作者: Adam Jankelow, Anastasia Godneva, Michal Rein, Dorit Samocha-Bonet, Daphna Weissglas-Volkov, Shahar Zohar, Tal Shor, Eran Segal 等
单位: Pheno.AI、Weizmann Institute of Science、Garvan Institute of Medical Research、UNSW Sydney、Mohamed bin Zayed University of Artificial Intelligence 等
来源: npj Digital Public Health
时间: Received: 2025.06.08;Accepted: 2025.08.20;Published: 2026
链接:[NutriMatch: harmonizing food composition databases with large language models for enhanced nutritional prediction]
一. 研究背景
在食品营养分析里,有一个非常基础但又很容易被忽略的问题:不同食品成分数据库之间并不统一。
我们平时做食品健康度评价、饮食记录分析、营养预测或者个性化饮食推荐时,往往默认食品成分数据库是可靠且完整的。但真实情况是,食品成分数据库,也就是 FCDB,通常存在很多问题:
- 不同国家和地区的食品名称不一致;
- 同一种食品在不同数据库中的分类方式不同;
- 有些数据库只包含基础营养素,比如能量、蛋白质、脂肪、碳水、钠;
- 微量营养素、脂肪酸、维生素、矿物质等字段经常缺失;
- 不同地区由于土壤、气候、农业方式、食品加工、强化政策不同,同类食品的营养值也可能有差异。
这就导致一个问题:如果底层食品营养数据不完整、不统一,那么后面的健康评分、营养预测、食品性价比分析都会受到影响。
这篇论文提出的 NutriMatch,本质上就是为了解决这个问题。它做了一个更底层的数据增强系统:把不同食品成分数据库中的食品条目对齐起来,再利用相似食品的信息补全缺失营养素。
也就是说,它关注的不是最后一步“怎么预测健康结果”,而是更靠前的一步:
如何让食品营养数据先变得更完整、更统一、更可用。
二. 论文概要
作者关注的问题是 food composition database harmonization,也就是食品成分数据库的协调与统一。这项工作主要解决的是:如何用大语言模型和语义嵌入,把多个国家或地区的食品成分数据库进行自动对齐,并补全缺失的营养成分。
论文提出的方法叫 NutriMatch。它的整体流程可以概括为:食品数据库抽取 → LLM 标准化 → 食品语义嵌入 → 相似食品匹配 → LLM 验证等价性 → 缺失营养值补全 → 下游健康预测
这篇论文中涉及多个食品成分数据库,包括:
- USDA SR Legacy
- USDA FNDDS
- Tzameret,以色列食品成分数据库
- MEXT,日本食品成分数据库
- Bahrain Food Composition Table
- AUSNUT,澳大利亚食品成分数据库
其中,NutriMatch 的关键思路是:如果一个数据库里的某个食品缺少某些营养素,那么可以在其他数据库中找到语义上相似、营养意义上等价的食品条目,再把可信来源中的营养值迁移过来。
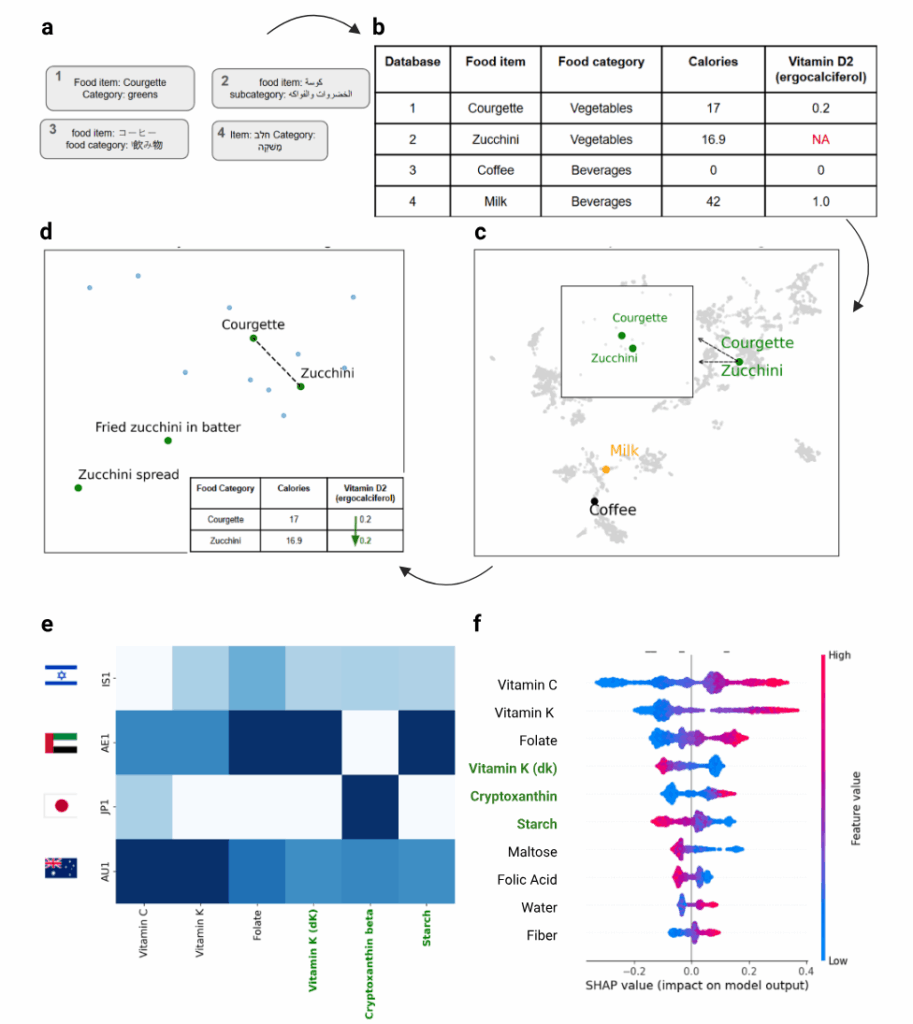
比如论文中的例子是:Courgette ↔ Zucchini
这两个词在不同地区表达不同,但本质上都指向类似食品。系统通过语义匹配发现它们相近,再用 LLM 判断二者是否可以视为营养等价食品,最后用一个食品中的营养信息补全另一个食品中缺失的营养字段。
第 3 页 Figure 1 展示了 NutriMatch 的整体方法框架:先抽取食品名称、类别和营养信息,再通过 LLM 统一结构,随后将食品条目投影到语义空间中,最后通过相似度匹配和 LLM 验证完成营养补全。
三. 方法设计
这篇论文比较有价值的地方在于,它没有简单地让 LLM 凭感觉生成营养值,而是设计了一套比较稳健的流程,其核心步骤包括:
1. 数据标准化
不同数据库的字段、食品名称、食品类别、描述方式都不一样。
因此,作者先使用 LLM 对食品条目进行结构化处理,使不同来源的数据尽可能变成统一格式。这一点非常重要,如果食品名称、类别和描述没有先统一,那么后面的匹配很容易出现错误。例如:
- “zucchini”
- “courgette”
- “fried zucchini in batter”
- “zucchini spread”
这些词都和西葫芦相关,但它们的营养意义并不完全一样。系统不能只靠词面相似度判断,而要进一步理解食品状态、加工方式和类别。
2. 语义嵌入匹配
标准化之后,作者使用 OpenAI 的 text-embedding-3-large 模型,把每个食品条目转换成 3072 维向量。这样,食品之间就可以通过向量距离来比较语义相似度。
论文使用 cosine similarity 计算食品条目之间的相似程度,并为每个待补全食品寻找最相似的候选食品。这一步解决的是如何从多个食品数据库中快速找到可能对应的相似食品。
3. LLM 验证食品等价性
只靠 embedding 找到的相似食品并不一定能直接用于营养补全。
比如:
- 生苹果和苹果派不能直接等价;
- 牛奶和奶昔不能直接等价;
- 普通鸡肉和油炸鸡块也不能直接等价。
所以,NutriMatch 在候选匹配之后,又加入了一个 LLM 判断步骤。LLM 的任务不是生成营养数据,而是判断两个食品条目是否可以认为是营养意义上的等价食品。
它把 LLM 放在了更合适的位置:让 LLM 做语义判断和验证,而不是无依据地编造营养数值。
4. 按数据库可信度补全营养值
当系统确认两个食品可以匹配之后,就可以用外部数据库中的营养信息补全目标食品缺失的营养值。
同时,作者还设计了数据库优先级。例如 USDA SR Legacy 和 USDA FNDDS 这类质量控制更严格的数据库,会被赋予更高优先级。也就是说,系统并不是随便找一个相似食品就补值,而是尽量从更可靠的数据库中选择来源。
这一点对食品智能分析很有意义,因为食品营养值本身就带有测量误差和地区差异。如果补全来源不加控制,反而可能引入新的噪声。
四. 实验结果
论文的实验结果主要说明了三件事:
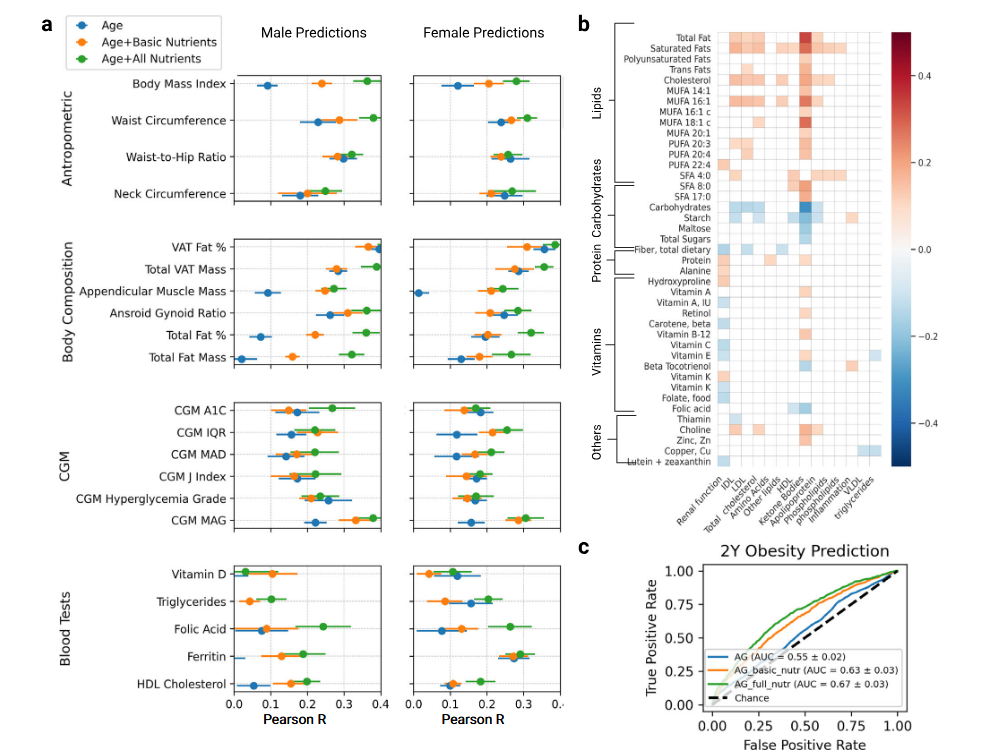
(1)NutriMatch 可以显著扩展食品数据库中的营养字段。
在 HPP 队列中,原始数据库只有 21 项营养素,经过 NutriMatch 处理后扩展到了 151 项营养素。在澳大利亚 PREDICT 队列中,营养覆盖也从 43 项 扩展到了 151 项。这说明 NutriMatch 的主要价值不是单纯提高某个模型指标,而是先把食品营养数据的维度大幅补齐。
可以这样理解:原始食品记录:只有基础营养表。而NutriMatch 之后:形成更完整的食品营养画像
(2)扩展后的营养特征能够提升健康表型预测效果。
论文中比较了三种模型:
- 只使用年龄和性别等基础变量;
- 使用基础营养素;
- 使用 NutriMatch 扩展后的全部营养素。
结果显示,加入 NutriMatch 扩展营养素后,多个健康指标预测效果提升:
- 体脂相关指标;
- 腰围;
- 连续血糖监测指标;
- 血液生物标志物;
- 2 年后肥胖风险预测。
其中,2 年肥胖预测的 ROC AUC 从 0.63 提升到 0.67。这个提升幅度虽然不是巨大跃升,但它说明:更完整的营养数据确实能为下游健康预测提供额外信息。
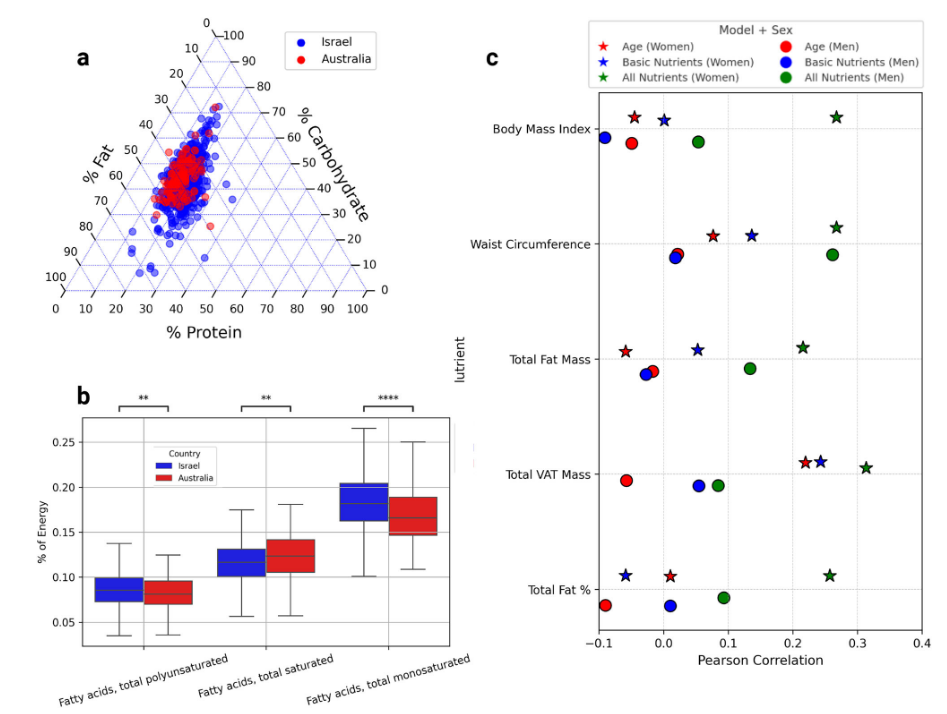
(3)NutriMatch 具有一定跨队列迁移能力。
作者将 HPP 队列中训练得到的模型,直接迁移到澳大利亚 PREDICT 队列中,没有重新训练。结果显示,使用扩展营养素的模型在多个体成分预测任务上依然优于只使用基础营养素的模型。
这说明 NutriMatch 补全出的营养特征不是只对单一地区或单一数据库有效,而是具有一定跨地区、跨人群的泛化价值。这对于真实食品智能系统非常重要。因为现实中的食品数据往往来自多个平台、多个国家、多个数据库,很难保证格式完全一致。
五. 对齐思考
NutriMatch 当前最值得借鉴的地方是:它把食品智能分析的重点前移到了“食品营养数据底座构建”这一层。
很多食品智能分析系统会直接从商品名称、配料表、营养成分表进入健康评分或价格判断。但这篇论文提醒我们:如果底层营养信息本身缺失严重,那么后续模型再复杂,也很容易出现判断依据不足的问题。
这篇论文可以和食品健康度评分 / 识别品类功能 / 推理食品性价比形成比较清晰的连接:
食品名称、配料表、营养成分表输入 → 食品条目标准化 → 多源食品数据库匹配 → 缺失营养素补全 → 完整营养画像 → 健康评分与性价比推理
也就是说,在判断一款食品值不值得买之前,系统可以先做几件事:
- 识别食品品类;
- 标准化商品名称和配料名称;
- 匹配相似食品或同类食品;
- 补齐包装上没有展示的潜在营养信息;
- 建立同类商品的营养基线;
- 再结合价格、净含量、规格、营养密度进行综合判断。
例如,对于一款酸奶产品,包装上可能只给出:
- 能量;
- 蛋白质;
- 脂肪;
- 碳水化合物;
- 钠。
但真正影响健康度和性价比的因素可能还包括:
- 添加糖水平;
- 钙含量;
- 乳蛋白质量;
- 饱和脂肪比例;
- 益生菌或发酵特征;
- 与同类酸奶相比的蛋白质密度;
- 单位价格下能获得多少优质营养。
这些信息未必都能从商品包装中直接获得。因此,NutriMatch 这种“先补全营养画像,再做下游推理”的思路,对食品性价比研究非常有参考价值。