背景(Background)
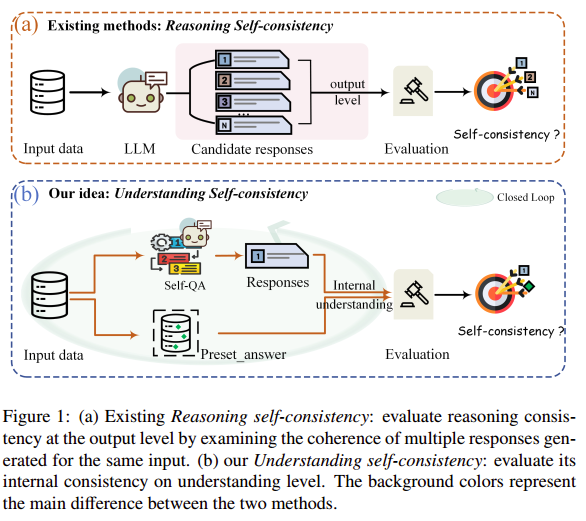
论文聚焦于如何衡量大语言模型对其已学知识关系的真实掌握和理解,认为仅依赖传统的“输出层面自洽性”不足以反映模型内在逻辑一致性和深层语义理解能力。
创新点(Highlights)
- 提出“理解自洽性”新概念,从输入与输出的一致性去量化模型对事实、逻辑等知识的掌握程度;
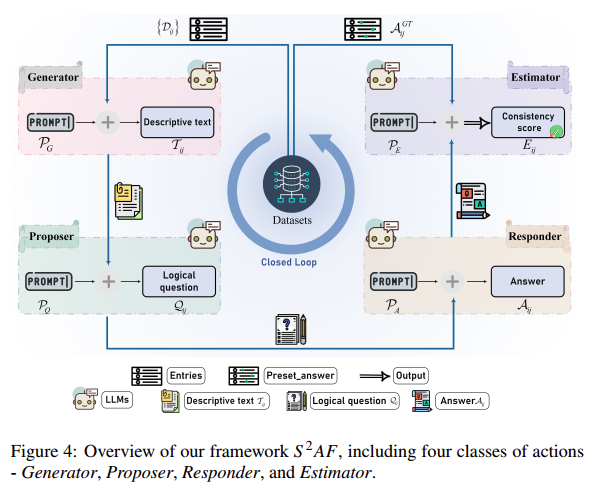
2. 设计了自检框架,通过自问自答的方式,构成一个逻辑闭环;
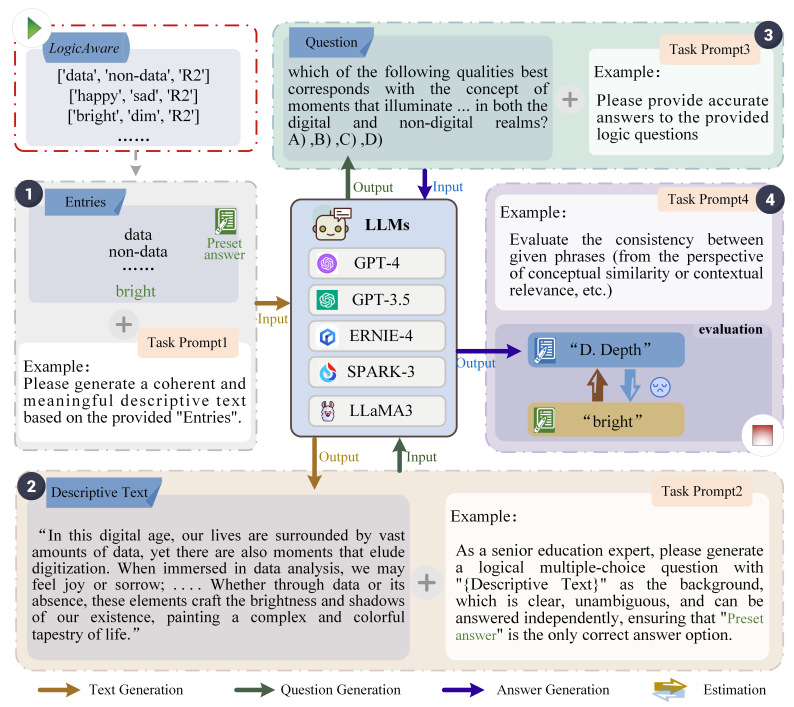
3. 构建并开放 LogicAware 数据集,结合 FOLIO 进行多维度、多任务场景下的实证分析;
4. 提出了 SEF 机制,让模型利用自身生成的上下文信息反哺后续推理,进一步提升了自洽表现;
5. 定量与定性研究相结合,深入探讨了幻觉出现的模式和影响,为后续改进大模型的自洽性提供了方向。
方法(Methodology)
结果(Results)
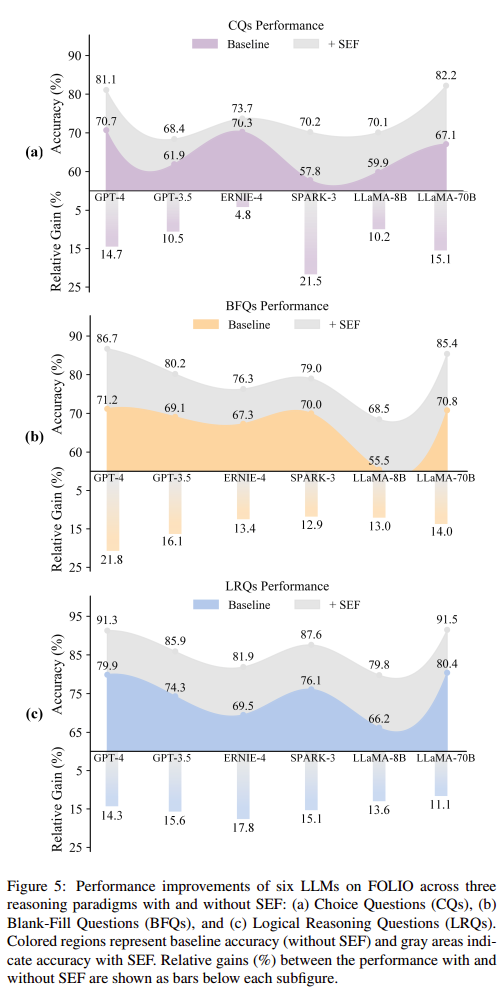
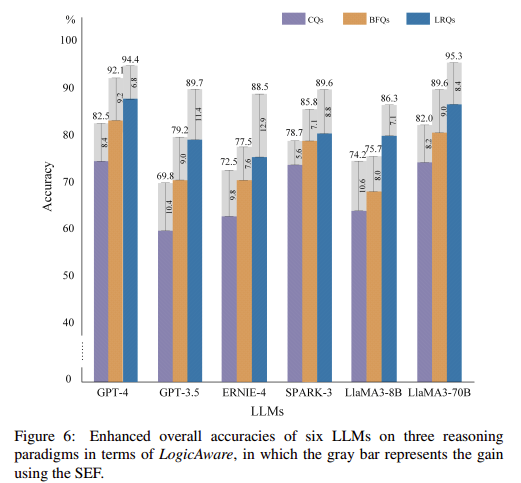

结论(Conclusion)
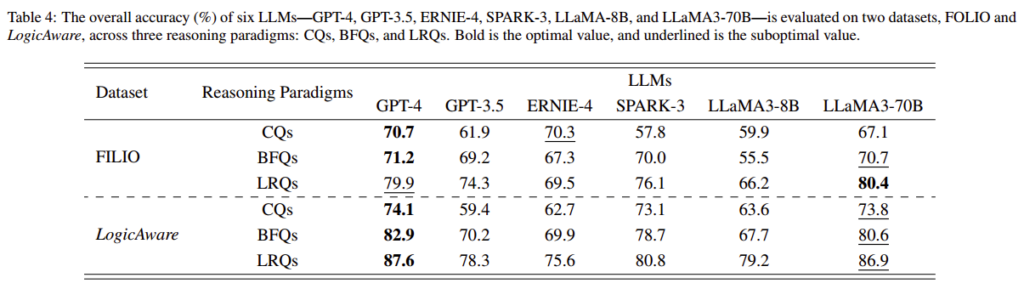
LLM在理解和把握知识关系方面表现出差异,而且,实验表明,LLM的性能可以通过它们自己的输出来提高。总体而言,该框架为深入探索LLM能力及其自主推理和评估提供了一个新的视角。
相关链接(Links)
Shao H, Wang F, Xie Z. S2AF: An action framework to self-check the Understanding Self-Consistency of Large Language Models[J]. Neural Networks, 2025: 107365.
https://www.sciencedirect.com/science/article/abs/pii/S0893608025002448