来源:WWW ’25
作者:JINGTONG GAO、BO CHEN等
单位:香港城市大学、华为诺亚方舟实验室
发表时间:2025 年 4月
研究背景
推荐系统中“重排”的重要性与局限性
单一目标的局限: 传统的重排模型大多只关注准确性(Accuracy)(即推荐用户最可能点击/购买的物品)。虽然准确,但这往往忽略了推荐系统的其他重要维度。
多维度需求的缺失: 在实际应用中,除了准确,我们还需要考虑:
多样性(Diversity): 避免推荐列表全是同质化的物品,让用户看到更丰富的内容。
公平性(Fairness): 确保不同类别或卖家的商品能获得公平的曝光机会,避免算法偏见
大语言模型(LLMs)带来的新机遇与挑战
LLMs 具有强大的语义理解能力:相比于传统模型,LLMs 能更好地理解物品属性和用户偏好之间的复杂语义关系。
语义鸿沟(Semantic Gap): 准确性、多样性、公平性等不同维度之间存在巨大的语义差异,现有模型难以在一个统一的语义空间中同时衡量它们。
缺乏灵活性: 现有的 LLM 应用(如 RankGPT 或 Graph of Thoughts)往往遵循固定的推理路径,缺乏根据“特定目标(Goal)”动态调整推理步骤的能力。
这篇文章提出LLM4Rerank —— 为了解决传统重排模型无法灵活兼顾准确性、多样性、公平性等多重目标的痛点
利用大语言模型强大的语义理解和推理能力,让模型能像人一样,根据用户设定的目标,自动思考并决定如何组合这些不同的重排维度。
主要框架
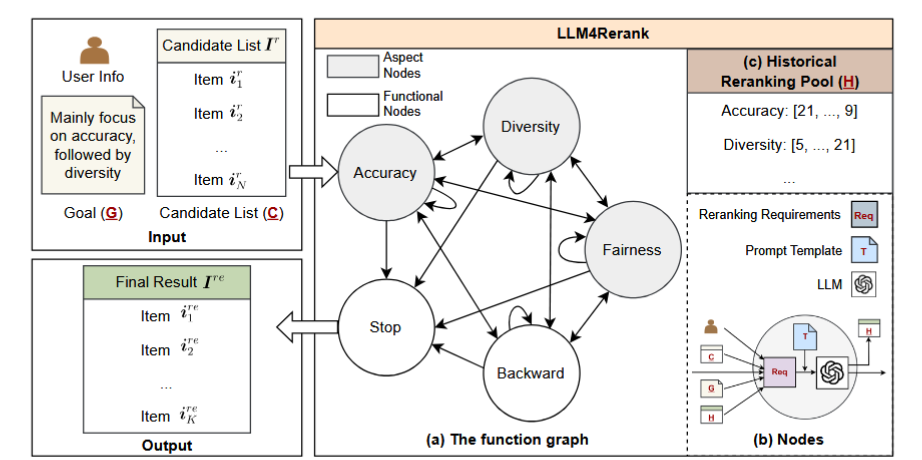
LLM4Rerank将重排问题抽象为一个在函数图上的自动推理过程,通过节点和边来组织不同的重排目标和步骤。
1、输入与输出:
框架接收用户信息、候选物品列表以及一个描述重排目标的“Goal”句子作为输入,最终输出一个经过多维度优化的重排列表。
2、 核心思想:
将不同的重排目标(如准确性、多样性)抽象为图中的“节点”,通过构建一个全连接的“函数图”,让LLM在图上进行自动推理和跳转,逐步优化推荐列表。
3、 关键组件:
框架主要由三部分构成:定义了具体重排任务的“节点”、记录推理过程的“历史重排池”以及指导整个推理方向的“Goal”。
核心组件
1、节点(Node):
代表一个具体的重排步骤,如“准确性重排”、“多样性重排”或“回退”等。每个节点都包含一个特定的提示模板,用于指导LLM完成特定任务。
2、 历史重排池(Pool):
一个用于存储每次节点推理后得到的重排列表的缓存区。它为后续的推理步骤提供了上下文和参考,使模型能够基于历史结果进行更全面的判断。
3、 目标(Goal)
一个由用户提供的自然语言句子,用于定义本次重排的核心关注点。例如,“请优先考虑多样性”或“在保证准确的基础上兼顾公平”。
实验
实验设置
数据集:ML-1M、KuaiRand、Douban-Movie
对比方法:
传统的学习模型:GMF (基础排序), DLCM, PRM (侧重准确性), MMR, FastDPP (侧重多样性), FairRec (侧重公平性)。
LLM基线模型 :RankGPT (侧重准确性), GoT (Graph of Thoughts,固定路径的思维图)。
准确性 (Accuracy):
HR (Hit Ratio): 衡量推荐列表中是否包含用户喜欢的物品。
NDCG (Normalized Discounted Cumulative Gain): 衡量推荐列表的排序质量,位置越靠前权重越高。
多样性 (Diversity):
α -NDCG: 在 NDCG 的基础上引入了多样性惩罚项,用于衡量推荐列表中物品属性的覆盖程度(避免同质化)。
公平性 (Fairness):
MAD (Mean Absolute Difference): 计算不同群体(如长视频 vs 短视频)在推荐结果中的平均评分差异。注意:MAD 值越低越好,代表不同群体曝光越公平。
使用的LLM:Llama-2-13B
总体性能
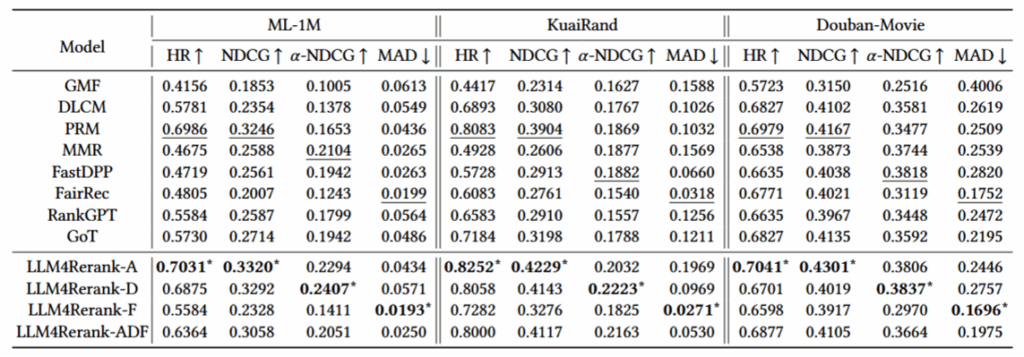
传统的单一目标模型(如只做准确性的 DLCM 或只做多样性的 MMR)往往顾此失彼。
GoT (Graph of Thoughts) 虽然也用了 LLM,但因为是固定路径(Accuracy -> Diversity -> Fairness),表现不如 LLM4Rerank。
消融实验
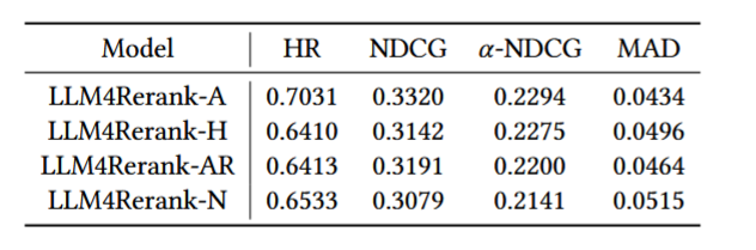
移除历史池(-H):性能出现明显下降。这证明了历史重排池对于模型进行连贯、有依据的推理至关重要,它提供了全局视野。
移除自动推理(-AR):
性能同样大幅下降。这验证了动态调整推理路径的必要性,固定的路径无法应对复杂的、多目标的重排需求。
移除其他节点(-N):
性能下降,尤其是在多样性和公平性指标上。这说明了框架的全面性,丰富的节点类型是实现多维度优化的基础。
总结与综合对齐思考
(一)论文核心内容
这篇论文针对传统重排模型难以灵活兼顾准确性、多样性及公平性等多重目标的难题,提出了一种基于大语言模型(LLM)的自动重排框架(LLM4Rerank)。其核心贡献包括:
动态路径规划机制:摒弃了固定流水线的处理方式,引入包含准确性、多样性、公平性等节点的动态图结构。模型能根据输入目标自动规划最优推理路径,并支持“回退”操作以修正不佳的重排步骤,实现了类似人类的反思与纠错能力。
开源模型驱动的高效重排:框架基于开源的 Llama-2-13B 模型构建,验证了无需依赖闭源 GPT 系列也能实现高性能的重排。实验表明,其推理效率显著优于同类图推理方法(如 GoT),仅增加少量时间成本即可获得性能的大幅提升。
(二)三维度对齐思考
1.0 方法创新点-逻辑思维推理框架
这篇论文摒弃了传统的固定流水线架构,转而采用基于动态图的推理机制。结合自身论文,针对候选食谱的三维度(场景、健康、执行)评估,可以并非简单的顺序执行,而是构建了一个具备自适应能力的决策图,模拟人类“犹豫-思考-决断”的动态路径规划。
2.0 技术目标点-跨域知识结构对齐
构建出高对比比较对:通过框架的检索-排序-LLM推理的pipeline,将高质量的健康候选产品送入比较对推理部分,构建(锚点食谱、候选产品1,候选产品2)的迭代逻辑比选,最终选择出最优食品,这篇论文提出的动态图的推理机制,也启发在比选的时候遇到平局时的额外处理机制。
3.0 中试产品点-食养通
在pk比选这个部分进行应用,针对用户选中的食品,在系统中自动推出结合用户个性化的更健康产品,并展示出对比性解释说明提升推荐效果。