作者:Daniel Aleksander Krause, Archontis Politis, Annamaria Mesaros
时间:2024
来源: IEEE Proceedings
背景
声音事件检测与定位,SELD,通常同时完成两件事:识别“发生了什么声音事件”,以及估计该声音事件的到达方向 DOA。传统 SELD 只给出方向信息,例如方位角、俯仰角或三维方向向量,但不能给出声源到麦克风/听者的距离。在机器人听觉、智能监控、增强现实、助听设备、人机交互等应用中,仅知道方向并不够,还需要知道声源在三维空间中的完整位置。以往声音距离估计,SDE,研究多与双耳音频或单独定位任务结合,较少与声音事件检测、DOA 定位统一建模。因此,本文将 SELD 扩展为 3D SELD:同时进行声音事件检测、方向定位和距离估计。
核心贡献
- 提出 3D SELD 任务定义:在原有 SELD 的事件类别与 DOA 估计基础上,加入距离估计,使系统能够估计声源三维位置。
- 提出 Multi-ACCDDOA 表示:在 multi-ACCDOA 的基础上,把原本的三维 DOA 向量扩展为包含距离的输出表示。
- 比较两种建模方式:一种是多任务结构,分别输出 SELD 与距离;另一种是单任务的 Multi-ACCDDOA 结构。
- 比较不同损失函数:针对距离估计部分实验 MSE、MAE、MSPE、MAPE,分析距离损失对 SELD 性能和距离误差的影响。
方法
- 输入特征:
- Ambisonics/FOA:使用 4 通道幅度谱转换为 64 维 Mel 能量,并加入 3 个强度向量特征,总计 7 个特征通道。
- Binaural:使用双耳平均幅度谱,并加入 IPD 的 sine/cosine 表示和 ILD,总计 4 个特征通道。
- STFT 设置:40 ms Hamming 窗,50% overlap;每个输入片段长度为 250 帧。
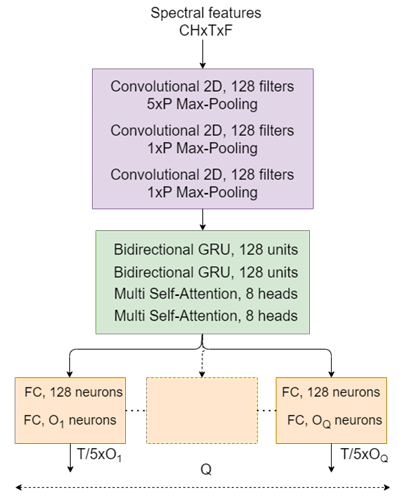
- 模型结构:
- 使用 CRNN 架构:3 个二维卷积块 + 2 层双向 GRU + 2 层 Multi-Head Attention。
- 每个卷积块含 128 个卷积核、BatchNorm 和池化。
- 最后通过全连接层输出事件类别、方向和距离相关信息。
- 方法一:Multi-task
- 分成两个输出分支。
- 第一个分支使用 ACCDOA 表示完成 SELD,即事件活动与 DOA 向量耦合。
- 第二个分支单独预测每个类别的距离。
- 优点是结构直观,距离估计与 SELD 可分开优化。
- 缺点是不能区分同一类别中多个重叠声源。
- 方法二:Multi-ACCDDOA
- 将 multi-ACCDOA 扩展为包含距离的表示。
- 输出形式可以理解为:每个 track、每个类别、每个时间帧同时预测事件活动、DOA 向量和距离。
- 支持最多 3 个重叠声源,并可处理同类重叠事件。
- 使用 ADPIT,即 Auxiliary Duplicating Permutation Invariant Training,解决 track 与真实声源之间的排列匹配问题。
实验
- 数据集:STARSS23,Sony-TAU Realistic Spatial Soundscapes 2023。
- 真实录音规模:7 小时 22 分钟;训练集 90 个 clips,测试集 78 个 clips。
- 类别数:13 类,包括男女说话、拍手、电话、笑声、家庭声音、脚步、门声、音乐、乐器、水龙头、铃声、敲击等。
- 重叠情况:最多 3 个同时存在的声源。
结果
论文分别在 Ambisonics/FOA 音频和 Binaural 双耳音频上进行了实验,并比较了两类方法:Multi-task 和 Multi-ACCDDOA。评价指标包括声音事件检测错误率 ER、F1 值、DOA 定位误差、定位召回率 Recall,以及距离估计误差 Dist. error。

在 Ambisonics 音频上,整体效果最好的是 Multi-ACCDDOA + MSE,其结果为:ER = 0.65,F1 = 44.2%,DOA error = 22.9°,Recall = 68.4%,距离误差为 0.92 m。相比之下,Multi-ACCDDOA + MAE 虽然取得了最低的距离误差 0.74 m,但 F1 下降到 21.5%,Recall 也下降到 19.1%,说明 MAE 会明显损害事件检测和定位性能。

在 Binaural 音频上,整体性能低于 Ambisonics。最佳综合结果仍来自 Multi-ACCDDOA + MSE,其 ER = 0.87,F1 = 21.1%,DOA error = 39.7°,Recall = 48.0%,距离误差为 0.99 m。Multi-ACCDDOA + MAE 的距离误差最低,为 0.75 m,但 F1 仅为 5.4%,检测性能严重下降。
结论
本文证明了在不明显损害原有声音事件检测和 DOA 定位能力的情况下,可以把距离估计加入 SELD,形成 3D SELD。Multi-ACCDDOA 比简单多任务结构更有优势,因为它支持同类重叠声源,并在整体 SELD 指标上表现更好。但距离估计和 SELD 的最优损失函数并不一致:MSE 有利于 SELD,MAE 有利于距离估计。未来工作可以设计混合损失函数,兼顾 SELD 的稳定性和距离估计精度;也可以结合 Multi-ACCDDOA 的 track-wise 表示与多任务输出结构。