来源: 2026, Knowledge-Based Systems
作者: Hua-Bao Ling, Bowen Zhu, Dong Huang
单位:南方中国农业大学数学与信息学学院
一、论文主要工作
这篇论文提出了一种新的深度聚类方法 (VTCC)。改进:
① 引入了一个具有多个堆叠的小尺寸卷积的卷积茎层来将每个增强的样本图像分割成一系列的块。
② 通过对每幅图像进行两次随机增强以获得两个增强的样本,并将增强的样本的patch向量序列馈送到主干,该主干包含标准Transformer编码器体系结构中的两个权重共享视图。
③ 学习到表征后,通过实例投射和聚类投射进行对比学习,分别研究实例的对比性和全局的聚类结构。
二、模型
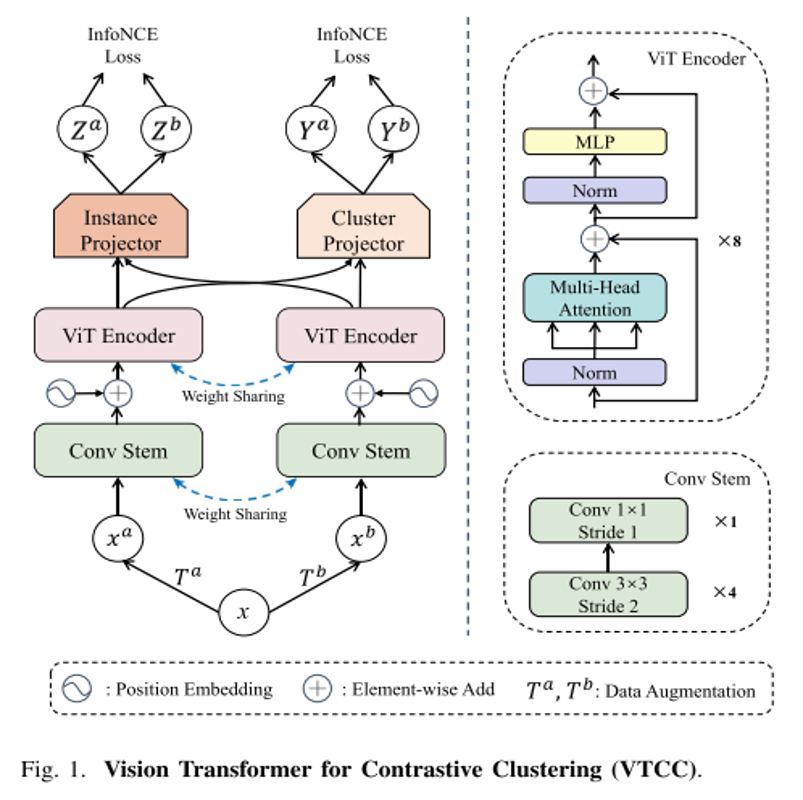
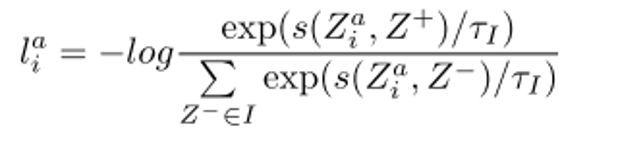
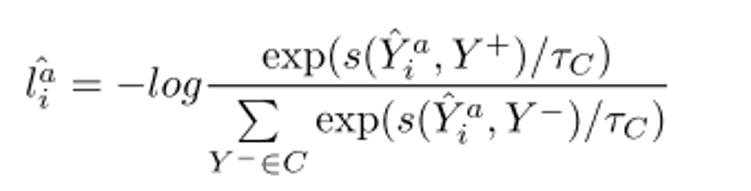
实例级对比学习模块用于最大化正样本对相似度;
全局聚类结构学习模块用于获取图像聚类的软标签预测。
三、实验结果
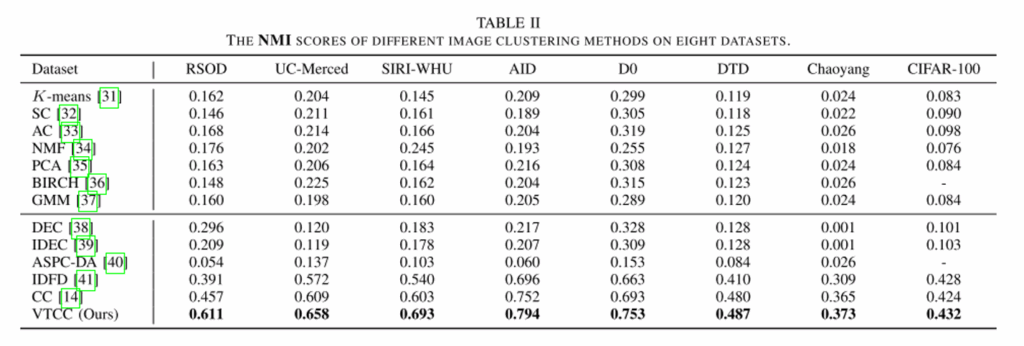
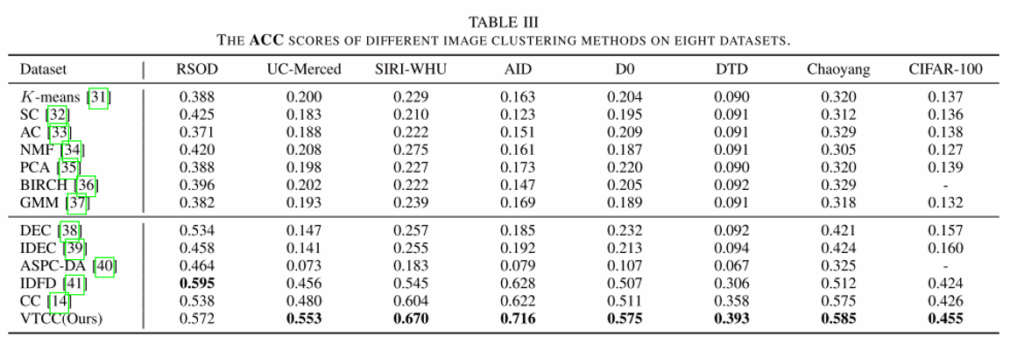
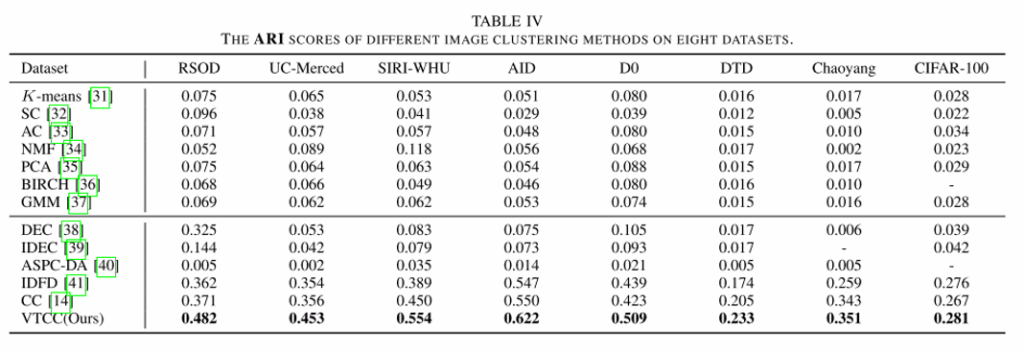
四、总结
课题综合对齐思考:
技术创新—数据拓扑标签计算:这篇研究贡献点在于将对比学习结合进VIT中进行图片聚类,可以为标签计算提供了一个新方法。
技术目标—跨域知识结构对齐:这篇研究并不包含明显的跨域知识结构对齐。
场景功能—食养通:可以用于食物图片的聚类分析。