- 作者:Haoran Luo 等
- 发表单位:北京邮电大学、南洋理工大学、新加坡国立大学、中国移动研究院等
- 发表在:NeurIPS 2025
核心内容
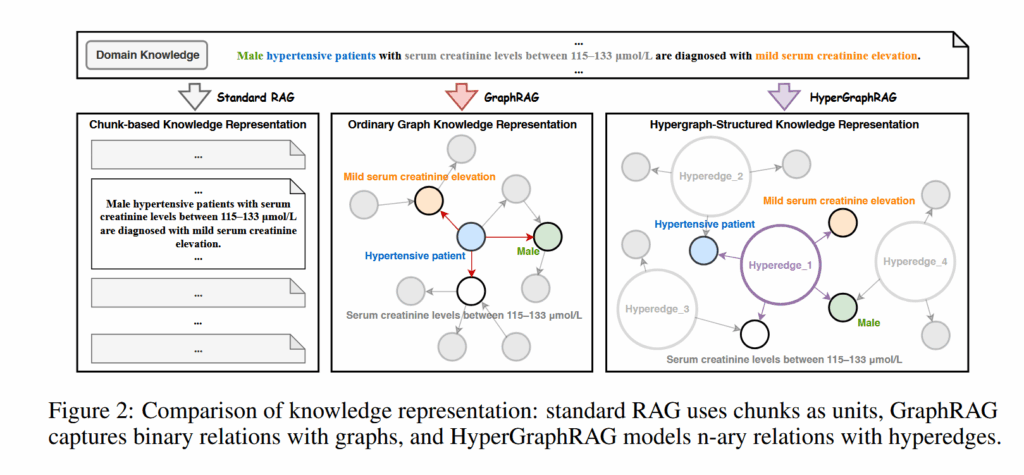
本文主要围绕 GraphRAG 里的一个问题展开:普通图只能表示二元关系,但是现实里的很多知识其实是多个实体一起构成的,比如医学指南、法律条文这种,很多条件必须放在一起才成立。
所以作者提出了 HyperGraphRAG,用超图来做 RAG。它的核心想法是把一个多实体事实表示成一个超边,而不是拆成很多三元组。这样可以尽量避免 GraphRAG 在拆分复杂事实的时候把信息拆碎。
论文的贡献大概有三个:第一,指出普通 GraphRAG 的二元边表示不够;第二,提出了一个超图结构的 RAG 框架;第三,在医学、农业、CS、法律等领域做了实验,证明效果比 StandardRAG 和一些 GraphRAG 方法更好。
整体来说,这篇文章的重点不是“推理方法多复杂”,而是它把问题放在了知识表示粒度上。
背景
传统 RAG 基本是 chunk 检索,优点是简单,缺点是结构太弱。后来 GraphRAG 引入了图结构,可以显式表示实体和关系,听起来更适合知识密集型任务。
但是 GraphRAG 也有一个问题:普通图的边一般只能连两个实体,也就是偏二元关系。可是很多真实知识不是这么简单的。比如“男性高血压患者在某个肌酐范围内会被诊断为什么”,这里面性别、疾病、指标范围、诊断结论是绑定在一起的。
如果把它拆成多个二元边,就会出现一种问题:每条边本身都对,但是组合条件可能丢了。于是模型检索到这些东西之后,还得自己把它们重新拼起来,这就容易出错。
这篇文章就是在这个背景下提出的:与其把复杂事实拆碎,不如直接用一个超边把它们整体保存下来。
技术方法
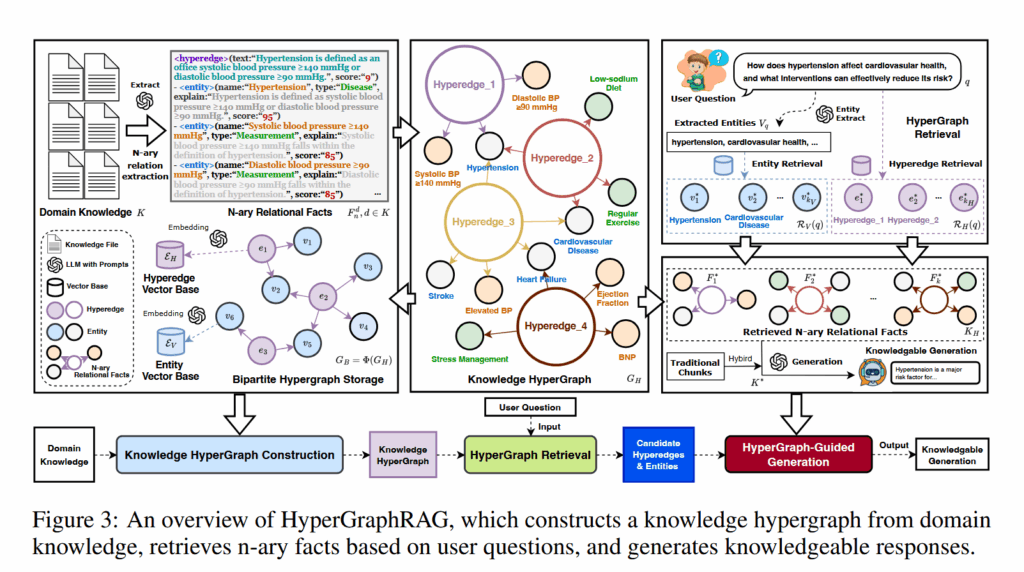
论文的方法主要包括三个部分:知识超图构建、超图检索、超图引导生成。
- 构建知识超图:
用 LLM 从原始文本里抽取知识片段,每个片段作为一个 hyperedge。然后再从这个 hyperedge 里抽实体,包括实体名、类型、解释、分数等。 - 存储方式:
它没有真的搞一个特别复杂的超图数据库,而是把超图转成二部图存。一边是实体节点,一边是超边节点,实体和对应的超边连起来。这样比较工程友好,普通图数据库也能做。 - 检索方式:
查询来的时候,先从问题里抽实体,然后做 entity retrieval 和 hyperedge retrieval。之后再做扩展:从实体找到相关超边,从超边找到相关实体。 - 生成方式:
最后它不是只用超图知识,还会把传统 chunk 检索的内容一起放进去,让 LLM 生成答案。这个设计还挺稳的,因为超边保结构,chunk 保原文上下文。
整体来看,它的方法其实不复杂,关键是把“检索单位”从 chunk / 二元边换成了更完整的 n 元事实。
实验
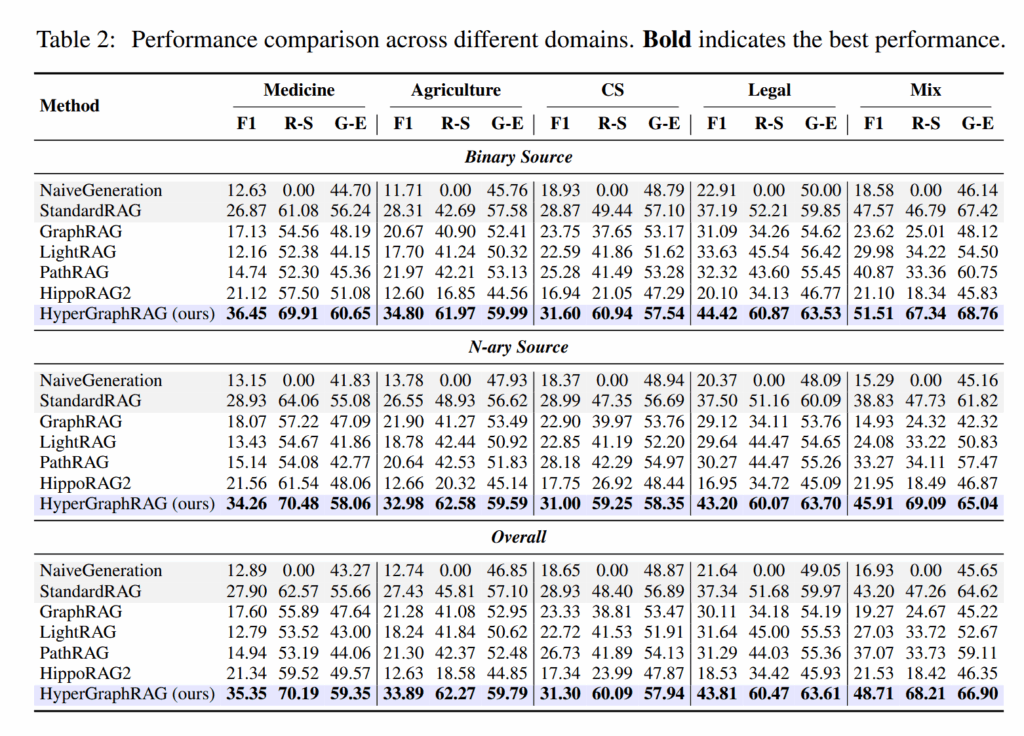
实验用了 Medicine、Agriculture、CS、Legal、Mix 五个领域。baseline 包括 NaiveGeneration、StandardRAG、GraphRAG、LightRAG、PathRAG、HippoRAG2。
指标包括 F1、Retrieval Similarity 和 Generation Evaluation。实现上,抽取和生成用 GPT-4o-mini,embedding 用 text-embedding-3-small。
结果上,HyperGraphRAG 基本都赢了。比较有意思的是,一些 GraphRAG 方法反而不如 StandardRAG,这说明“变成图”不一定天然更好,如果图结构把知识拆碎了,可能还会影响检索和生成。
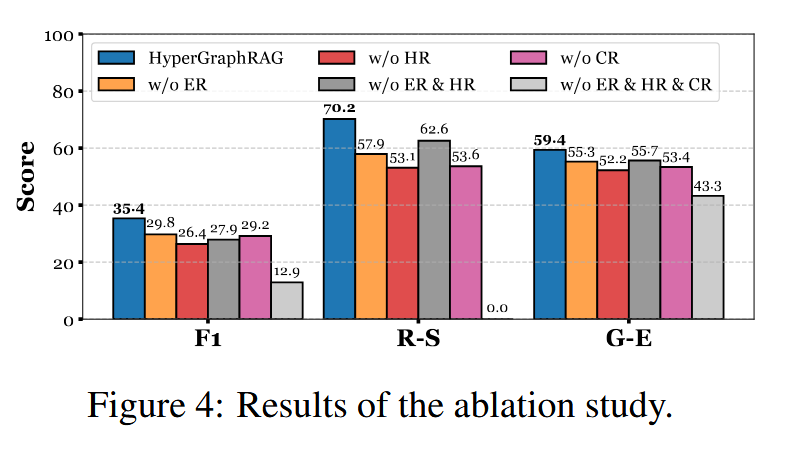
消融实验也比较符合直觉:去掉实体检索、超边检索、chunk 融合都会掉点,其中去掉超边检索掉得比较明显。这说明它的提升确实和 hyperedge 有关系,不完全是 chunk retrieval 带来的。
效率方面,它比 StandardRAG 更贵,但是比一些复杂图方法还算可接受。感觉属于“成本增加一点,但是表示能力确实更强”的路线。
结论
- 本文提出了 HyperGraphRAG,主要解决 GraphRAG 在复杂多实体事实表示上的问题。它认为普通二元边会把知识拆碎,而超图可以更完整地保留 n 元事实。
- 实验说明,知识表示方式会直接影响 RAG 的检索和生成效果。不是用了图就一定更好,关键还得看这个图能不能保留事实本身的结构。
- 总体来看,这篇文章的意义在于把 GraphRAG 的问题从“怎么检索”往前推了一步,变成“知识应该怎么表示”。但它还没有真正解决证据之间的逻辑关系,比如冲突、适用性、前提、抑制这些问题。
启发与评价
- 方法创新点【n 元事实表示】:
这篇的点还挺清楚,就是普通 KG / GraphRAG 用二元边不够,所以换成 hyperedge。这个对于复杂规则、医学指南、法律条文这种确实有意义。不过它的 hyperedge 本质上还是自然语言片段,并没有真的把逻辑关系拆得特别细。 - 技术目标点【复杂知识结构化召回】:
它更像是在做“事实级别的结构化召回”,解决的是一个事实内部多个实体怎么绑定的问题。和 PG-LLM 可以区分开:它管的是事实内部结构,PG-LLM 更应该强调事实之间的支持、冲突、前提和适用性推理。 - 中试产品点【食养通】:
这个方法对食养通其实挺适合。比如“高血压人群 + 高钠食品 + 摄入限制 + 风险提示”这种就很像 hyperedge。但是如果要做个性化建议,只靠 hyperedge 还不够,还得判断这条知识对当前用户到底适不适用,所以更像是可以和命题图/PG 推理结合起来用。