- 作者:Jin B, Xie C, Zhang J等
- 发表单位:University of Illinois at Urbana-Champaign,Amazon,Pennsylvania State University,University of Virginia
- 发表在:ACL 2024
核心内容
- 由于现有的 RAG 方案无法有效应对推理问题,本文构建了一个包含文本属性图的 QA 数据集,并且提出了 Graph-CoT 这一框架用于实现迭代式推理;
- Graph-CoT 这一框架推理包含三步:LLM 推理、LLM 与图交互以及执行指令,通过不断迭代地执行这三步,Graph-CoT 可以进行分步推理并且生成证据链,实现更好的逻辑问答;
- 作者做了详尽的实验,证明了 Graph-CoT 的优越性以及其特性和缺陷。
背景
- 问题:大模型展现出了强大的语言能力,但是由于不能及时更新内部知识,也不能提供可靠的信息源,所以大模型在问答任务上一直以来都深受机器幻觉问题的困扰;
- 现有解决方案:主流的解决思路是引入外部知识,这一解决思路的代表是 RAG;然而 RAG 将文档看作彼此不相干的知识单元去检索,实际上这是有问题的。事实上,知识单元彼此之间有联系,这些联系就将各个知识单元组织为图。因此,很多研究都用图上的搜索替代原来的检索方案;
- 现有解决方案面临的问题:
- 图结构信息的价值藏在结构之中,检索单个顶点或者文本不能发挥出其价值;必须基于图的结构去做推理;
- 如果将和某个顶点有关的一部分顶点和边称之为子图,那么子图的大小会随着问题需要的推理步数增加而指数增长。过多的检索内容会导致 lost in middle 现象,使得 LLM 性能下降;
- 本文的贡献:
- 制作了一个数据集用于评估系统在这类问题上面的表现;
- 提出了 Graph-CoT 框架,让 LLM 迭代式地在图上进行推理,解决现有方案面临的问题;
- 进行了一组实验,验证了本文提出模型的优越性;并且分析了 Graph-CoT 在不同难度问题、不同的 LLM 以及不同超参数之下的表现。
方法论
定义
- 文本属性图:$\mathcal{G}=(\mathcal{V,E})$
- $v_{i} \in\mathcal{V}$:顶点,其具有属性 $\mathcal{X}{v{i}}$
- $e\in\mathcal{E}$:边,根据具体问题来定义
- 邻居:$N(v_{i})={ v_{j}|e_{v_{i},v_{j}}\in\mathcal{E} }$
- 度:$D(v_{i})=|N(v_{i})|$
作者在提供的数据集中给出了几类问题使用的顶点、属性以及边的定义:
- 学术:
- 顶点:文章、作者、机构
- 关系:编写、发表在、引用、隶属等
- 电商:
- 顶点:商品、品牌
- 关系:同样看过、同样购买
- 文学:
- 顶点:书籍、作者、出版人、系列
- 关系:写作、发布、系列
数据集
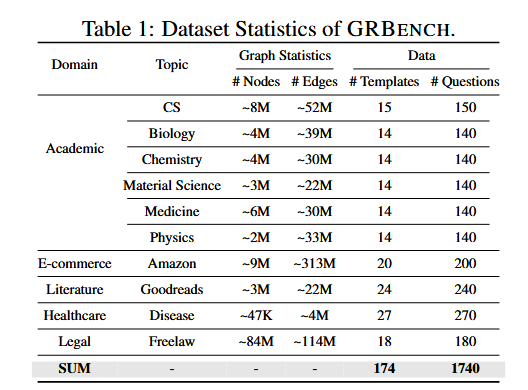
本文的 benchmark 数据集 GRBENCH 是作者自行构建的。GRBENCH 是一个 QA 数据集,其总共包含 10 个图,涉及 5 个领域的知识,总共 1740 个 QA 数据对。
GRBENTCH 的构建流程:
- 构建图(未给出如何构建)
- 编写问题模板(人工)
- 根据问题模板,填入图中实体生成问题答案
- 用 GPT-4 修改表达
Graph Chain-of-Thought
Graph-CoT 采取了一种和 RL 智能体决策类似的思路,将 LLM 看作智能体(agent),让其自行决定如何检索信息,然后根据返回的信息再进行下一步决策。
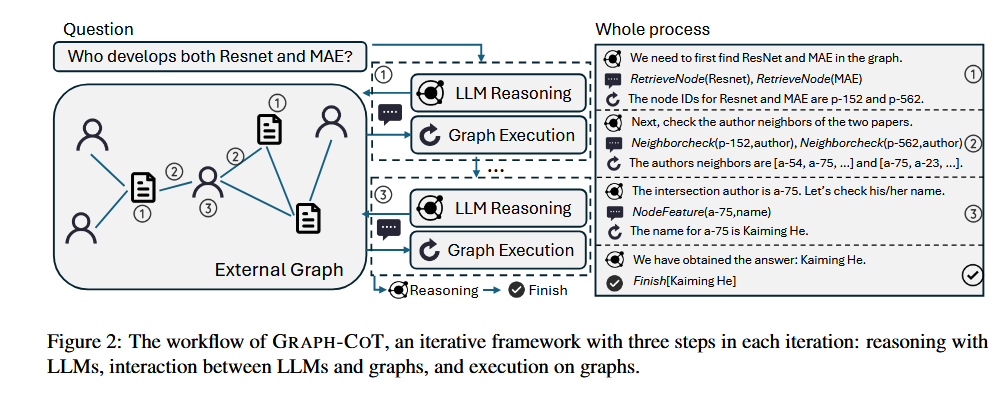
Graph-CoT 的回答问题分三步:
- 推理:让 LLM 基于问题以及之前的推理给出解答问题所需要的信息
- 交互:要求 LLM 生成检索所需信息的指令;检索指令是预先定义好的,但是参数需要 LLM 生成:
- RetrieveNode(Text)
- NodeFeature(NodeID, FeatureName)
- NeighborCheck(NodeID, NeighborType)
- NodeDegree(NodeID, NeighborType)
- 执行:执行检索指令,获取返回的信息
- 重复执行上述三步,直到 LLM 认为问题已经可以回答或者触及最大迭代次数
实验
Graph-CoT 面向问答任务,其对比基线为:
- Base-LLMs
- Text-RAG
- Graph-RAG
其中,RAG 模型使用 Mpnet-v2 作为来检索,使用 FAISS 来构建索引。
Graph-CoT 的 backbone 模型为 gpt-3.5-turbo-16k,辅之以提示词示例;评估方法有:
- 基于规则的方法:[[Rouge-L]](R-L)
- 基于模型的方法:GPT-4 score

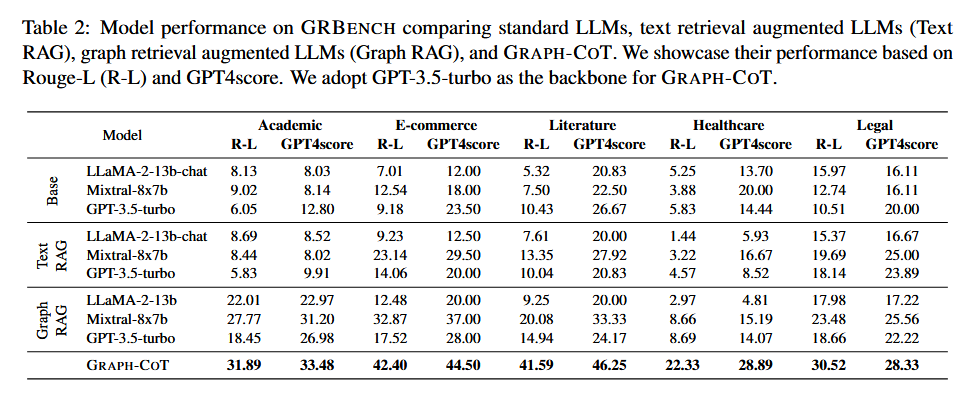
可以发现,Graph-CoT 在自家数据集上效果远高于基线模型。
消融实验
作者研究了提示词示例对效果的影响,作者做了如下实验:
- 使用本领域的示例
- 使用其他领域的示例
- 不使用示例
得出的结果如图:
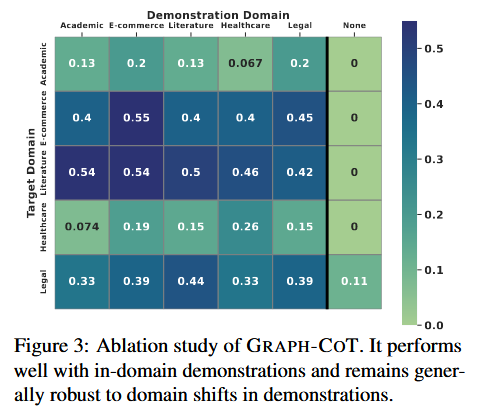
除了无示例普遍表现不好,其他的都还可以;而且每一行颜色都相似,说明用哪个领域的示例其实不重要。
另一个比较重要的问题就是 backbone 大模型的选择对模型的影响。对比实验结果如图:
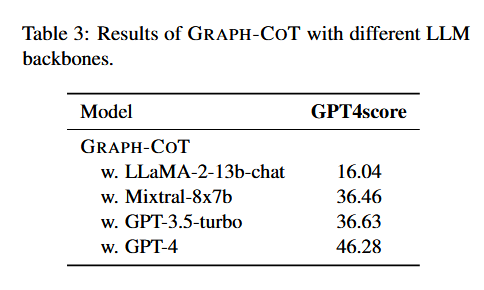
显然参数多效果最好。
然后是 RAG 在图上的检索效果,这是 KG-GPT 这样的方法常见的检索策略。作者对比了不检索、之检索结点、检索一跳、两跳范围内的结点的效果:
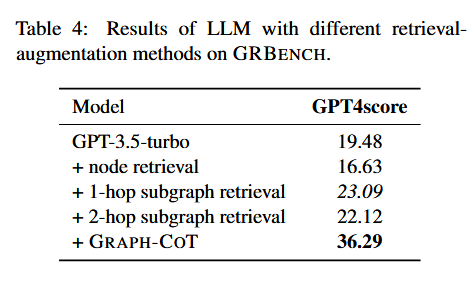

随着跳数增加,正确率反而下降。这说明 lost in middle 问题发生了。
最后是 Graph-CoT 应对不同难度问题时候的表现:
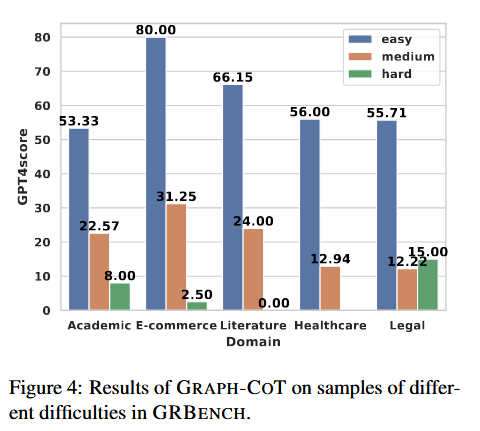
最终效果随着题目难度上升显著下降。果然推理链长度一上去出错概率就指数增长。
案例分析
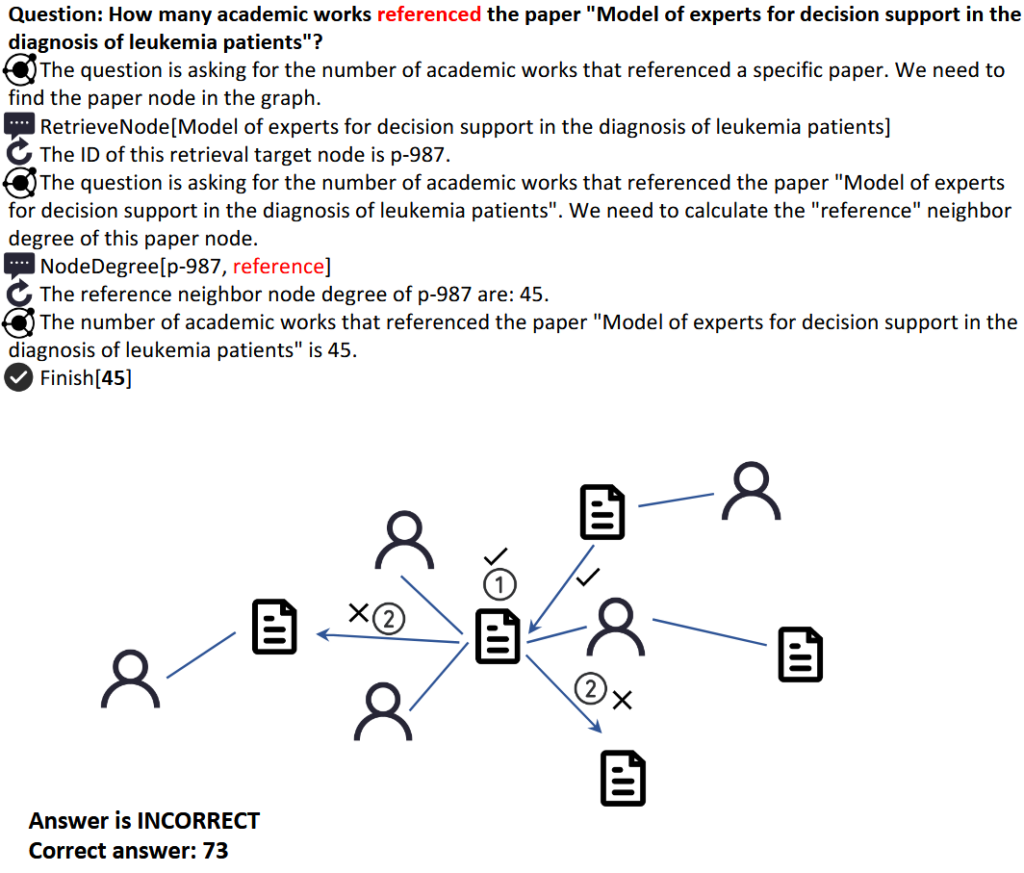
分析案例 1:

结论
- 构建了一个叫做 GRBENCH 的数据集,包含问题、材料、以及图谱;
- 提出了 Graph-CoT,引导 LLM 在图上进行迭代式推理构建出思维链,增强其逻辑能力;
- 进行了详尽的实验验证了 Graph-CoT 的优越性以及存在的问题。
启发与评价
- 之前大多数检索推理基本上都是盲的,即不会根据查询选择合适的推理方向,要么就是忽略知识之间的相关性,直接做搜索;要么就是按照遍历的思路返回一定范围内所有结点组成的子图,导致严重的 lost in middle 问题;本文提出的 agent 思路是一个很好的思路,可以实现启发式的图数据检索;
- 本文重新定义了一种图数据结构,可以看作是给实体加上了属性、并且带有本体(Ontology)的知识图谱;作者为不同领域的知识设定了不同的本体,通过本体来限定实体和边的类型让我们可以从图结构中得到有意义的信息。二阶图谱构建的时候也应该针对不同的领域设定不同的本体一提取最有效的信息;
- 本文的实验非常详尽,基本上对方方面面都有考察。但是从实验数据可以发现,Graph-CoT 的总成绩仍然是不好的。在所有领域上,Graph-CoT 的正确率都低于 50%,而且正确率随着难度提升下降极快。比如 Graph-CoT 在健康领域的难题中回答正确率为 0。