背景(Background)

创新点(Highlights)

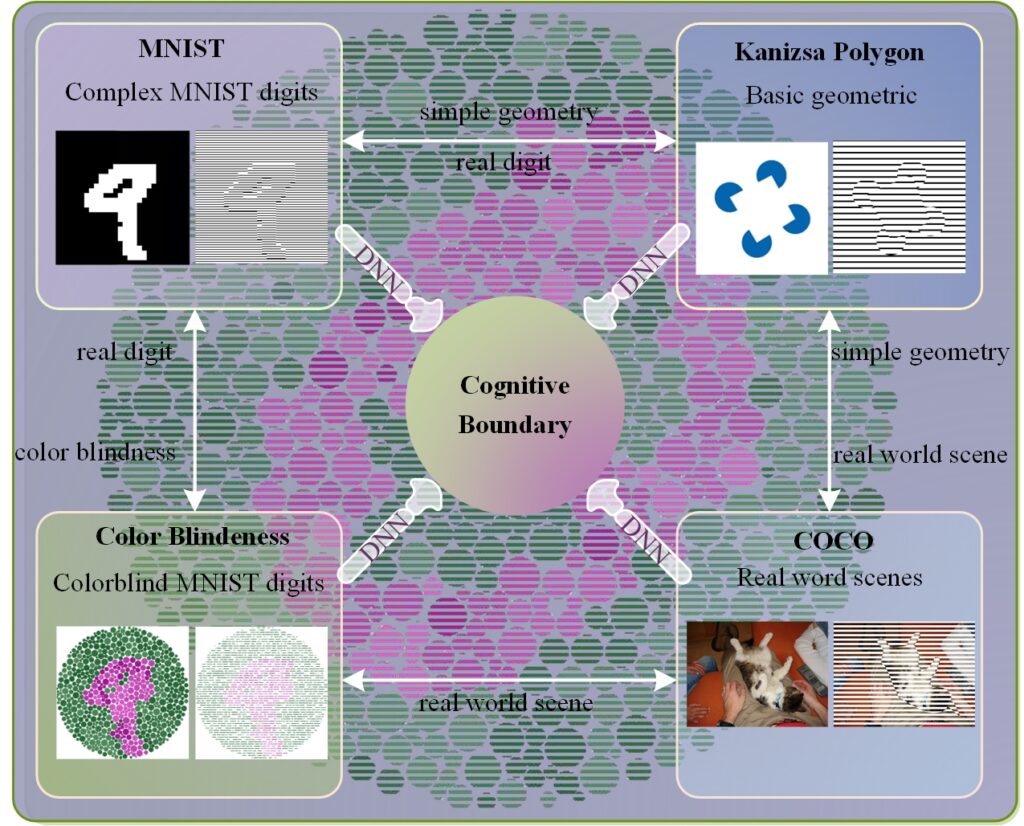
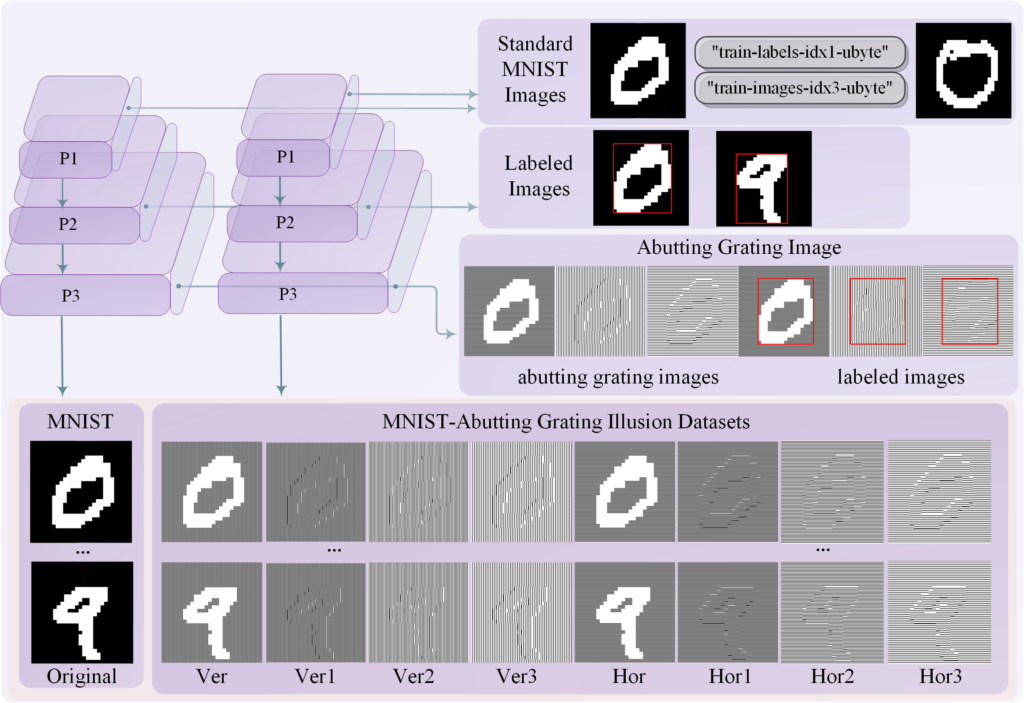
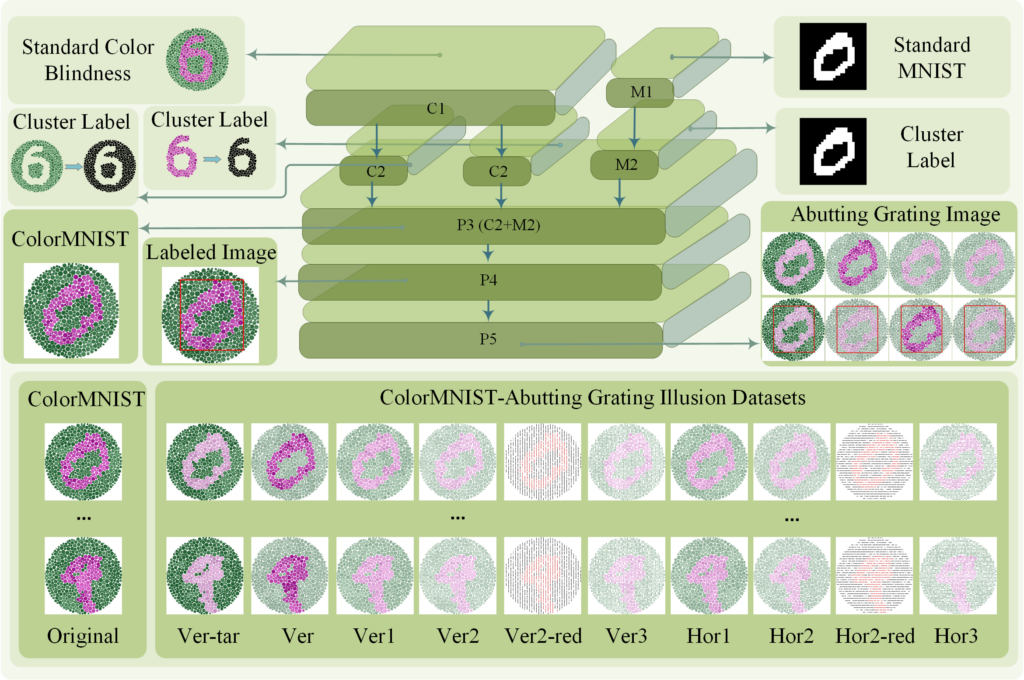
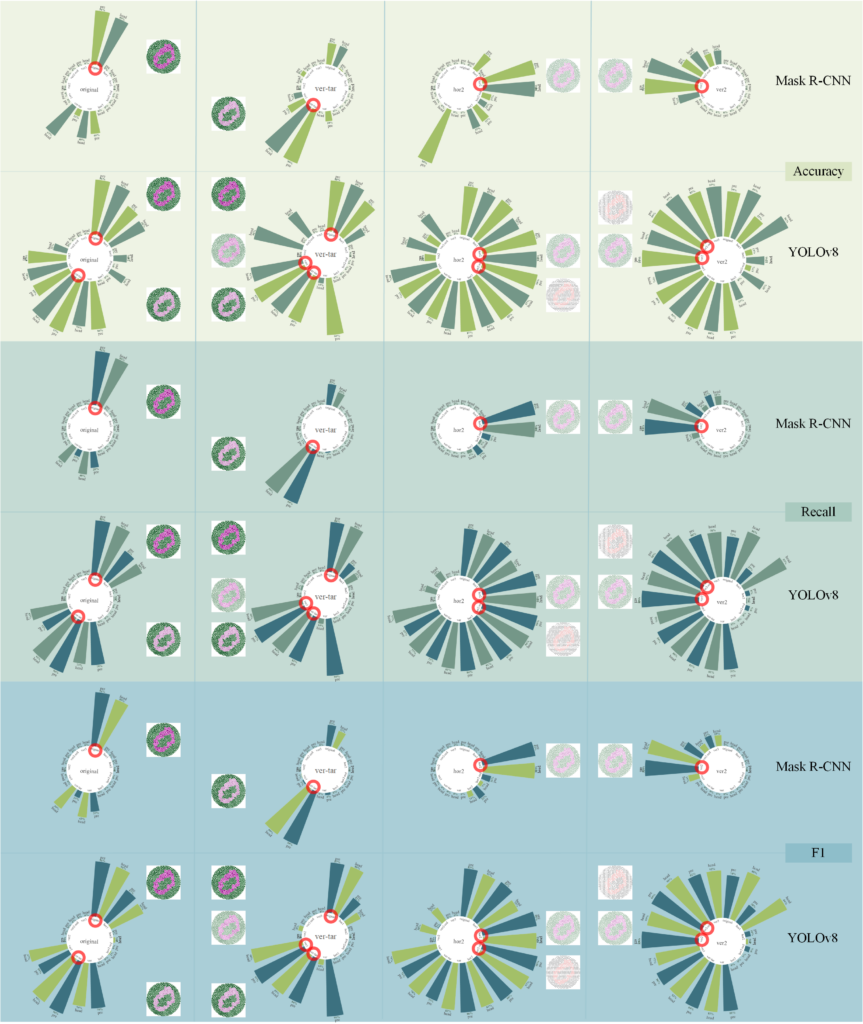
方法(Methodology)


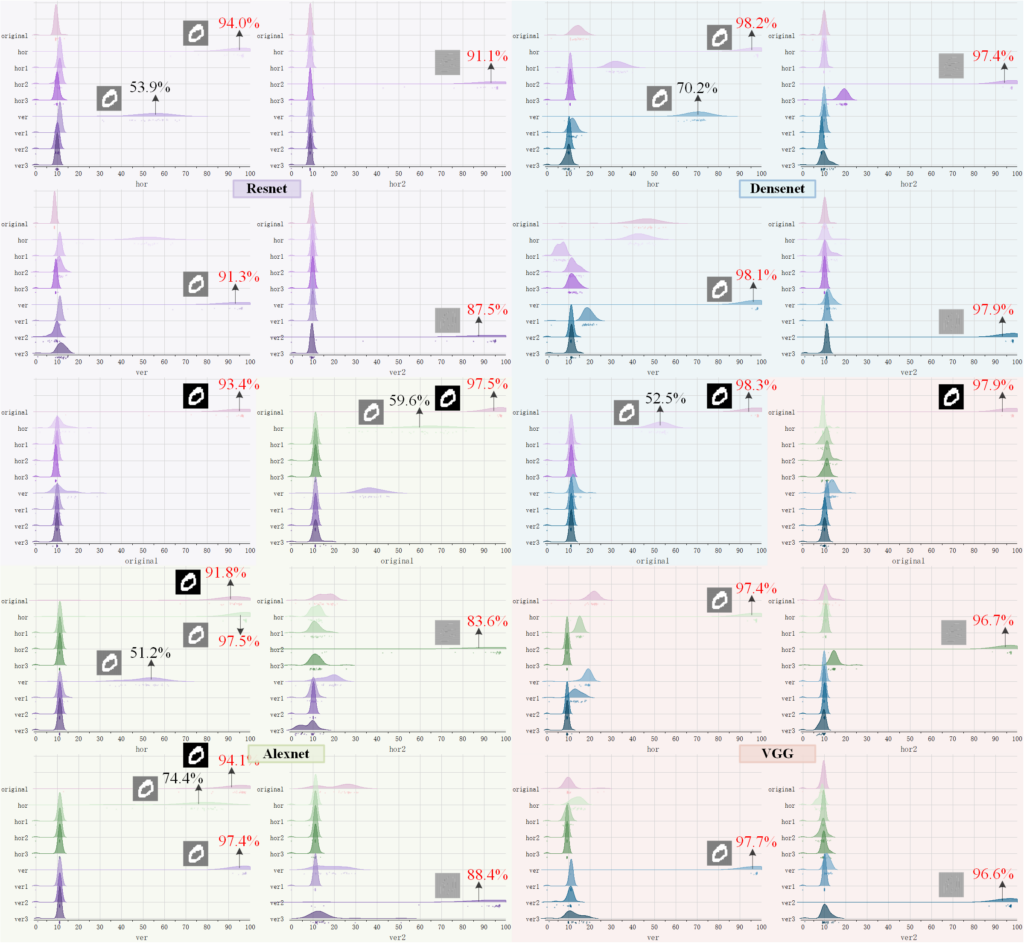
结论(Conclusion)



相关链接(Links)
Li, T., Lyu, R. and Xie, Z., 2024. Pattern memory cannot be completely and truly realized in deep neural networks. Scientific Reports, 14(1), p.31649.
Li, T., Lyu, R. and Xie, Z., 2024. Pattern memory cannot be completely and truly realized in deep neural networks. Scientific Reports, 14(1), p.31649.