来源:ICML
作者:William Muldrew, Peter Hayess等
单位:UCL伦敦大学学院
发表时间:2024 年 6 月
一、研究背景
LLM与微调:
随着大语言模型(如GPT模型)的能力不断增强,如何使这些模型更好地对齐人类偏好成为一个重要问题。
微调方法如基于人类反馈的强化学习(RLHF)已经广泛应用,但由于计算成本高、超参数敏感且稳定性差,这些方法在实际应用中存在一定的挑战。
直接偏好优化(DPO):
为了解决RLHF的复杂性,最近提出了直接偏好优化(DPO)作为一种更简单且稳定的替代方法。
DPO通过直接优化偏好数据来提高模型的表现,而不需要训练显式的奖励模型或使用强化学习。
这篇论文提出了一种基于DPO的主动偏好学习(APL)方法,通过结合预测熵和偏好模型的确定性来智能选择微调数据,从而提高LLM的学习效率和最终表现。
二、APL方法实现

APL通过以下步骤提高微调效果:
数据获取与微调循环:
APL采用一个迭代数据获取和微调的循环:
在每一步中,首先根据当前模型状态选择一批数据,
然后获取这些数据的偏好标签,最后使用这些标签对模型进行微调。
获取函数:
为了选择最有用的数据进行微调,APL设计了基于模型预测熵和偏好模型确定性的获取函数
主动采样:
通过主动采样策略,模型重点选择那些模型在偏好排序上信心较低或错误的例子进行微调。
三、Acquisition Function方法
- 预测熵:
衡量模型对生成completions时的不确定性。
熵高表示模型对某个输入(提示)的输出可能性不确定,模型在这些数据点上的预测较为分散。
选择熵高的样本有助于聚焦在模型不确定性较大的地方,从而帮助模型进行有针对性的学习。
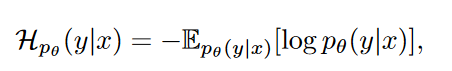
- 偏好模型确定性:
用于衡量模型对于不同完成(y0和y1)的偏好排序的确定性。
确定性高的情况意味着模型对于某个提示下的两个完成有较强的偏好。
模型会优先选择那些隐性奖励差异大的数据点进行标签获取和微调。
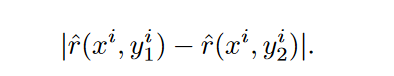
四、实验
1.实验设置
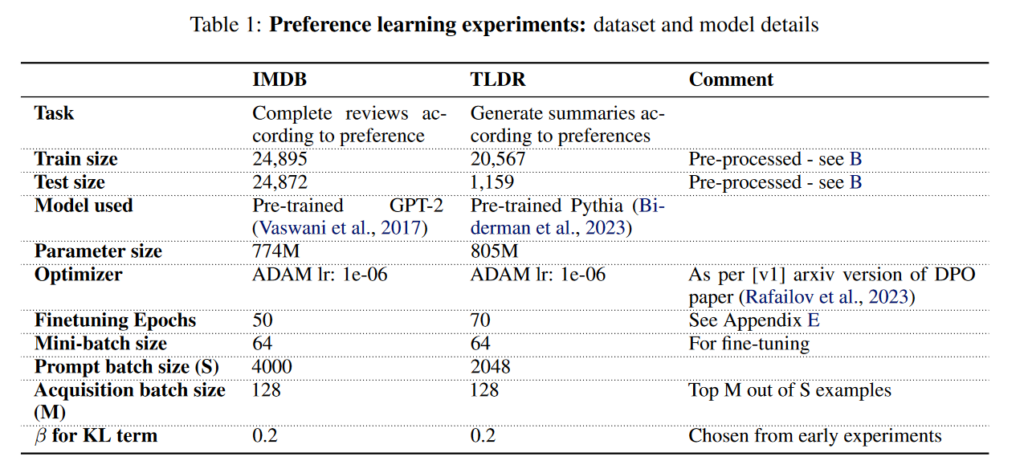
| 名称 | 内容 |
| 数据集 | IMDB 数据集:完成电影评论的生成,模型需要根据给定的提示生成积极的评论。 TLDR 数据集:总结Reddit帖子,生成简短的总结。 |
| 模型选择 | GPT-2(IMDB任务),基于12层、768维度的结构。 Pythia3(TLDR任务),基于16层、2048维度的结构。 |
| 评估方法 | IMDB:与初始预训练模型生成的完成进行比较。 TLDR:与人工生成的总结进行比较。 |
2.数据获取策略
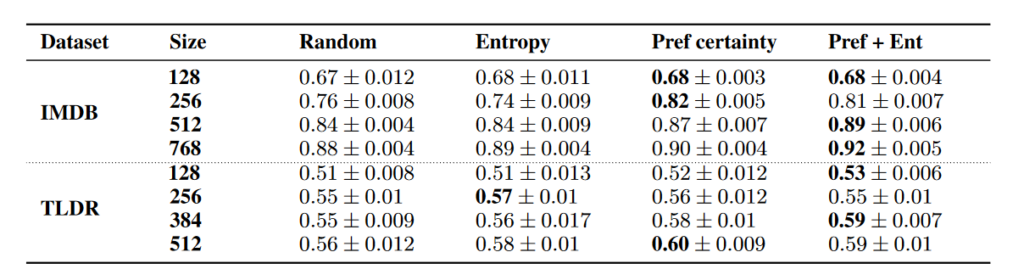
为了评估APL方法的效果,论文设计了四种不同的数据获取策略:
随机采样(Random):从所有可用的提示中随机选择数据进行标签获取。
熵采样(Entropy):基于预测熵选择最具不确定性的提示进行标签获取。
偏好确定性(Preference Certainty):基于模型的偏好排序确定性选择数据进行标签获取。
熵+偏好确定性(Entropy + Preference Certainty):结合熵和偏好确定性选择数据。
3.偏好预测准确性验证
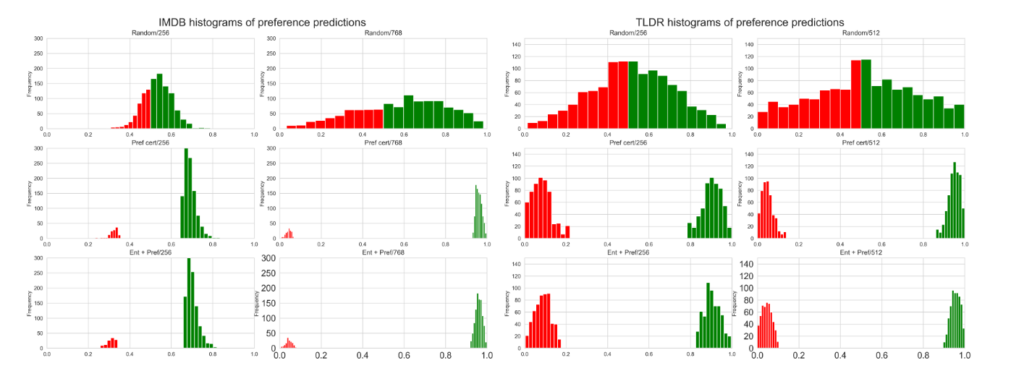
正确预测的频率:柱状图中的绿色部分表示模型预测正确的频率,表示在某一确信度区间内,模型预测的偏好排序与真实的oracle偏好排序一致。
错误预测的频率:柱状图中的红色部分表示模型预测错误的频率,表示在某一确信度区间内,模型预测的偏好排序与真实的oracle偏好排序不一致。
五、总结与综合对其思考
(一)论文核心内容
这篇论文的核心内容集中在提出了一种主动偏好学习(APL)的方法,旨在提高大LLM在偏好对齐任务中的学习效率和最终表现。
该方法通过智能选择最具价值的数据进行微调,减少了标签的浪费,尤其在标签预算有限的情况。
(二)综合对其思考
论文中的获取函数通过选择具有较大偏好排序差异的数据来进行微调,可以利用类似的思想来构建高对比比较对,即选择那些在用户偏好上有显著差异的产品进行比较。
主动学习策略:借鉴APL的思想,通过主动选择最有价值的数据进行训练,提升学习效率。