作者:Yaxiong Wu, Jianyuan Bo, Yongyue Zhang
来源:arXiv
单位:Huawei Technologies Co., Ltd
发表日期:2025.09
论文介绍
背景动机:
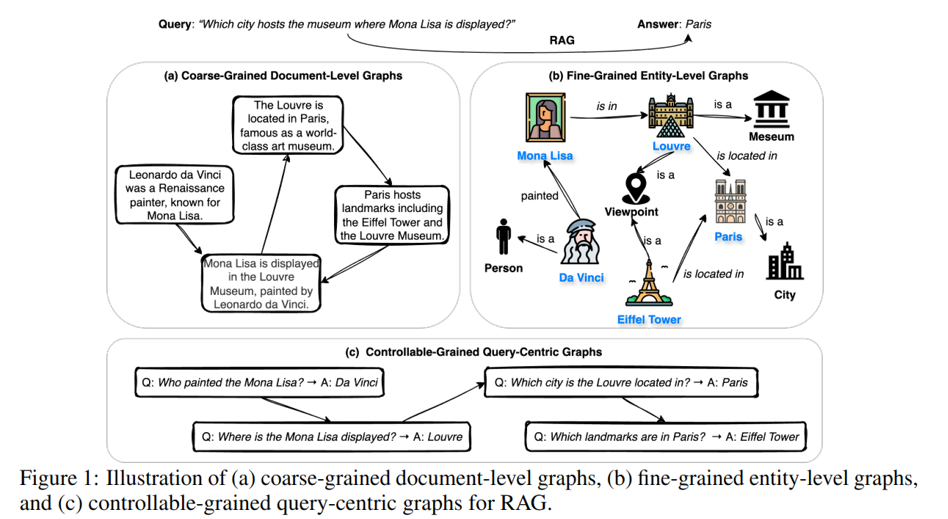
现实中事件证据分散在多篇文档中,图RAG需要跨文本块关联信息才能支持多跳推理与问答。
已有图RAG方法存在粒度两难:细粒度实体图token成本高且割裂上下文,粗粒度文档图又丢失细致关系,难以兼顾效率与语义。
Doc2Query等文档扩展技术生成的查询粒度适中,介于实体与文档之间,为图构建粒度可控提供了新思路。
研究目标:
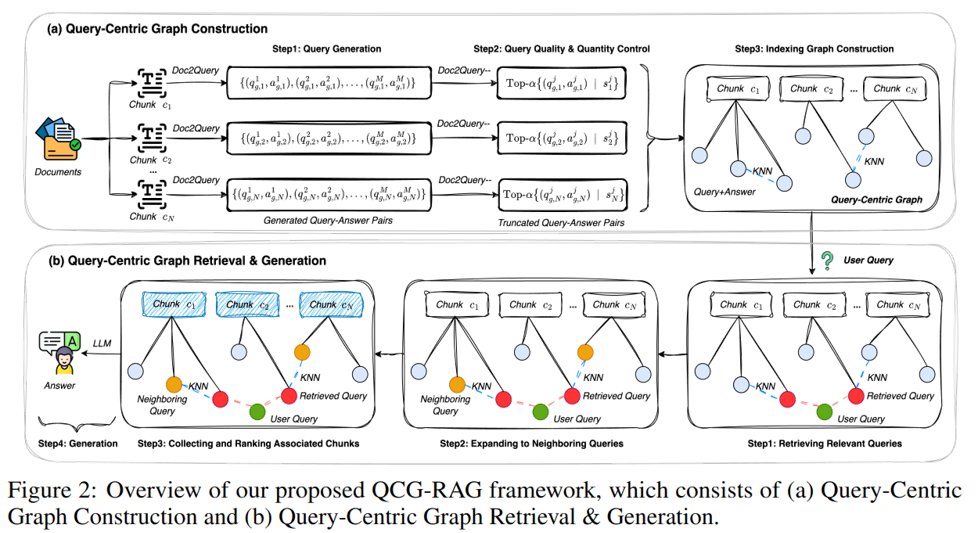
旨在解决图RAG方法粒度与效果难以兼顾的问题,提出一种查询中心的可控粒度图构建框架。利用生成式查询作为图节点,设计多跳检索机制精准聚合分散证据,从而提升多跳推理与长文档问答的检索质量与准确性。
核心内容
实验评估
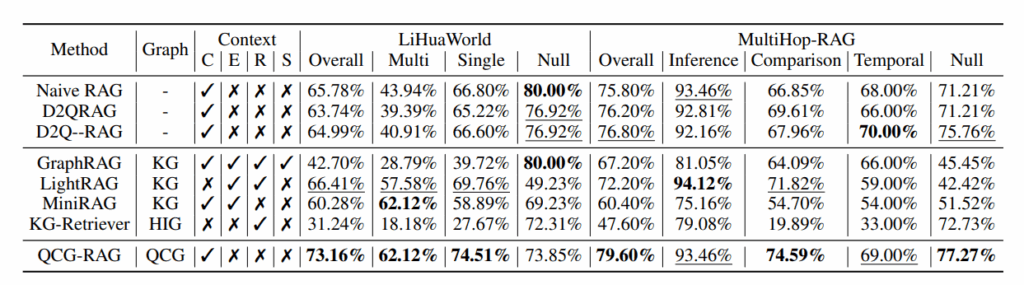
QCG-RAG在两个数据集上均取得最优整体准确率,尤其在多跳与对比类查询上优势显著
总结思考
核心方法:提出QCG-RAG框架,利用Doc2Query与Doc2Query–技术从文本块生成查询-答案对,以此构建粒度可控的查询中心图,并设计多跳检索机制实现对分散证据的精准定位与聚合。
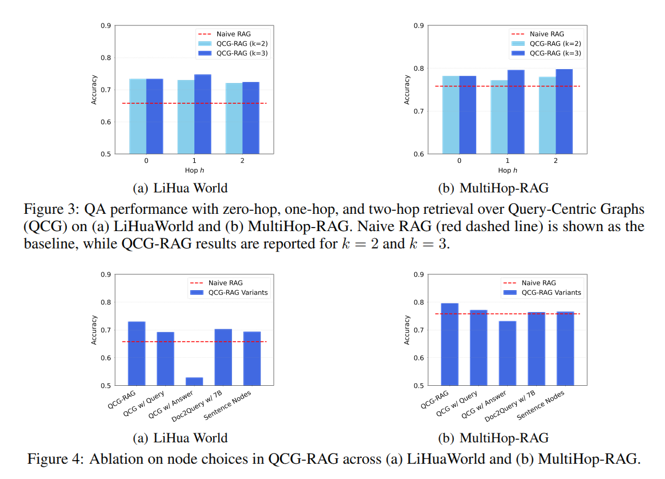
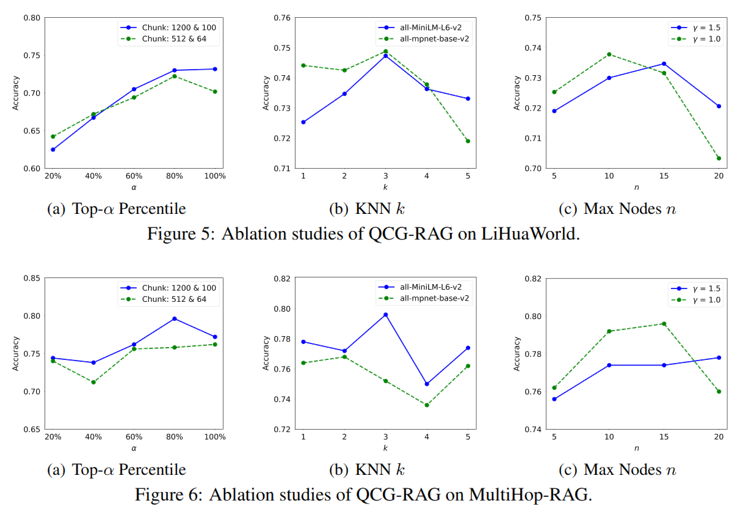
实验结果:实验表明,该方法在LiHuaWorld和MultiHop-RAG两个数据集上均超越已有的基于文本块和基于图的RAG方法,整体准确率分别达到73.16%和79.60%。相比Naive RAG分别提升7.4和3.8个百分点,在多跳与对比类查询上优势尤为明显(LiHuaWorld多跳62.12% vs LightRAG的57.58%;MultiHop-RAG对比类74.59% vs LightRAG的71.82%),同时在不可回答查询上保持稳健表现。消融实验进一步验证了Query+Answer拼接节点设计的有效性,并确定了α、k、n等关键超参数的最优取值范围。
优势总结:该方法通过查询中心的中间粒度设计,在语义丰富性与计算成本之间取得更好平衡,既避免了实体级图的高token开销与上下文割裂,又克服了文档级图关系模糊的问题,为图RAG的粒度困境提供了一种可解释、可控的解决思路。
启发思考
1.1技术创新-逻辑思维推理框架:1.1技术创新-中间变量的检索导向设计:该文在chunk与图索引之间引入query-answer对作为中间变量,先将chunk拆解为若干语义完整、聚焦单点的查询锚点,再用锚点构建检索图。这一思路与我pipeline中chunk→fragment的设计高度对应,但论文的中间变量同时承担检索优化职责(贴近用户提问形式),而我的fragment更偏向知识结构完整性,后续可以从检索效果出发,反思这一设计是否也需要兼顾检索友好性。
2.1技术目标-专业手册公共服务:论文让每条query不仅能被检索到,还能顺着关系找到相关的query,实现多跳检索。对应来说,我目前的fragment之间是孤立的,可以借鉴这一思路,让命题之间也能互相关联、按需扩展查找。
3.1场景功能-食养通对:应食养通场景,目前pipeline中chunk、entity_profile、proposition依次产出,但只有proposition被保留为最终检索单元。可借鉴此思路,将三者都作为可调用的知识库层级:扫码后先用实体级画像做快速安全判断,用户需要详情时再调取文档级原文展示出处,而非所有场景都依赖单一粒度的检索单元。