作者:Tong Chen、Hongwei Wang、Sihao Chen、Wenhao Yu、Kaixin Ma、Xinran Zhao、Hongming Zhang、Dong Yu
来源:EMNLP
单位:华盛顿大学、腾讯人工智能实验室、宾夕法尼亚大学等
发表日期:2024.11
论文介绍
背景动机:
检索单元的设计选择长期被忽视:现有密集检索研究多聚焦于模型架构与训练策略,而对推理阶段语料库索引粒度的选择缺乏系统性探讨。
传统粒度存在固有缺陷:段落粒度包含过多无关细节,易干扰检索器与语言模型;句子粒度虽更细但常因指代缺失而无法独立表达完整语义。
检索增强生成面临上下文瓶颈:大语言模型受限于上下文窗口长度,需要在有限 token 预算下提供更高密度的问题相关信息以提升生成质量。
研究目标:
旨在系统性地研究密集检索推理阶段中检索语料库的索引粒度对检索性能及下游任务的影响。作者提出以”命题”(proposition)作为新型检索单元,即文本中表达单一事实、简洁且自包含的原子化表述,并通过实验验证该粒度在段落检索任务和检索增强问答任务中相较于传统段落或句子粒度的优势。
核心内容
实验评估
论文总结
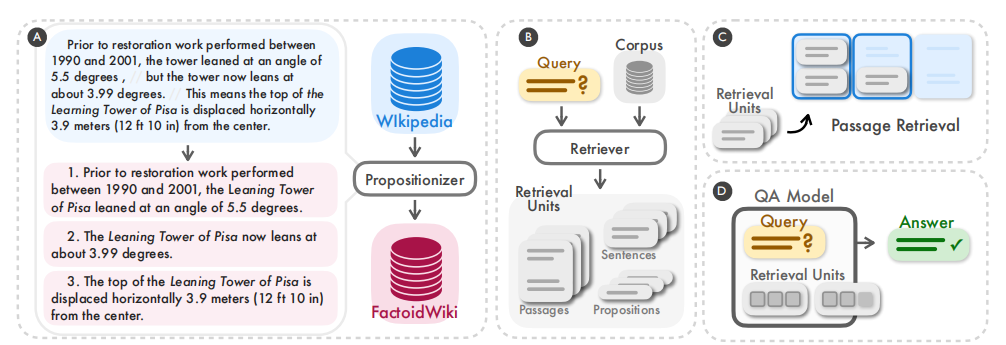
核心方法:提出将命题作为密集检索的新粒度单元,替代传统段落或句子。命题是文本中原子化、自包含的语义表达。作者通过 GPT-4 蒸馏微调 Flan-T5 训练 Propositionizer 模型,将维基百科分解为 2.57 亿条命题,构建 FACTOIDWIKI 语料库。
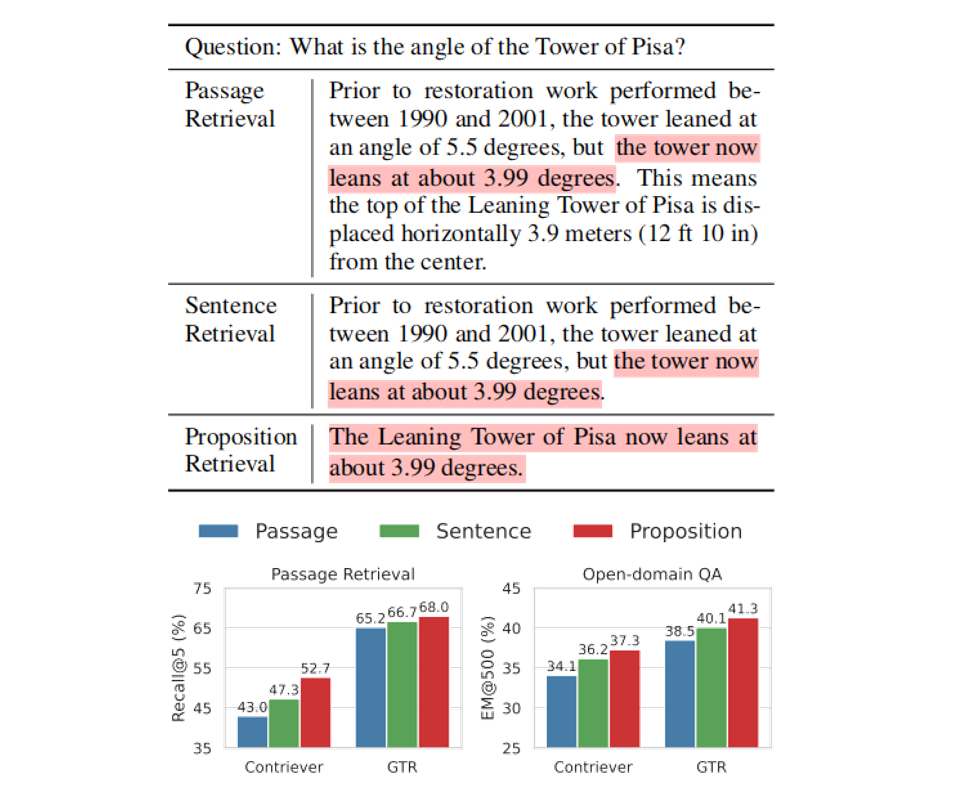
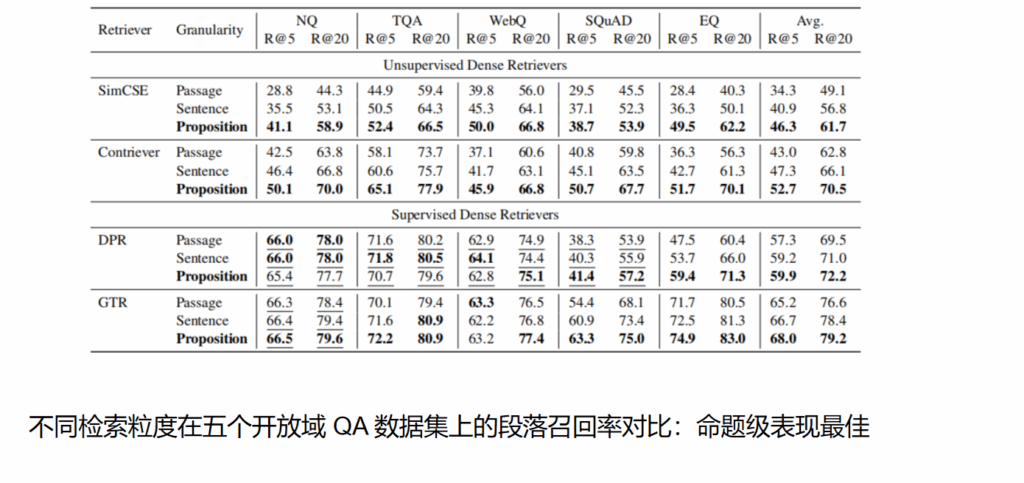
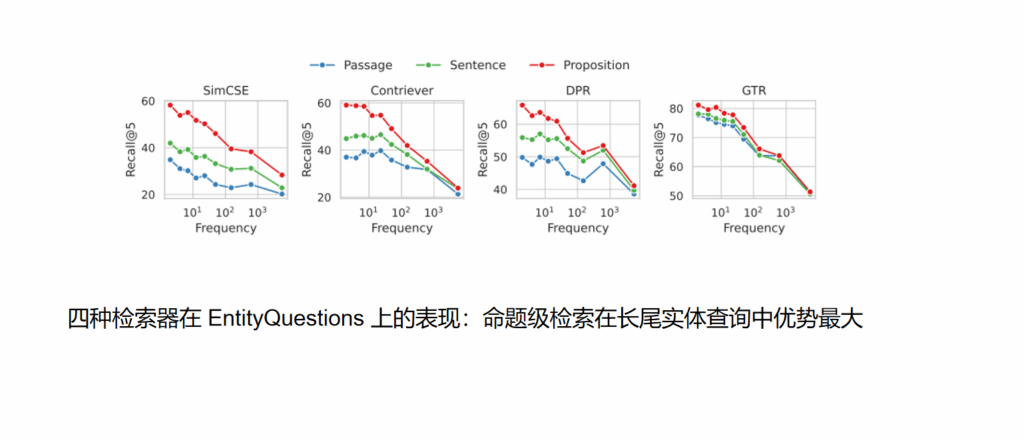
实验结果:在 NQ、TriviaQA、WebQ、SQuAD、EQ 五个开放域问答数据集上,采用 SimCSE、Contriever、DPR、GTR 四种检索器验证。结果表明,命题级检索全面优于段落与句子级,无监督检索器 Recall@20 平均提升 +10.1,且在 LLaMA-2-7B 下游问答中取得最佳表现。优势主要源于长尾实体查询与跨任务泛化场景,EQ 数据集 Recall@5 相对提升达 25%。
优势总结:该方法无需修改检索模型参数,仅通过调整索引粒度即可显著提升性能,具有简洁性与正交性。命题作为原子化语义单元,在固定上下文预算下提供更高的问题相关信息密度,有效缓解大模型上下文受限问题。
启发思考
1.1技术创新-逻辑思维推理框架:提出将命题(Proposition)作为检索基本单元,替代传统段落或句子。命题被定义为文本中的原子化表达,具有三个特性:对应独立语义事实、最小不可再分、上下文化且自包含(代词被解析为完整指代)。作者通过 GPT-4 蒸馏微调 Flan-T5 得到 Propositionizer,构建了 FACTOIDWIKI 命题级语料。这说明检索粒度本身是一个被忽视的关键变量,需通过原子化结构强化关键信息建模。
2.1技术目标-专业手册公共服务:可引入命题级检索增强机制(RAG),将专业文档分解为命题单元建立跨文档索引,使模型能在多份专业文档间进行证据检索与关系推理,服务于专业知识抽取场景。
3.1场景功能-食养通:将食养文档(成分百科、功效文献、人群手册)分解为原子命题;通过密集检索召回高密度相关证据;再交由 LLM抽取”成分—功效—适用人群”三元关系。