来源:NeurIPS 2024
作者:Gabriel Sarch,Lawrence Jang, Michael J. Tarr, William W. Cohen, Kenneth Marino, Katerina Fragkiadaki
单位:卡内基梅隆大学,Google DeepMind
一、背景
视觉语言模型(VLM)已取得令人瞩目的成果,但在复杂的多步骤任务中依然存在显著局限。这些任务需要代理能够理解长期上下文、进行多轮推理并从过去的经验中学习。受人类通过总结经验学习的启发,文章提出让 VLM agents 在执行任务时自动生成可复用的“化身思维程序”(Embodied Programs of Thought,EPOTs),作为未来任务的记忆库。与仅存储历史轨迹的被动记忆不同,EPOTs 能主动总结并提炼核心经验。
文章的主要研究问题是:如何让 VLM agents 在完成任务的同时,自动提取、总结并生成可复用的程序化经验,以便未来调用。
二、贡献
- 提出了新型的学习框架ICAL(In-Context Abstraction Learning):首次将多模态抽象学习与上下文记忆机制结合,使 VLM 能从噪声演示中提取结构化经验。
- 定义并实现了“化身思维程序”(EPOTs):引导代理总结任务中的关键子目标、因果关系、状态变化等认知抽象,并形成可调用的任务模板。
- 设计了双阶段抽象机制(自动 + 人类反馈):既能自动修正任务路径,又能融合人类语言反馈,持续优化抽象。
- 在多个任务中实现 SOTA 性能:包括 TEACh(家庭任务)、VisualWebArena(网页任务)、Ego4D(视频预测)等。
三、核心设计
总体架构:

每次迭代都从一条带噪声的轨迹开始,ICAL 分为两个阶段对其进行抽象:
- VLM抽象阶段:
- 接收噪声轨迹ξnoisy、指令 I 和历史示例 {e1,…,ek};
- 输出优化后的轨迹 ξoptimized和语言抽象 L;
- 抽象包括:
- 任务与因果结构
- 状态变化
- 子目标分解
- 状态变量筛选(与注意力机制类似)
- 人类反馈阶段:
- 执行优化轨迹,失败时人类提供语言反馈 H(at,ot);
- 模型结合反馈修正轨迹,并更新抽象:
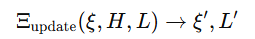
- 成功后将示例 e =(ξ′, L′ )存入记忆库 M 。
一旦轨迹成功执行,它将被存档至一个不断扩展的示例库中。该示例库既可用于模型训练,也可在推理时为代理提供上下文参考,以应对新的任务指令与环境。
部署时的检索增强(RAG):
- 给定任务指令 I,从记忆库 M 中检索相似示例:
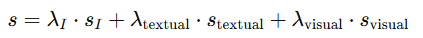
- 用于生成最终动作序列或行动策略。
四、实验
- 实验环境
研究者在 TEACh 和 VisualWebArena 中测试了 ICAL 的任务规划能力,并在 Ego4D 基准测试中测试其动作预测能力。其中,TEACh 针对的是家庭环境中的对话式教学,VisualWebArena 则是多模态自动化网络任务,Ego4D 则是用于视频动作预测。
| 环境 | 任务类型 | 特点 |
| TEACh | 家庭指令任务 | 对话输入,具身执行 |
| VisualWebArena | 多模态网页制作 | 图文组合输入 |
| Ego4D | 视频动作预测 | 被动感知,无交互反馈 |
2. 指标
- SR:任务成功率
- GC:目标条件成功率
- Edit Distance:名词 / 动作预测差异(视频任务)
3. 结果
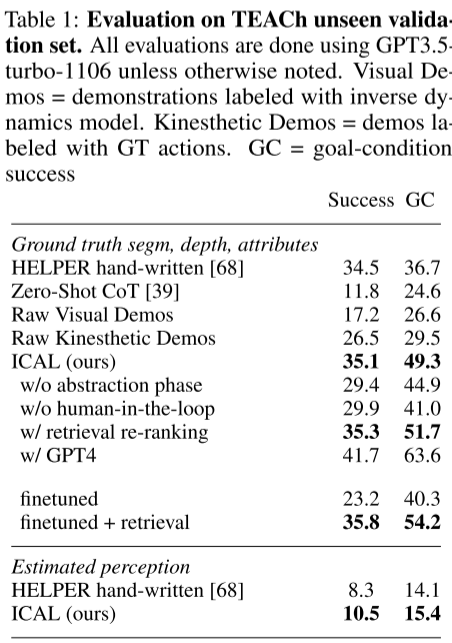
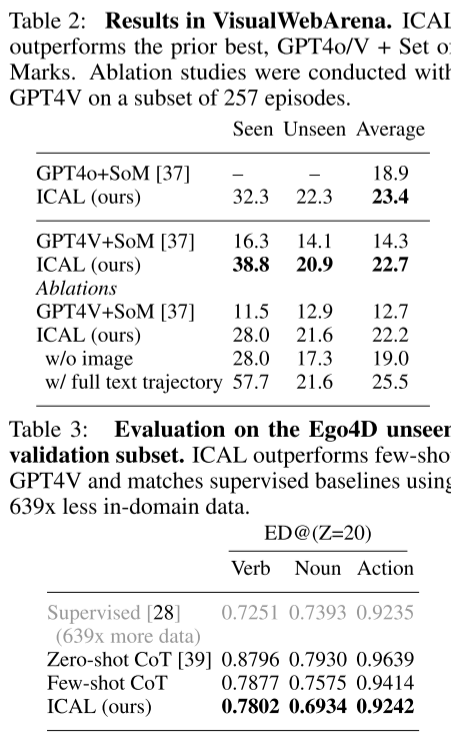
- TEACh:ICAL 提升 SR +8.6%,GC +12.6%,超越 SOTA HELPER;
- VisualWebArena:ICAL 相比 GPT-4V 提升 +8.4%(相对 +58.7%);
- Ego4D:ICAL 在使用 1/639 数据下逼近全监督性能。
五、总结
ICAL 提出了一种全新的多模态上下文学习机制,让 VLM 代理能够:
- 从次优示例中自主学习;
- 生成可解释、可迁移的抽象;
- 在不同任务场景中不断优化策略。