作者:Alejandro Lozano, Scott L Fleming, Chia-Chun Chiang, Nigam Shah
发表期刊:arXiv preprint
发表日期:2023年
一、背景
在医学领域,文献数量的持续激增给临床医生和研究者带来了前所未有的挑战,迫使他们在日常工作中不断更新对最新研究动态的认识。传统的文献检索和综述方法难以满足实时回答临床问题的需求,尤其在有限时间内需要迅速提炼出关键信息的场景下显得力不从心。论文中详细论述了PubMed等数据库中每年涌现的大量文献,强调了医学实践中信息获取延迟所带来的潜在负面影响,进而为开发一种能够自动化、快速且精确从海量文献中整合信息的工具奠定了理论基础和实践需求。
二、创新点
该工作主要贡献在于提出并实现了Clinfo.ai系统,这是第一个公开可用的、基于检索增强大型语言模型(LLM)工作的系统,专门用于回答医学问题。作者不仅通过设计和实现这一端到端系统解决了传统LLM在知识更新和信息溯源上的不足,同时还构建了一个独特的数据集——PubMedRS-200,该数据集以系统综述为金标准,形成了问题和答案的配对,便于对系统进行全面的自动化评估。此项工作在理论上对检索增强技术进行了系统性阐述,在实践中也为医学信息的及时获取和证据整合提供了可复现的解决方案,并为后续研究指明了新的发展方向。
三、架构
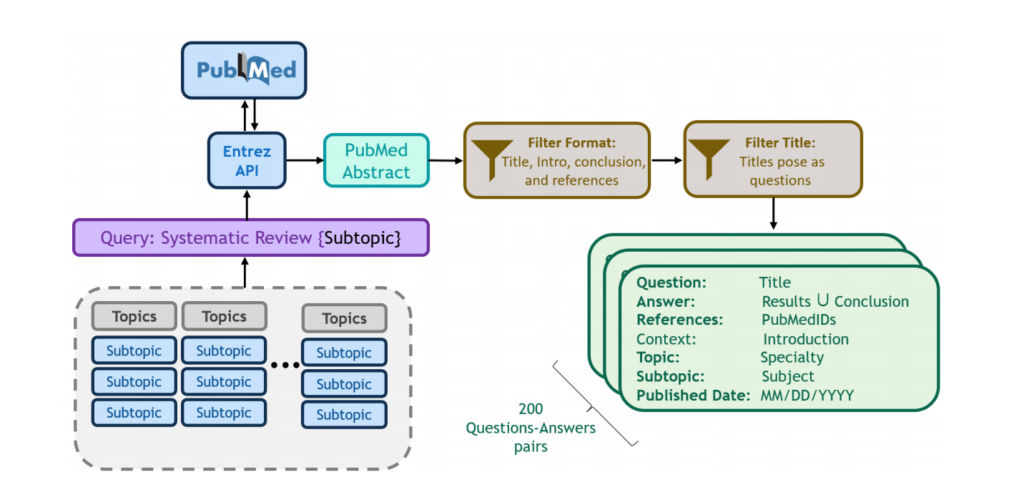

系统架构设计上,Clinfo.ai采用了链式结构,将整个任务分解为多个互相关联的模块,每个模块专注于特定子任务。整体流程从用户提交问题开始,经由查询生成模块构造专门针对PubMed或Semantic Scholar的检索语句,接着通过信息检索和相关性分类模块将大量文献过滤出与问题紧密关联的部分,再通过摘要生成模块提取各篇文章中的关键信息,最后整合成结构化的“Literature Summary”和精炼的“TL;DR”。这种模块化设计不仅确保了系统在处理复杂任务时的灵活性和高效率,同时也大大提高了生成答案的准确性和可验证性,充分利用检索增强技术弥补了传统LLM信息闭塞的劣势。
四、实验设置
在实验设计上,作者构建了一个名为PubMedRS-200的数据集,该数据集包含从系统综述中提取的200个医学问题及其人工精炼的答案,确保评估标准贴近实际应用场景。整个评估框架采用了多维度自动化评价指标,包括源自由(SF)与源增强(SA)两类指标,如UniEval、COMET、BERTScore、ROUGE-L等,系统同时在不同的检索策略下(受限检索、源丢弃和无限制检索)进行测试,保证实验覆盖了多个不同的应用场景。这种全面而细致的实验设置为检验Clinfo.ai在文献提取、摘要生成和信息整合各个环节的性能提供了有力的数据支持,也展示了其在实际临床应用中的潜力和鲁棒性。
五、实验结果

实验结果显示,Clinfo.ai在整体自动评价指标上均优于传统的零样本LLM和其他闭源工具,尤其在TL;DR生成的简洁性与信息一致性方面表现突出。引入检索增强模块后,系统在回答医学问题上能够更准确地反映系统综述中的关键信息,即便在部分原始文献缺失的情况下,仍能生成符合临床需求的精准答案。数据表明,系统在不同评价尺度上的性能提升幅度达到了6.2%至14.9%,这不仅证明了检索增强方法的有效性,也突显了模块化架构在优化信息抽取与整合方面的优势。自动评价指标的多维结果进一步验证了答案的连贯性、事实一致性和语言流畅性,为系统的实际应用提供了坚实的技术保障。
六、总结
论文整体展示了Clinfo.ai系统在医学信息检索与自动文献综述领域的创新性与应用潜力。通过开放平台和可复现的数据集,该工作不仅为医学问题的自动回答提供了一个切实可用的工具,也为未来在检索增强LLM技术上的进一步探索和优化奠定了基础。尽管当前系统还存在如查询生成中偶尔出现虚构术语等问题,但论文中也明确指出了这些局限,并为未来的改进指明了方向。这项工作无论在技术方法上还是在实际应用中都具有重要意义,为临床医生和医学研究者在快速获取和整合信息方面提供了全新的解决方案。