Enhancing Complex Question Answering over Knowledge Graphs through Evidence Pattern Retrieval
- 作者:Ding Wentao 等
- 发表单位:State Key Laboratory for Novel Software Technology, Nanjing University
- 发表在:ACM Web Conference (WWW) 2024
核心内容
背景
- 知识图谱问答这个领域的研究方法大约可以分为两类:语义解析和信息检索。前者由于需要大量的样本对数据而受到限制,后者的表现则高度取决于检索得到的子图质量如何;
- 当前的知识图谱子图检索方法大多都会抽取出大量对解决问题没有帮助的内容,这些内容会严重影响问答的表现;
- 为了解决这样的问题,本文定义了「证据模式」(evidence pattern,EP)并且提出了证据模式检索(EP Retrieval,EPR)来有效地减小知识图谱检索得到的子图中存在的噪声;证据模式定义了实体和关系该如何组合起来形成答案。为了实现检索,本文分别训练了神经网络模型来实现 EP 检索和打分从而实现更好地 KGQA;
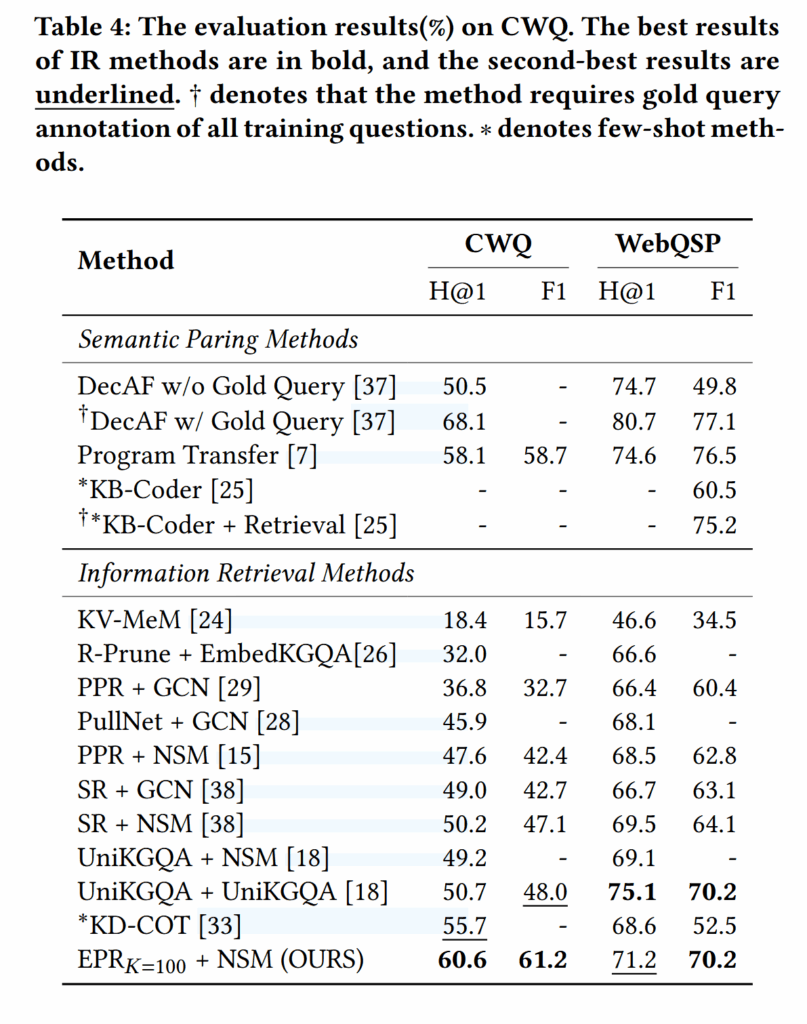
- ERP 在 ComplexWebQuestions 和 WebQuestionsSP 上都取得了好成绩。
方法论
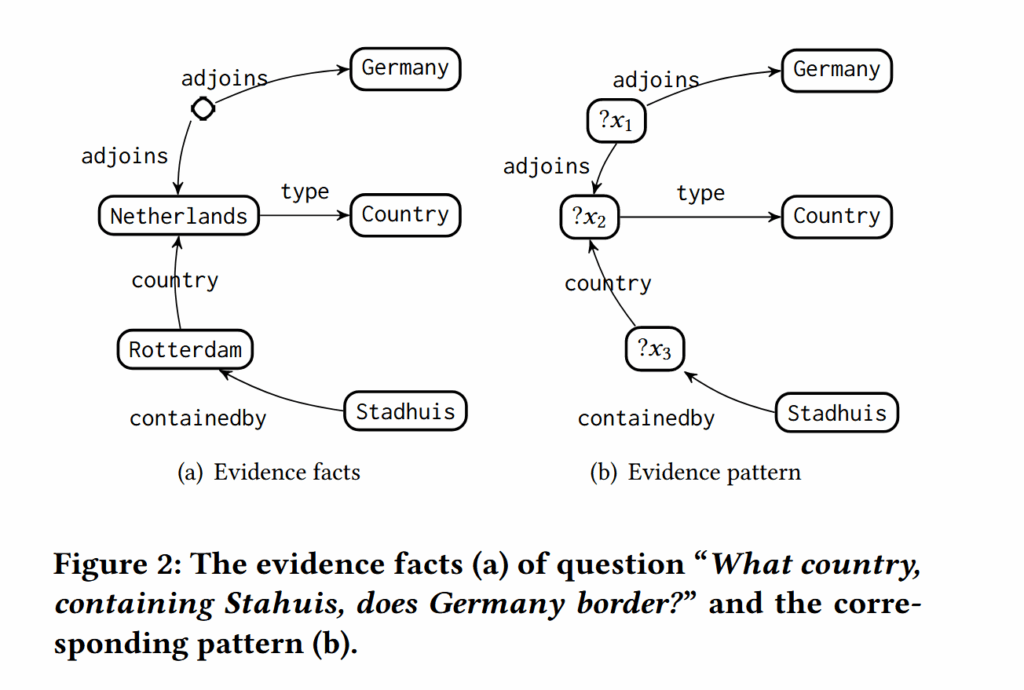
证据模式
所谓证据模式(EP),实际上是一种形式不完整的知识图谱子图。完整的子图可以作为一组事实(左图),而不完整的子图则是模式(右图):
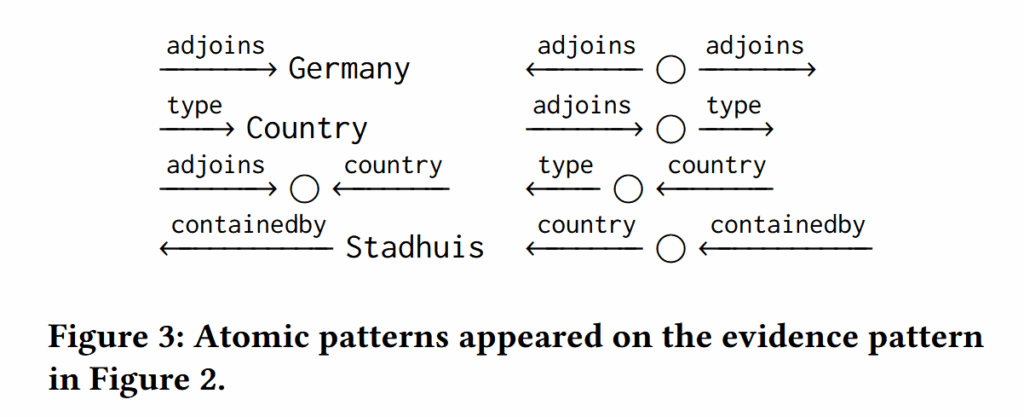
 由于一个大型知识图谱包含的 EP 可能极多,必不可能进行检索,因此可以退而求其次,将 EP 拆解为最小单位再进行检索。这样的最小单位称之为原子模式(Atomic Pattern,AP)。原子模式有两种:
由于一个大型知识图谱包含的 EP 可能极多,必不可能进行检索,因此可以退而求其次,将 EP 拆解为最小单位再进行检索。这样的最小单位称之为原子模式(Atomic Pattern,AP)。原子模式有两种:
- 实体-关系对(AP-ER):缺失了一个实体的三元组;
- 关系-关系对(AP-RR):缺失了三个实体的两个相连三元组。
AP 检索
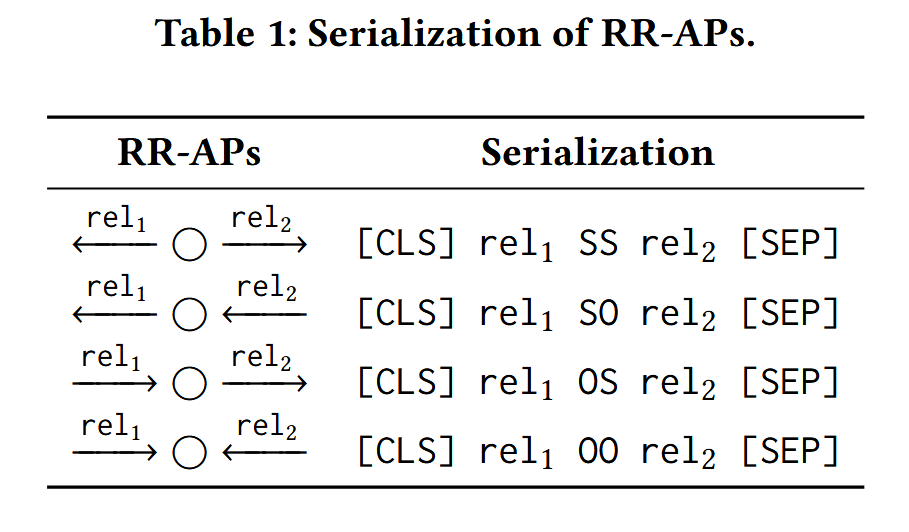
对于给出的问题 $q$,这篇文章基于 $q$ 分别检索 AP-ER 和 AP-RR。检索 AP-ER 可以用实体搜索,即筛选出所有包含有 $q$ 中提到实体的 AP-ER;AP-RR 没有实体,所以必须用别的方法。这篇文章使用了传统的双编码器法,微调了一个 BERT 模型来进行编码任务。训练用的正样本是训练集问题答案实体周围 1~2 步范围内的 AP-RR;负样本则是被篡改了标签的正样本以及随机采样出来的 AP-RR。训练和搜索过程中的结构化数据都需要序列化为字符串。

候选 EP 构建
候选 EP 是用检索得到的 AP 构建得来的。构建算法如下图:

这个算法其实是一种回溯法,全排列问题的一个变种。
本算法需要求的解是 EP 的集合 C,当前已经构造好的部分是 P,还可考虑使用的 AP 集合是APER和APRR。作者将 EP 看作一组 AP 的排列,通过深度优先遍历方法来枚举所有排列,并且筛去不符合要求的解。这个算法可以看作经典的回溯法排列树问题。
剪枝条件:
- EP 包含 AP 的个数必须小于或等于 $\tau$(已经构造的部分长度抵达 $\tau$ 就不需要继续递归)
- 已经包含有相同实体的 AP 不能再使用(跳过这些 AP,相当于剪枝)
- 无法加入到 P 中的 AP 不考虑(用 EXPANDABLE 判定)
下图演示了 AP 被加入到 P 中的过程:
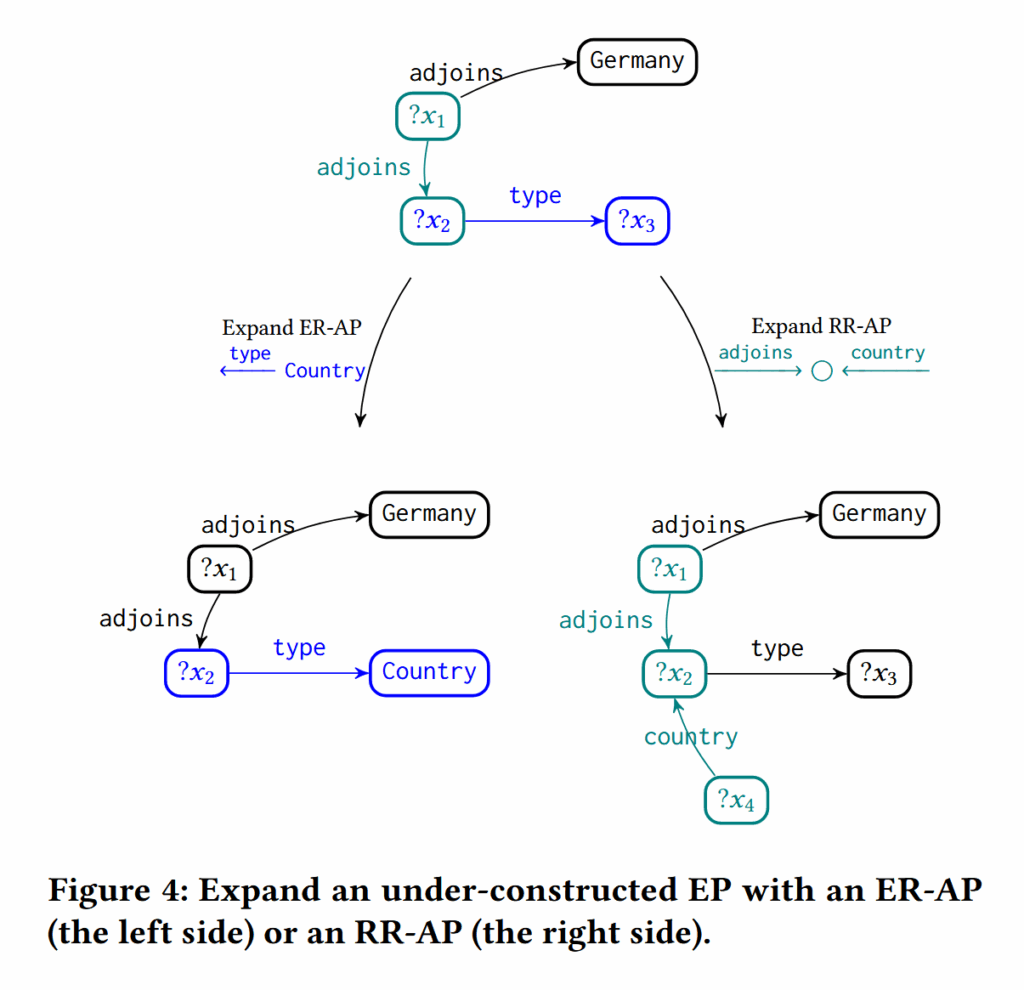
判定 P 是否合规的函数 $\text{IsValidPat}$ 主要判断两点:
- 所有的叶子顶点都是 $q$ 中能找到的实体
- 如果第一点做不到,那么允许有一个叶子顶点不是 $q$ 中的实体
函数 $\text{Expand} ,\text{Expandable}$ 则检查 P 上面是否存在能和待扩展的 AP 相连接的部分,即二者是否都有一个缺失部分能够互相补足。
EP 排序
EP 可以直接被转换拼接成为文本,这样就可以使用 BERT 计算和 $q$ 的相似度了。这个相似度会被作为排序的依据。
$$
\text{sim}(P,q)=W\cdot\text{BERT}(P,q)+b
$$
实验
- 数据集:ComplexWebQuestion (CWQ), WebquestionSP (WebSP)
- 检索器:FAISS
- BERT:
bert-base-uncased - 生成最终答案:NSM
- 计算:Intel Xeon Gold 5222 CPUs, NVIDIA RTX 3090 GPUs
实验结果:
结论
这篇文章提出了 EPR,一个可以降低检索得到的子图中的噪声的子图检索方法;其主要贡献:
- 首次提出了证据模式的概念(EP),证据模式可以直观地表示知识图谱中的结构化依赖
- 提出了使用原子模式构建证据模式的算法,可以高效地构建证据模式
- 在多个数据集上验证了这套方案的效果
启发与评价
启发:
- 作者通过将完整的三元组拆解为不完整结构创造了证据模式这一概念,而不完整的部分充当了「榫卯」一样的结构,使得用 AP 构建的子图保持逻辑性,一定程度上克服了大多数知识图谱检索方法在图谱上盲搜索导致的问题;
- 包括这篇文章在内,大多数子图检索方法都是通过从若干种子顶点逐步扩张来构建子图的;但是目前流行的方法不管是什么样的检索方式,几乎都是盲目的,无法主动对扩张的方向做出选择,最终导致检索得到的证据噪声大;这篇文章通过证据模式的特性限制了扩张的方向,使得检索得到的子图必然和问题高度相关的同时保持了内部的逻辑性。
评价:
- 这一方法实际上可以看作是针对原子模式的 RAG,并且在此基础上利用了证据模式的特性对 RAG 获得的各个原子模式进行了一定的组织和筛选,因此这一方法必然继承 RAG 检索不完善的弊病;知识图谱中那些和问题的逻辑关系很强、语义关系很弱的部分全部都被排除在外了,这应该就是 20%~28%的错误的来源;
- 虽然利用证据模式的特点实现 AP 的组织和筛选这一策略很巧妙,但是这本质上仍然是一种加上了人为限制的盲搜索,基于规则的方法仍然很难保证检索得到的证据精准有效。