来源:CVPR
时间:2023
单位:State Key Lab of CAD&CG, Zhejiang University,Google
作者:Ahmad Salimi, Tristan Aumentado-Armstrong, Marcus A. Brubaker
一、研究背景及意义
在3D多视角区域中进行编辑功能仍然受到限制,要么依赖3D建模技巧,要么仅允许在几个类别中进行编辑。在本文中,本文提出了一种新颖的语义驱动NERF编辑方法,该方法使用户能够用单个图像编辑神经辐射场,并能够稳定地提供了具有更好的真实性和多视图一致性的编辑的新视角。
二、研究思路及方法
现有的多视角编辑的一些缺陷
①能够在2D图像上实现很好的效果,但是在3D多视角上效果一般。
②他们需要费力的注释,例如图像mask和网状顶点来实现所需的操作。
③他们进行全局样式转移,同时忽略每个对象部分的语义含义(例如,车辆的窗户和轮胎
应以不同的方式纹理。
④难以在具有真实的影片纹理或分配外特征的物体上进行纹理编辑。
提出的方法
①为实现3D场景下的多视角的一致性编辑,本文提出了一种先验引导的编辑场,用于在三维空间中编码精细的几何与纹理编辑信息。
②开发了一系列辅助编辑过程的技术,包括利用代理网格的循环约束以实现几何监督、一种颜色合成机制以稳定语义驱动的纹理编辑。
③一种基于特征聚类的正则化方法以保持无关内容不变。
本文贡献
①本文提出了一种新颖的基于语义驱动的基于图像的NERF编辑方法,SINE,该方法允许用户仅在渲染的单视图上编辑神经辐射字段。SINE利用了先前的指导编辑字段来编码给定预训练的NERF上的细粒几何形状和纹理变化,从而提供了具有高保真度的多视图一致的编辑视图。
②为了实现语义编辑功能,本文开发了一系列技术,包括具有用于几何编辑的代理网格的循环约束,增强纹理编辑的颜色合成机制以及基于特征群集的正则化,以控制受影响的编辑区域并保持无关的部分。
③实验和编辑示例在(现实世界/合成)和以对象为(中心/无界)的360场景数据上都显示出具有出色的编辑功能和质量。
模型结构
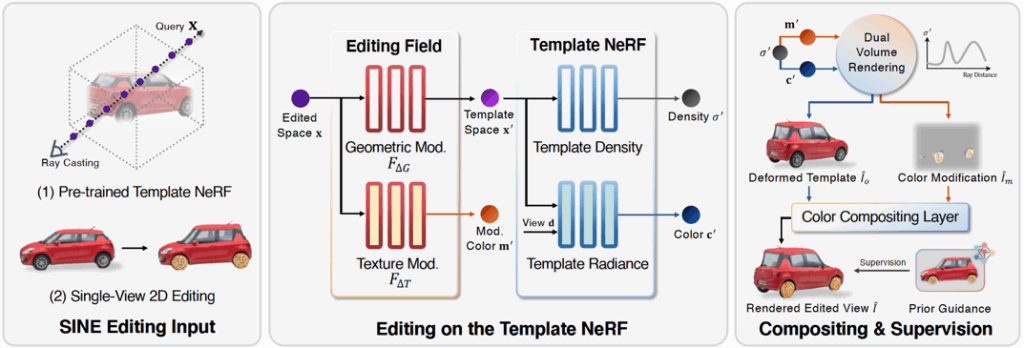
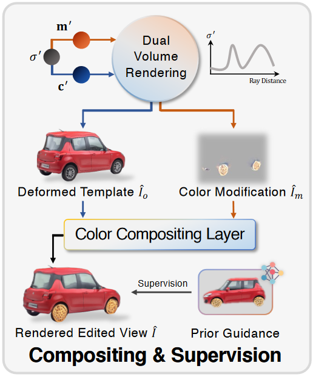
模型概述。模型用先前的编辑字段对原始模板NERF进行编码几何和纹理变化,其中几何修改字段F△G将编辑的空间查询X转换为模板空间X’,而纹理修改字段F△T编码修改颜色m’。然后,模型将变形的模板图像Io和颜色修改图像Im带有所有查询,并使用颜色合成层将Io和Im混合到编辑的视图。
SINE Rendering Pipeline
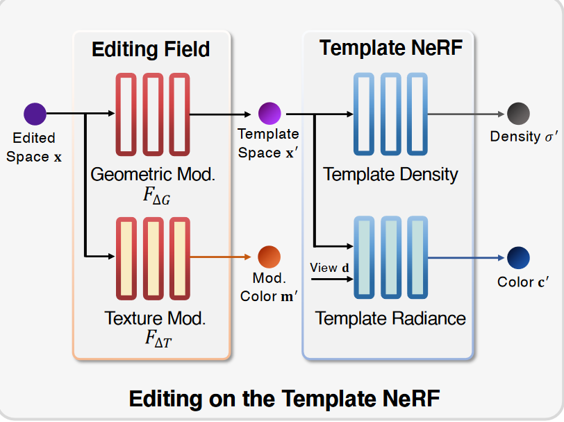
如上图所示,本文使用专用编辑字段来编码预先训练的模板NERF上的几何形状和纹理变化。编辑场由一个隐式的几何修饰字段F△G和一个纹理修改字段F△T组成,其中,FΔG将查询点从观测到的编辑空间变换到原始模板空间。FΔT编码修饰颜色m’,具体而言,对于每个采样的查询
点{xi |i=l,.…,n},沿着视图
d,首先获得变形点
x’(在模板空间中)和修改颜色
m’,然后将x’和d馈入模板nerf,
以获得密度δ’和模板颜色c’。
然后,按照正交规则在编辑字段和模板nerf上执行双重卷,该卷被定义为:
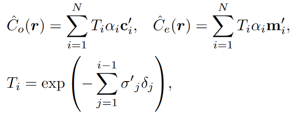
Prior-Guided Geometric Editing
本文利用几何先验模型,神经隐式形状表示、深度预测来缓解单个角度的几何编辑的歧义性。
①对于特定形状类别(例如汽车,飞机)中的对象,本文使用DIF,其中隐式SDF字段和先前的网格可以使用可优化的潜在代码z生
成。本文编辑的NERF的几何形状可以通过预先训练的DIF模型来解释,并具有几何损失:
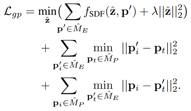
②对于没有类别级的对象,可以事先构建最终形状。实际上,找到具有二维对应关系的三维形变顶点和单眼深度预测,并
使用ARAP将代理三角形网格M1变形为M2。然后,可以在等式中继承上面的损失项。用于提前指导的监督。
三、结果

四、总结
本文提出了一种新颖的语义驱动神经辐射场(NeRF)编辑方法。该方法支持仅依据一张用户编辑后的图像对具有照片级真实感的模板神经辐射场进行编辑,并能生成具有高保真度和多视角一致性的编辑后新视图。作为一种局限性,本文的方法目前不支持具有拓扑结构变化的编辑操作,这可作为未来的研究方向。此外,我们的方法假定用户的编辑具有语义意义,因此不能使用包含无意义随机涂鸦的目标图像。
五、思考
对于数据较少的多视角一致性相关实验与性能提升,本文具有借鉴意义。