作者: Kentaro Seki, Yuki Okamoto, Kouei Yamaoka, Yuki Saito, Shinnosuke Takamichi, Hiroshi Saruwatari
单位:东京大学, 庆应义塾大学
来源: ICASSP
时间: 2026.05
一、研究背景

二、核心贡献

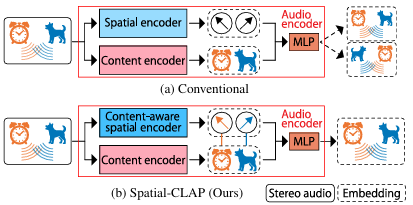
三、方法

四、实验
1.实验准备

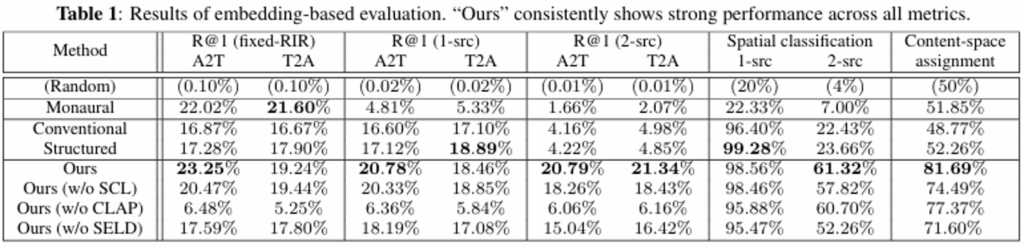
2.实验结果——Embedding-Based Evaluation
(1)普通clap几乎没有空间能力,传统spatial-clap仅能处理单声源空间,在多声源条件下并不可靠。
(2)将内容和空间分开建模,再进行组合,并不能真正学会声源-空间绑定问题。
(3)完整的Spatial-CLAP 在多声源检索、空间分类和内容-空间对应任务上均明显优于对比方法。
(4)消融实验说明,CLAP 负责内容语义,SELD/CA-SE 负责空间绑定,SCL 进一步强化多声源内容-空间对应。
3.实验结果——Spatial Audio Captioning
(1)在空间音频描述生成任务中,Spatial-CLAP 的 embedding 能生成整体质量更高、空间描述更准确的 caption。
(2)普通clap仅在语义相似度上结果较好,但几乎没有正确的空间方向描述。
(3)而传统的spatial-clap有一定的空间描述,但内容和方向的正确对应仍不如本文方法。
(4)SCL 在 captioning 上带来的是稳定但不算巨大的提升,而在内容-空间对应判断任务上作用更明显。
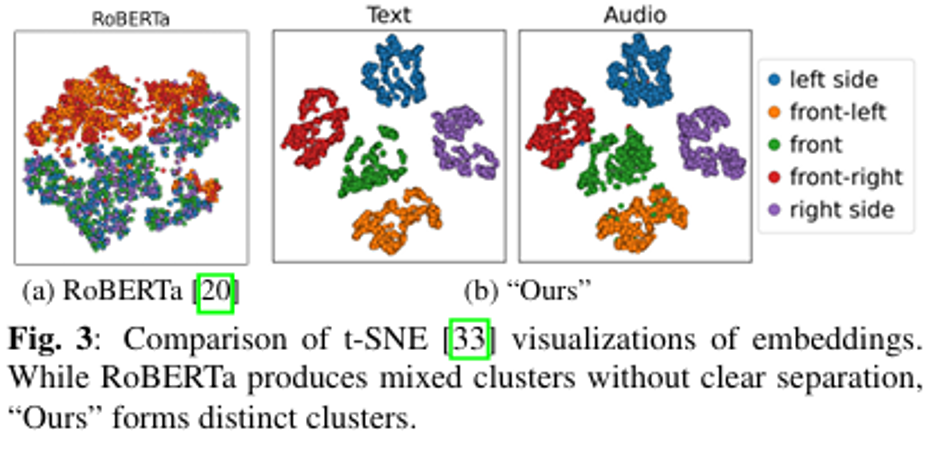
4.实验结果——Visualization of Embeddings
(1)RoBERTa 原始文本 embedding 对空间方向区分不明显,空间类别在可视化中混合较多。
(2)Spatial-CLAP 训练后的 embedding 能形成更明显的空间类别簇,说明模型确实学到了空间结构。
五、总结
(1)提出 Spatial-CLAP,将普通 CLAP 从单声道/单声源音频-文本对齐扩展到多声源空间音频-文本对齐。
(2)提出 content-aware spatial encoder,使空间表示不再是独立的方向特征,而是和声音内容绑定,从而解决“哪个声音在哪里”的问题。
(3)提出 spatial contrastive learning,通过交换声源空间位置构造 hard negative,显式训练模型区分正确和错误的内容-空间对应关系。
(4)实验验证 Spatial-CLAP 在多声源检索、空间分类、内容-空间对应判断和 spatial audio captioning 上都优于普通 CLAP 和传统 spatial extension。
六、对齐思考
1.方法创新点——全域数据拓扑建模:提出 Spatial-CLAP,用 CLAP 内容编码器、SELD 预训练的 content-aware spatial encoder,以及 SCL 空间对比学习,让模型学习多声源条件下的声音内容与空间位置对应关系。
2.技术目标点——虚实空间孪生推演:让 audio-text embedding 不只表达“有什么声音”,还表达“声音在哪里”以及“哪个声音对应哪个位置”,并支持检索、空间分类、内容-空间对应判断和 spatial audio captioning。
3.中试产品点——埃觅文旅: 可以帮助模型更好理解音频以及音频空间。