作者:Vincent Perot, Kai Kang, Florian Luisier, Guolong Su等
期刊:arXiv:2309.10952
单位:Google DeepMind,Google Cloud,Google Cloud AI Research等
发表时间:2024.1
一、背景动机
文档解析挑战大:
半结构化文档布局复杂,涉及文本、空间排列和层次化实体,解析需要上下文和空间信息的结合。
现有方法局限:
- 序列标注方法难以处理层次化实体。
- 序列生成方法无法定位实体且标注成本高。
LLM潜力未充分发挥:
大型语言模型(LLM)具备强大能力,但在视觉文档信息提取中的应用仍存在定位不足和层次化支持不足的问题。
二、核心内容
LMDX通过四个主要阶段——分块、提示生成、LLM推理和解码——实现从视觉丰富文档中高效提取和定位层次化及单一实体。模型概览图如下:
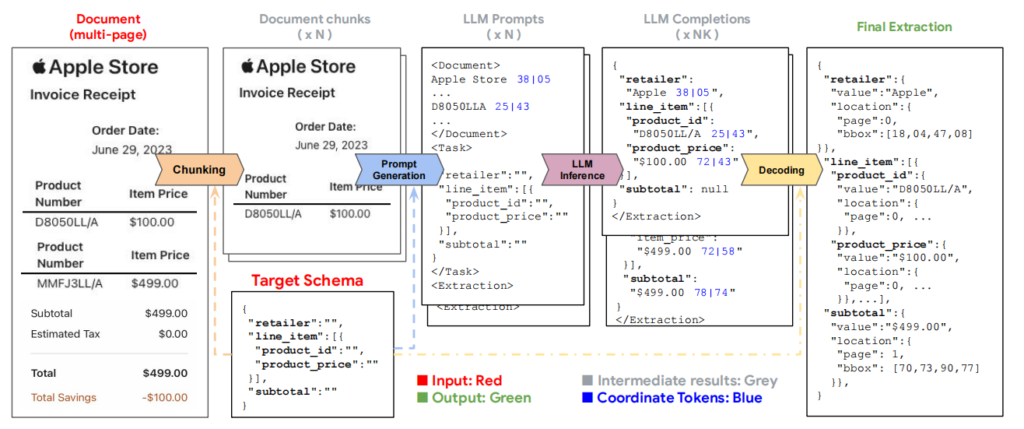
模块 1:分块(Chunking)
- 目的: 将长文档分割成适合LLM处理的小块,以应对其输入长度限制。
- 方法:
- 按页面划分文档为初始块。
- 如果单个块的内容超出LLM的输入限制,逐行移除末尾行段并将其重新组合为新块。
- 确保每块的内容长度均小于LLM的输入限制。
- 优势: 实体通常不会跨页面,因此分块对提取质量的影响最小。
模块 2:提示生成(Prompt Generation)
目的: 为每个文档块生成LLM所需的输入提示。方法:
- 文档表示: 将块内容组织为段文本,并附加坐标标记(如
<文本> XX|YY段),以编码布局信息。 - 任务描述: 简短说明任务目标,例如“提取以下实体的文本值和标签”。
- 目标模式: 用JSON格式描述实体类型及其层次结构。
亮点: 坐标信息嵌入提示中,无需修改LLM架构即可传递文档的布局模态。

模块 3:LLM推理(Inference)
目的: 通过LLM生成实体提取结果。方法:
- 对每个提示进行推理,使用TopK采样生成 K个完成结果。
- 随机采样允许纠正错误(如无效JSON、幻觉坐标)并提高提取质量。
- 使用固定的随机种子保证结果可重复性。
优势: 通过多次采样减少错误,增强模型的鲁棒性。
模块 4:解码(Decoding)
- 目的: 将LLM的输出解析为结构化实体及其文档位置。
- 方法:
- 实体验证: 验证提取的实体是否与原文档匹配,不匹配的实体将被丢弃,防止幻觉。
- 边界框计算: 使用实体的所有文本段计算最小边界框。
- 结果合并: 对每个块的多次推理结果进行多数投票,并在文档级别合并最终预测结果。
- 层次化实体: 通过递归方式解析JSON结构,保留父子关系。
- 亮点: 消除无效实体并确保实体位置的准确性。
三、实验结果
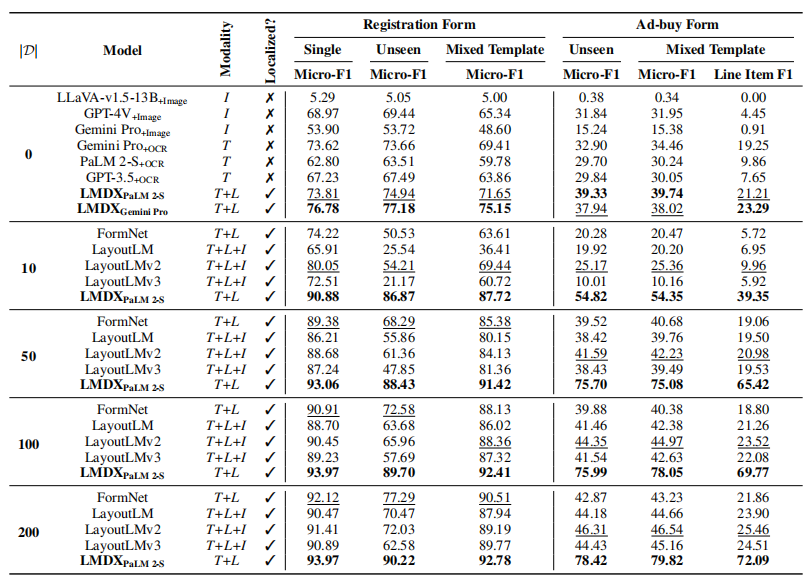
LMDX在文档信息提取任务中表现优异,具备零样本学习能力、高数据效率和精准的实体定位,超越现有方法并在所有基准测试中取得最佳性能。
消融实验

四、总结思考
论文总结
核心方法
LMDX 将任务分为四个阶段:分块、提示生成、LLM推理和解码。通过坐标标记在提示中编码布局信息,无需修改LLM架构。生成的JSON结构化输出支持层次化实体提取与精准定位。
实验结果
- LMDX 在多个数据集(如 VRDU 和 CORD)上取得最佳性能,尤其在零样本和少样本设置下表现出色。
- 相较其他方法(如 LayoutLM 和 FormNet),LMDX 在定位准确率和层次化实体提取方面表现更优。
优势总结
支持零样本和少样本学习。同时提取单一和层次化实体,并提供实体精准定位。数据效率高,性能稳定优于现有方法。
启发思考
1.端到端视觉语言框架:
当前LMDX依赖OCR作为文本和坐标的输入,OCR错误可能影响整体性能。通过端到端整合文本提取、坐标编码和实体提取,可以减少对OCR质量的依赖,同时结合图像、文本和空间布局信息,提升文档理解效果。
2.动态坐标编码机制:
LMDX采用静态量化坐标标记,可能导致精度损失,尤其在复杂文档布局中。引入动态坐标表示,如相对位置编码和注意力机制,可以更精细地建模文本块间的空间关系,提升实体定位的准确性。