作者:Yusheng Liao, Shuyang Jiang,Yanfeng Wang,Yu Wang.
单位:Shanghai Jiao Tong University,Fudan University,Shanghai Artificial Intelligence Laboratory.
来源:arXiv:2406.17484
一、论文介绍
背景动机:
医疗任务分为知识密集型任务和对齐需求任务。以前的方法要么忽略了后一项任务,要么只关注少数任务,导致泛化能力不足。而对齐任务通常与模型的原始训练范式有很大的不同程度的偏差,这可能导致幻觉和预训练知识的混叠。因此,本文提出的MEDCARE,旨在保留通用领域LLMs能力的同时,实现特定任务的专业对齐。
微调策略:
MEDCARE的微调过程包括两个阶段:杂项知识聚合(MKA)和下游对齐(DA)。
本文提出了一个渐进式微调管道,该管道采用知识聚合器(KA)和噪声聚合器(NA)。
在第一阶段对各种知识进行编码,并过滤掉有害信息。在第二阶段,本文放弃了NA以避免次优表示的干扰,并利用一个额外的对齐模块,该模块优化为与知识空间的正交方向,以减轻知识遗忘。
二、核心内容
MEDCARE框架
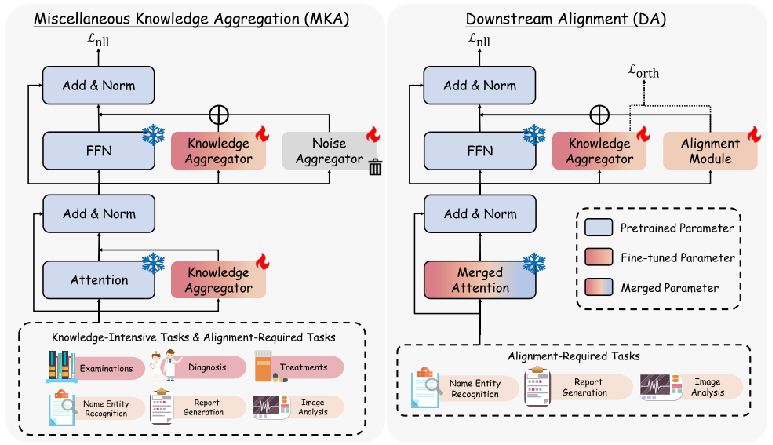
杂项知识聚合(MKA):
在这一阶段,模型从两种类型的任务中获取常见的医学知识。为了不受干扰地将各种知识注入到单个LLM中,本文采用了MoLoRa结构作为NA,并引入共享专家作为KA,以进一步规避由于每个专家的高度专业化和模型的FFN模块上的参数冗余而导致的低泛化。通过反向传播,KA从多个数据集获取常识,而NA学习不同的比对所需任务。因此,KA吸收在每个任务中编码的公共知识,而NA学习干扰对齐要求。
下游任务对齐(DA):
在这个阶段,MEDCARE将自我注意力LoRA权重重新合并到预训练模型中,并冻结自我注意力模块,以保证LLMs的指令跟随能力。在 FFN 模块中引入了一个额外的对齐 LoRA 模块 Align(·),以从对齐数据集中获取特定的对齐知识。同时引入了正交损失,以确保新的对齐任务是在与原始知识任务正交的方向上学习的。
MoLoRA(Mixture of Low-Rank Adaptation):
MoLoRA是一种参数高效的微调技术,旨在优化大型语言模型,特别是在计算资源有限的情况下。它结合了混合专家(MoE)和低秩适应(LoRA)的概念,以提高模型性能,同时保持较低的计算成本。
MoLoRA线性层可以表述为:

三、实验评估
知识密集型任务
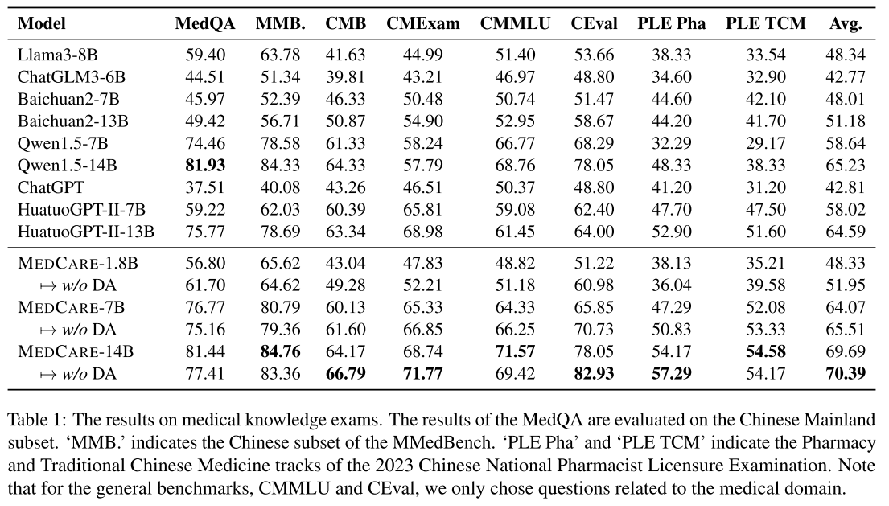
对齐需求型任务

四、总结思考
论文总结:
1、MKA阶段提高了模型的知识能力,DA阶段使模型适应了目标格式。
2、知识聚合器主要从微调语料库中获取常识,而噪声聚合器则更侧重于学习对齐格式。
3、虽然在第一阶段的微调之后放弃噪声聚合器会降低模型的对齐性能,但通过使用第二阶段的下游对齐重新训练模型,可以更快地学习目标格式。随着更多第二阶段对齐数据的添加,模型的对齐能力显着提高,而不会影响其知识容量。这表明,微调过程的第二阶段主要帮助模型与格式保持一致,而不是学习新知识。
启发思考:
1、将复杂任务分类,并为每类任务设计特定的优化策略,可以提高模型在各类任务上的表现。
2、两阶段微调管道(MKA和DA)显示了在平衡知识维护和任务对齐方面的优势。
3、通过引入知识聚合器和噪声聚合器来编码多样的知识并过滤有害信息,这一方法提供了一个在训练大模型时管理和优化知识表示的有效途径。
4、在优化知识空间时引入正交方向上的对齐模块,有助于减轻知识遗忘问题。