来源:ICML 2020
作者:Tonghan Wang, Heng Dong, Victor Lesser, Chongjie Zhang
单位:清华大学
一、背景
多智能体强化学习(Multi-Agent Reinforcement Learning, MARL)在许多应用场景中面临巨大挑战,如智能体之间的协作、竞争以及在复杂环境中的策略优化。在多智能体系统中,如何让各个智能体有效协作、合理分工,最大化整体性能是一个核心问题。面向角色的多智能体强化学习(Role-Oriented Multi-Agent Reinforcement Learning, ROMA) 算法正是为了解决这一问题而设计的。
核心思想:ROMA 的核心思想是为每个智能体分配特定的“角色”,使其根据角色选择行动,并在学习过程中优化角色和策略的选择。通过将智能体的行为分解为角色的表现,ROMA 能够有效减少策略学习的复杂性,特别是在复杂的多智能体协作任务中。
二、贡献
提出了一种面向角色的MARL框架(ROMA),将角色概念引入到 MARL 中,并实现代理之间的自适应共享学习。ROMA框架中的智能体角色具有以下特点:
1、动态:角色可以自动适应环境的动态变化;
2、可识别性:角色包含有关其行为的足够信息;
3、专业化:具有相似角色的智能体应该专门从事相似的子任务。
三、方法
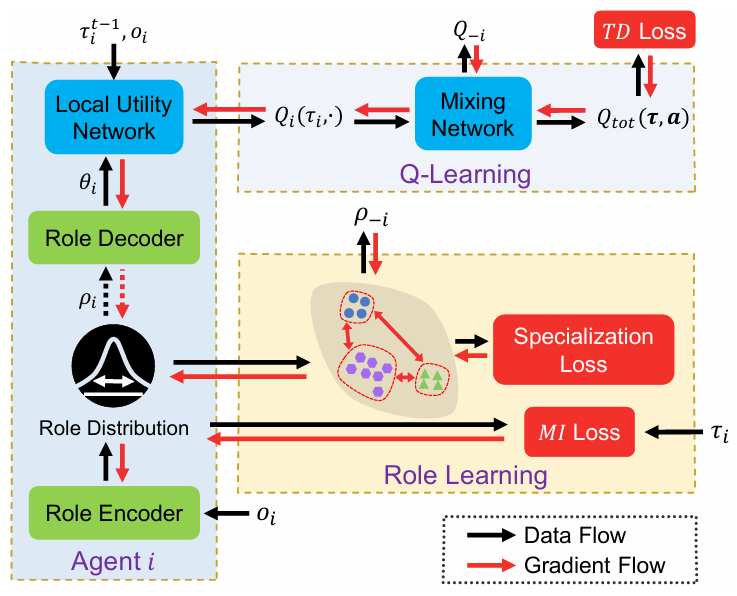
角色编码器生成角色嵌入分布,在其中采样角色信息并将其作为角色解码器的输入。 角色解码器生成本地效用网络的参数,然后输入到混合网络中,以获得全局动作的估计价值Q。
1、使用使用encode-decoder结构:
encoder产生均值和方差,角色ρi 从中采样得到:
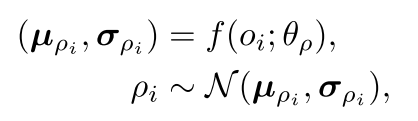
decoder根据角色ρi 产生智能体i 的效用函数。
2、最大化条件互信息I(τi;ρi∣oi),使得角色ρi 可通过轨迹τi 辨认。可转化为最小化如下loss:
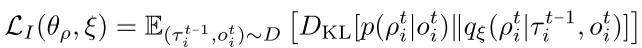
3、提出以下约束,鼓励两个智能体要么有相似的角色(执行相似的任务),要么行为大相径庭:
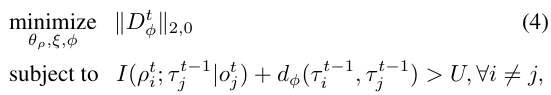
约束中第一项为互信息(Mutual Information),若此项较大,证明智能体i与智能体j角色相似,执行相似的任务。若第二项较大,证明两智能体角色差距较大,则行为应该不相似。
上述最优化问题可转化为优化如下loss:
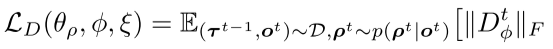
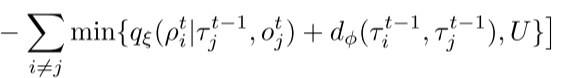
4、最终优化为:
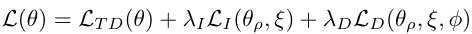
5、执行过程中,只有角色的encoder、decoder和智能体局部效用函数工作。
四、实验
作者针对以下问题做出实验:
1、学习的角色是否能够自动适应动态环境?
2、该方法可以促进子任务专业化吗?即具有相似职责的代理具有相似的角色嵌入表示,而具有不同职责的代理具有彼此相距甚远的角色嵌入表示。
作者通过《星际争霸 II》进行了算法框架的模拟:
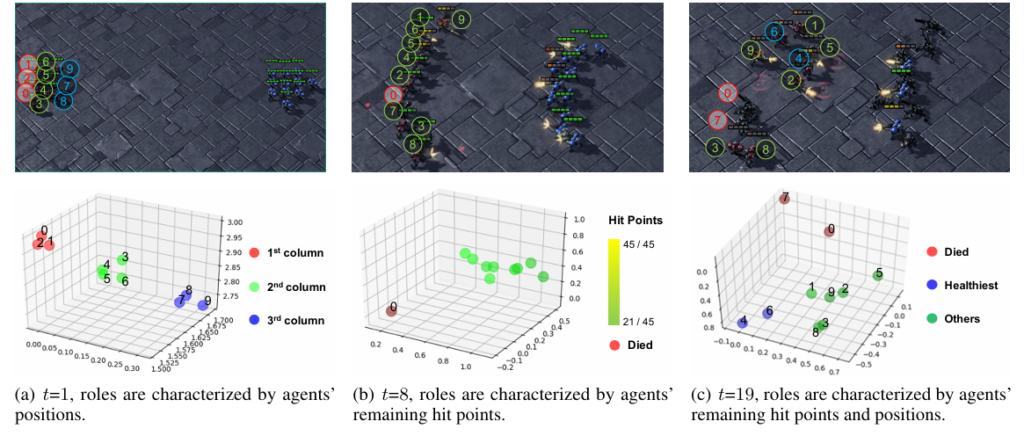
(a)在t=1时快速形成进攻弧线;(b) 当t=8时保护受伤的队友;(c) 保护垂死队友并在t=19时交替射击。
在开始时(t=1),智能体需要形成一个凹弧线,以最大化射击范围覆盖敌人前线的特工数量。 ROMA学习根据智能体的相对位置分配角色,以便智能体可以使用专门的策略快速形成进攻阵型。 在战斗中,一项重要的策略是保护受伤的远程单位。 论文的方法根据剩余的健康点(t=8、19、27)学习此操作和角色集群。 最健康的智能体的角色表征与其他智能体相差甚远。 这种表示导致了不同的策略:最健康的智能体向前移动以承担更多火力,而其他则向后移动,从远处射击。 同时,一些角色也会根据位置进行聚类(当 t=19 时,代理为 3 和 8)。 相应的行为是不同角色的代理交替开火,共享火力。
五、总结与启发
总结:ROMA 通过引入角色的概念,将多智能体强化学习中的复杂性问题分解为角色的分配和策略学习两部分,提升了多智能体系统中的协作效率和适应性。通过动态的角色选择与策略优化,ROMA 在多个多智能体强化学习任务中表现出良好的性能,是一种具有前景的算法。
启发:作者将角色的概念引入到多智能体强化学习中,为智能体分配不同职责,达到更好的协作效果。可以考虑将其扩展到多智能体的对抗性环境中,使得对抗环境更加拟真,对抗双方的协作效果更好。