作者:Haocheng Liu, Diego Di Carlo, Aditya Arie Nugraha, Kazuyoshi Yoshii, Gaël Richard, Mathieu Fontaine
时间:2025
来源:WASPAA 2025
背景
声音事件检测与定位,SELD,通常同时完成两件事:判断当前时间片里发生了什么声音事件,以及估计对应声源的空间方向。近年来,深度学习模型已经可以较好地完成 SELD 任务,但在复杂房间声学环境下仍然容易受到反射、混响和训练数据不足的影响。传统做法往往从数据或网络结构入手,例如增加房间响应模拟数据、设计空间音频特征、改进 CRNN/Conformer/Transformer 等时序骨干。然而,这些方法大多只是让模型从数据中自己学空间规律,并没有直接要求模型输出符合真实声传播的物理结构。本文的出发点是:如果模型预测了一个声源方向,那么这个方向对应的多通道空间协方差结构也应该是物理上合理的。也就是说,模型不应该只在 DOA 数值上接近标签,还应该在空间统计结构上接近真实声场。因此,作者提出将物理空间先验作为训练阶段的正则约束,引导 SELD 模型学习更符合声学传播规律的表示。
核心贡献
- 提出一种 physically informed spatial regularization 方法:利用物理模型构造空间协方差矩阵,约束 SELD 模型的预测结果。
- 将声源方向估计与空间协方差矩阵,SCM,联系起来,使模型输出不仅在标签层面正确,也在物理空间结构上更合理。
- 设计两类 SCM 先验:一种基于解析 steering vector,另一种基于检索得到的房间脉冲响应,RIR。
- 将 inverse-Wishart log-likelihood 引入训练目标,用于衡量经验 SCM 与物理 SCM 之间的一致性。
方法
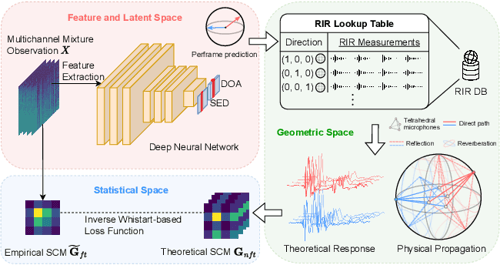
输入特征:
- 论文使用 SALSA-Lite 特征作为 SELD 模型输入。
- SALSA-Lite 本身包含多通道空间信息,适合用于声音事件检测与方向估计。
- 基础任务:
- 模型仍然完成常规 SELD 任务。
- 输出包括声音事件活动,SED,以及方向估计,DOA。
- 基础损失包括 SED 的分类损失和 DOA 的回归损失。
- 方法一:Algebraic steering-based SCM
- 根据麦克风阵列几何和预测 DOA,直接用 steering vector 构造理论 SCM。
- 优点是形式简洁、物理含义明确、不依赖额外 RIR 数据库。
- 缺点是主要描述直达声,对复杂反射和混响建模有限。
- 方法二:RIR-retrieved SCM
- 从 RIR 数据库中检索与当前预测方向接近的房间脉冲响应。
- 再利用这些 RIR 构造更接近真实房间传播的 SCM。
- 优点是可以包含反射和混响等复杂声学因素。
- 缺点是依赖 RIR 数据库质量,若数据库与测试环境不匹配,先验也可能失效。
实验
- 数据来源:
- 声音事件来自 NIGENS。
- 房间脉冲响应来自 TAU-SRIR。
- 通过合成方式构造 SELD 数据。
- 实验设置:
- 比较普通 SELD baseline 与加入物理空间正则后的模型。
- 分别测试 in-domain 和 out-of-domain 房间条件。
- 额外测试 low-data regime,即只使用少量训练数据的情况。
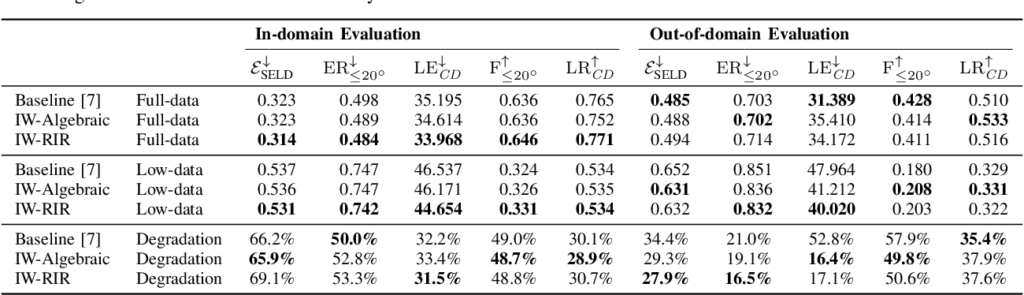
实验主要比较三种方法:
Baseline:不加物理正则;IW-Algebraic:用解析 steering vector 构造 SCM;IW-RIR:用 RIR 数据库构造 SCM。
从 Table 1 看,IW-RIR 在 in-domain full-data 和 low-data 场景下整体最好,说明物理空间正则确实能提升 SELD,尤其在训练/测试环境一致时更有效。
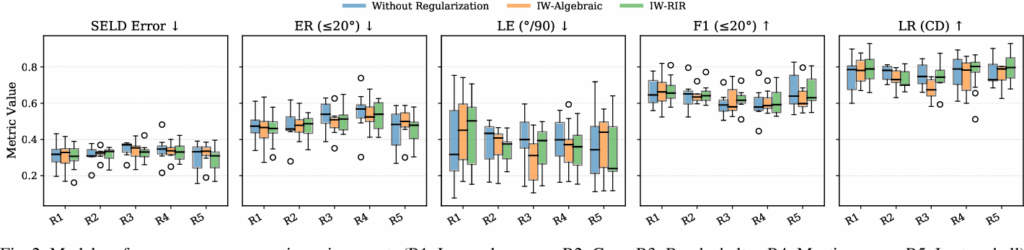
展示多次实验的分布。可以看到正则化方法整体有一定改善,但提升幅度不大,不是压倒性优势;DOA 相关指标的波动也比较明显。
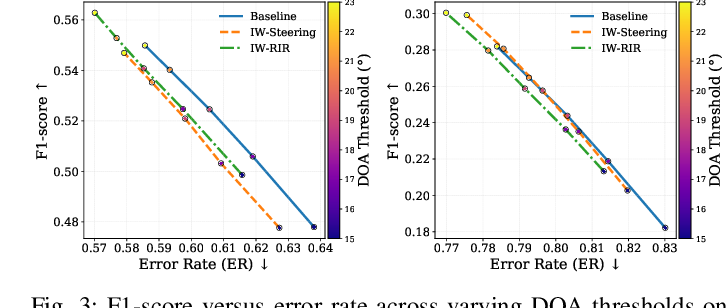
说明在不同 DOA threshold 下,物理正则会改变 F1 和 ER 的权衡。low-data 场景下 IW-RIR 和 IW-Algebraic 仍保持竞争力,说明物理先验在数据不足时更有价值。
结论
本文提出了一种将物理空间先验引入 SELD 训练过程的方法。与直接修改网络结构不同,该方法通过空间协方差矩阵正则项约束模型输出,使预测结果不仅接近标签,也更符合声学传播规律。由于正则项只在训练时使用,推理阶段不会增加额外计算成本。对于当前 SELD 研究来说,这篇论文提供了一个很好的方向:物理先验的价值不仅取决于先验本身,还取决于注入位置。输入层、表示层、注意力层、卷积特征层和训练目标层都可以成为物理先验进入模型的路径。不同路径可能适合不同模型结构和数据条件。