作者:Aniket Bhattacharyya1, Anurag Tripathi, Ujjal Das, Archan Karmakar, Amit Pathak, Maneesh Gupta
来源:ACL 2025
时间:2025.5.18
研究背景与问题
Visually Rich Document Understanding (VRDU) VRDU 处理的是同时包含文本和版面信息的文档——发票、表单、合同、收据等。这类文档在企业中量大、价值高(尤其金融、法律场景),自动化提取关键信息(KIE/IE)是长期研究热点。
已有方法或者会推理但看不懂版面,或者懂版面但不会推理。
三类既有方法各自的瓶颈:
| 方法路线 | 代表工作 | 主要缺陷 |
| 传统方法 | 规则、RNN、CNN、Chargrid 等 | 模板锁死,迁移性差,需要大量组件级标注 |
| Layout-aware NLP | LayoutLMv3, GeoLayoutLM, ERNIE-Layout, FormNetV2 | 本质是 token 分类,要求答案显式存在;基准上很强但碰到新格式就崩 |
| LLM-based | DocLLM, LayoutLLM, LMDX | 有推理但缺版面理解;LMDX 需要标注集中有同格式样本;在异构基准上跑不过 layout-aware 方法 |
论文给出的”理想 IE 解决方案”四条标准(也即文章贯穿始终的评价 desiderata):
高质量抽取——目标实体(公司名、地址等)的高 P/R
处理格式与语言异构性——同一系统要能处理美国法律传真、印尼便利店发票等差别巨大的模板
处理新格式——训练阶段未见过的版式不能直接失败
支持 value-absent inference(隐含值推理)——比如”line item 数量”这种文档里没有显式写出,但需要靠推理得出的实体
论文要解决的核心问题可以浓缩成一句:
如何让 LLM 在不依赖”训练集中有同格式样本”的前提下,既能利用文档版面线索、又能保留推理能力,完成对异构 VRD 的高质量信息抽取(包括隐含值推理)。
更具体地,作者把它拆成几个子问题:
怎样在 LLM 提示里”装下”足够的版面与上下文信息,而不过载?
怎样让标注训练集中的推理过程能迁移到未见格式?
怎样让小模型(7B/14B)也能够达到大模型的水平?
怎样让 LLM 做到”文档里没明写但能推出”的实体抽取?
解决办法- BLOCKIE
定义:不可再分的视觉区域。文字在空间上邻近且水平/垂直对齐,拆开就会失去含义。
举例:“TOTAL ITEMS” 是一个原子,拆成 “TOTAL” 和 “ITEMS” 后语义变模糊。
(2) Semantic Block(语义块)—— 全文最关键的定义
形式化定义:对文档 $D$ 中的某个片段 $B$,设 $v(B, C)$ 表示在上下文 $C$ 下解析 $B$ 得到的 schema 取值,则 $B$ 是语义块当且仅当:
$v(B, B) = v(B, D) = V_{\mathbb{E}}(B)$
通俗理解:语义块就是“脱离全文也能被独立正确解析”的最小自包含单元。
举例:
是语义块:(SUB TOTAL 28.000)
不是语义块:(COCONUT JELLY (L), 4.000) —— 脱离它所属的主菜行,无法判断它是不是子项、属于哪一行。
(3) Linkage(原子之间的两种链接)
attribute:value 链接:“TOTAL ITEMS” ↔ “1”
hierarchical 链接:主菜行 ↔ 它的子项
核心结论:一个语义块 = 一组语义原子,且组内每个原子的所有链接都封闭在组内。
3.2 三阶段 Pipeline(论文第 4 节)
整个流程模拟了人阅读文档的方式:先看局部 → 再拼全局。
阶段 0:Train Dataset Labeling(离线准备) 利用训练集的 key-value 标签,让 LLM(论文用 Sonnet)反向生成三样东西:
- 为什么把这段文字判为一个块的 step-by-step reason(逐步推理)
- 块内的文本
- 块对应的 partial annotation(部分填好的 schema)
这一步本质是把“标签 + schema”翻译成“块 + 推理过程”,供下游做 few-shot。
阶段 1:Block Creation(块创建)
- 输入:document schema + OCR text + bounding boxes + 用 OCR 文本余弦相似度选出来的 5 个 few-shot 块示例
- 任务:让 LLM 把当前测试文档切成若干语义块,并要求输出推理
- 关键:用训练集块的推理过程“激发”测试文档上类似的分块推理
阶段 2:Block Parsing(块解析)
- 任务:对每个块独立解析,输入 schema + 该块最相似的训练集块的 few-shot
- 优势:由于块是自包含的,不同格式的文档常常共享相似块(论文 Figure 6:法律事务所传真和便利店发票都有“联系方式块”)
- 作用:这里 schema 起到“结构化输出格式约束”的作用
阶段 3:Block Combining(块组合)
- 输入:把所有块的 partial parse + 原始 OCR 文本 + bounding boxes + schema 一起喂给 LLM
- 任务:LLM 扮演 judge,审视每个块的解析推理,把碎片拼成完整 schema 输出
- 关键:这一步处理跨块依赖(例如线性项计数)
3.3 提示策略
所有提示模板基于 Claude 3.5 Sonnet 设计,故意不针对其他 LLM 重新调参,以证明 BLOCKIE 本身的提升不是 prompt tuning 的功劳(附录 A 给了三阶段完整模板)。
实验
数据集:CORD(印尼餐饮收据,30 个层级实体)、FUNSD(表单,做 entity linking)、SROIE(扫描收据)
基模 LLM:Claude 3.5 Sonnet,Qwen 2.5 (7B/14B/32B/72B)
基线:Layout-aware(LayoutLMv3, GeoLayoutLM, ESP, ERNIE-Layout, FormNetV2, RORE-GeoLayoutLM)+ LLM(DocLLM, LayoutLLM, LMDX-Gemini Pro, Sonnet 零/少样本)
评价指标:Micro-F1
Few-shot 数量:5
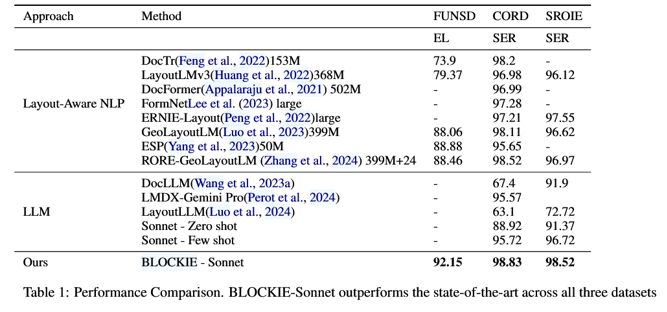
SOTA 性能验证(Table 1)
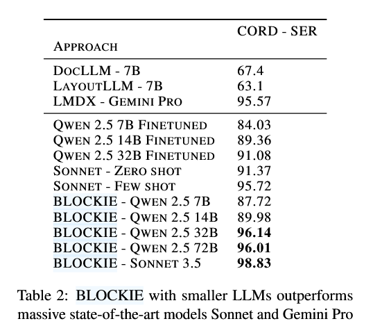

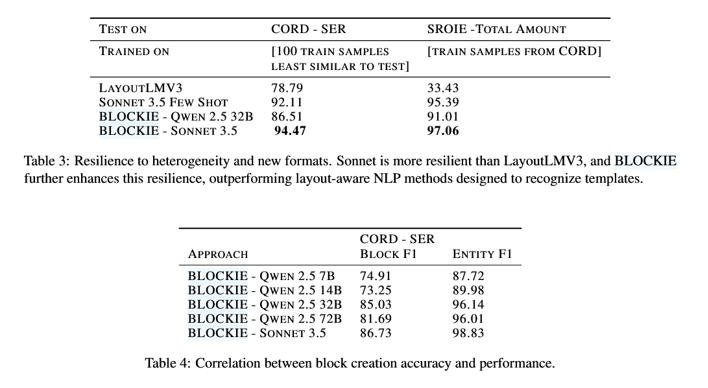
格式异构与未见格式鲁棒性(Table 3)
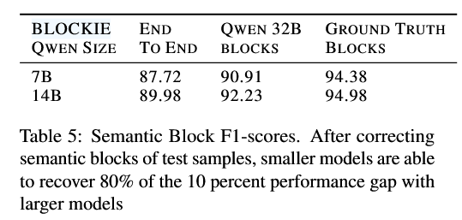
块创建是关键瓶颈(Table 4 + Table 5)
实验 1 立 SOTA → 实验 2 排除”LLM 强=方法强”的混淆 → 实验 3 验证 desiderata 中的”异构+新格式”两条 → 实验 4 定位方法内的关键模块 → 实验 5 验证 desiderata 中的”value-absent inference”。整个实验链条紧扣开篇提出的四条 desiderata,逻辑非常严密。
核心内容总结:
Semantic Block 的形式化定义 —— 第一次给 VRD 抽取里的”自包含单元”一个数学定义 v(B,B)=v(B,D)
,把”块”从直觉概念变成可验证概念
从全局推理到局部推理的范式转移 —— 不再让 LLM 一次性理解整张文档,而是分块独立推理 + 全局组合,显著降低单步任务复杂度
基于推理的训练样本组织 —— 用 LLM 把训练集标签反向生成”块+step-by-step reason”,这些 reason 在测试时通过 few-shot 迁移,等于把”如何分块/如何解析”的元知识也变成了可学习信号
跨格式的块级相似检索 —— 不同模板的文档其实共享相似语义块(传真和发票都有”联系信息块”),这让 few-shot 检索不再受限于”必须有同格式样本”
块创建瓶颈的实证定位 —— 通过 GT-block 消融实验,首次明确指出”块切对了,小模型也行;块切错了,后面救不回来”