作者:Jeong Hun Yeo, Seunghee Han, Minsu Kim, Yong Man Ro
单位:KAIST
来源:arXiv2024
时间:2024年5月14日
一、主要内容
视觉语音处理任务中,由于同唇形音的存在,上下文建模能力是最重要的要求之一。本文提出结合大语言模型的视觉语音处理框架VSP-LLM,通过LLM来最大限度提高上下文建模能力。利用自监督视觉语音模型,将输入视频映射到LLM的输入潜在空间中;针对冗余信息提出重复数据删除方法。重复数据删除和低秩自适应LoRA,VSP-LLM可以以计算高效的方式进行训练。在30小时的标记数据上训练的VSP-LLM可以比在433小时上训练的其他模型更有效地翻译嘴唇运动。
二、方法
包括一个视觉编码器,将输入视频嵌入到预训练的LLM输入空间中,以及一个基于视觉语音单元的重复数据删除模块,以及一个指令嵌入模块。
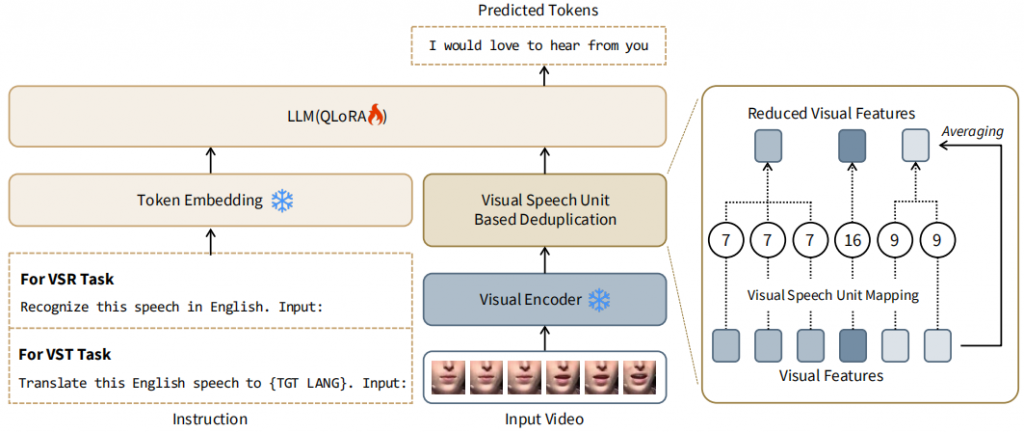
视觉到文本空间映射
AV-HuBERT作为视觉编码器,引入一个可学习的视觉到文本嵌入层,将视觉表示映射到LLM的输入空间中。用视觉表示和LLM标记之间的余弦相似度衡量对齐程度。

由于相邻帧的相似性,视频帧映射到文本时会有冗余信息,增加了计算负载,对此本文提出基于视觉语音单元的重复数据删除方法。
基于视觉语音单元的重复数据删除
对重叠的视觉连续帧,对相应的视觉特征进行平均。与输入的视频长度相比,减少了约46.62%。
带指令的多任务学习
利用LLM的多功能性,用VSR(视觉语音识别)和VST(视觉语音翻译)两个任务来训练提出的VSP-LLM。
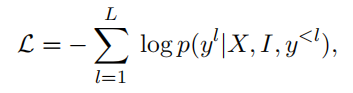
X是输入视频,I是指令,yl是真实值的第l个文本标记,y<l是之前的预测,使用QLoRA来减轻计算负荷。
三、实验
数据集:LRS3(VSR)和MuAViC(VST)
LLM模型使用LLaMA2-7B。
四、实验结果
和sota方法相比
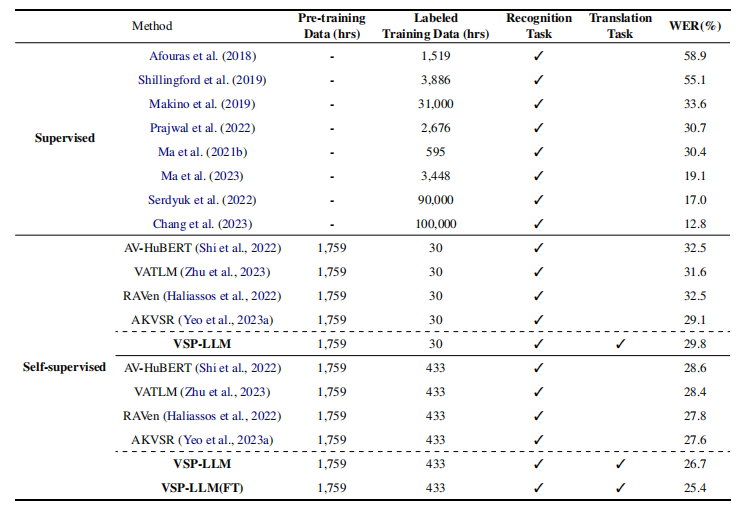
在VSR任务上,提出的通用模型仅用30小时的标记数据就可以获得和几个有监督方法相当的性能。在VST任务上,30小时标记数据训练的模型优于433小时标记数据上训练的双语翻译模型。
LLM模型上下文建模的有效性
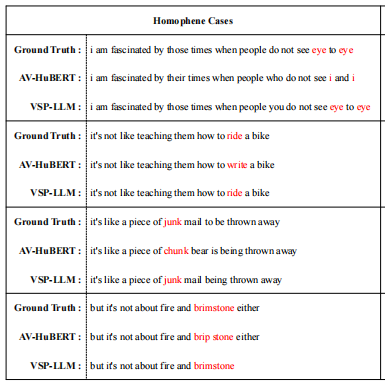
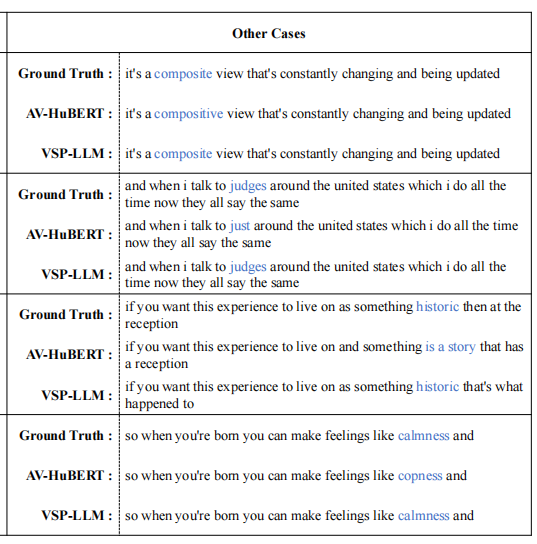
这些结果证实了由于整合了LLM,可以有效地理解上下文线索,并产生更精确自然的答案。
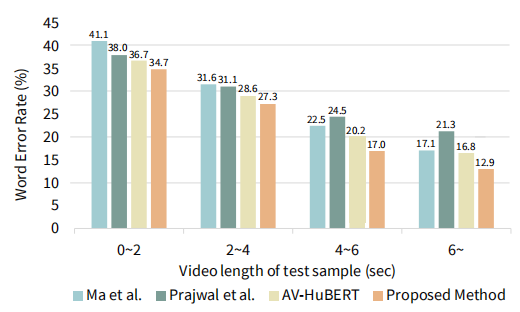
此外,与其他方法相比,本文方法随着视频长度的增加具有一致的性能提高。
重复数据消除的有效性
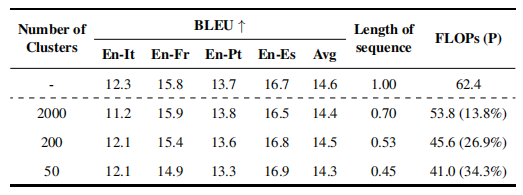
对于200个视觉语音单元的聚类,本文方法不仅保持了相似的性能水平,还减少了53%的序列长度。证实了应用于视觉语音单元的重复数据删除有效地消除了冗余信息。

具有相似嘴唇形状的视觉特征可以被有效地消除重复,显著减少序列长度。
数据有限情况下的VSP-LLM
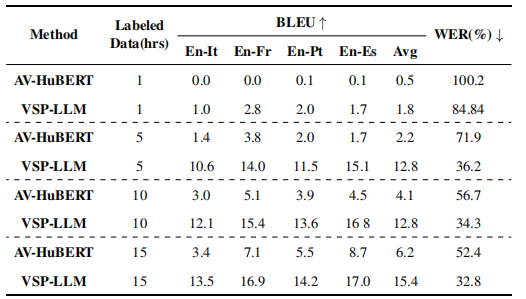
在VST任务中,用不同数量的标记数据训练模型,根据相同的数据开发了AV-HuBERT。无论使用的数据量如何,VSP-LLM都显著优于AV-HuBERT。
五、总结
提出一个新的视觉语音处理框架,旨在利用LLM的上下文建模能力。通过这个框架构建了一个统一的模型,执行VSR和VST。