignment):
Strategy 1: 验证引导训练(Verification-Guided):动态过滤未标注数据中的噪点伪标签,只保留高置信度样本。
Strategy 2: 能力引导训练(Capability-Guided):动态评估 Actor 模型的能力缺失分布,据此调整后续样本的抽样权重(查缺补漏)。
Strategy 3: 错误引导训练(Error-Guided):对 Actor 模型的失败模式进行分类,优先让模型暴露在最常见的错误案例中(错题集强化)。
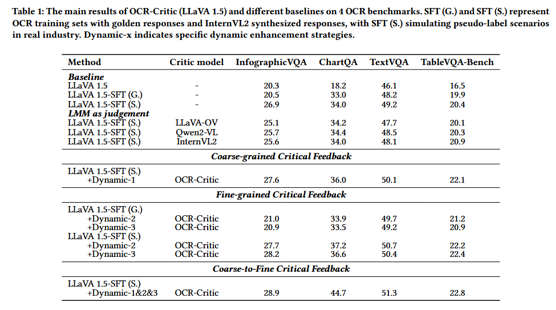
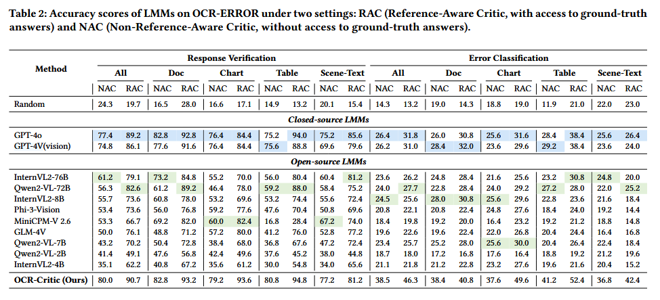
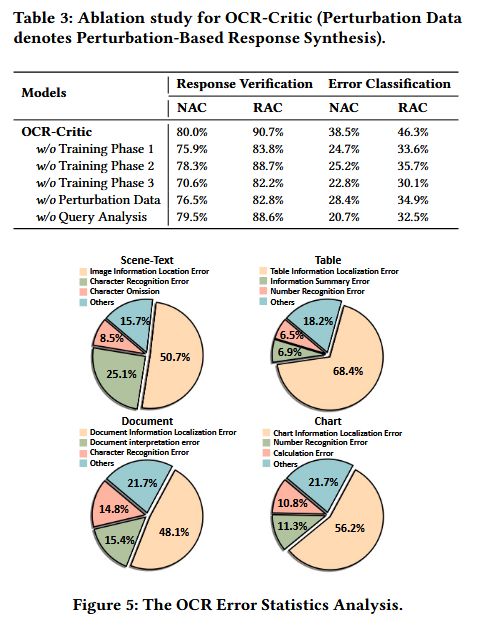
核心内容总结:
1.构建了首个涵盖 50 种细粒度 OCR 错误类型和 30 种底层多模态能力的视觉指令微调数据集。
2.提出了通用、即插即用的 OCR-Critic 模型,并独创了“验证-能力-错误”三层递进的层次化动态对齐策略(Dynamic Alignment)。