- 作者:Chunyu Xie, Bin Wang, Fanjing Kong, Jincheng Li, Dawei Liang, Gengshen Zhang, Dawei Leng, Yuhui Yin
- 发表单位:360 AI Research
- 发表在:ICML 2025
gongchenhao
核心内容
本文围绕”CLIP 模型在细粒度视觉-语言理解上的不足”展开研究,提出了一种不修改 CLIP 架构的两阶段训练范式 FG-CLIP,通过大规模数据工程与区域级对比学习实现细粒度对齐。
论文的核心贡献可以概括为三个方面。首先,作者指出 CLIP 的两个根本瓶颈:文本编码器仅支持 77 token 的上下文窗口,无法编码细粒度长描述;全局图文对比学习只捕捉图像整体语义,忽略区域级对应关系。其次,论文构建了 FineHARD 数据集(1200 万图像、4000 万区域标注、1000 万硬负样本),首次系统性地将区域标注与硬负样本结合用于 CLIP 训练。最后,FG-CLIP 无需任何架构修改即可作为即插即用的 backbone,替换进 LLaVA 等下游模型后获得一致提升。
背景
CLIP 通过大规模图文对比学习建立了强大的零样本视觉-语言对齐能力,但其设计存在两个根本限制。第一,文本编码器的 77 token 上限导致长描述被截断,细粒度语义丢失。第二,全局 CLS token 对齐机制只能捕捉图像整体语义,无法建立区域级的精确对应。
现有改进工作如 Long-CLIP 尝试扩展文本长度,FineCLIP 引入区域级标注,但均未同时解决文本长度与区域对齐问题,且缺乏硬负样本来训练模型区分细微语义差异(如”红色杯子”vs”蓝色杯子”)。
技术方法
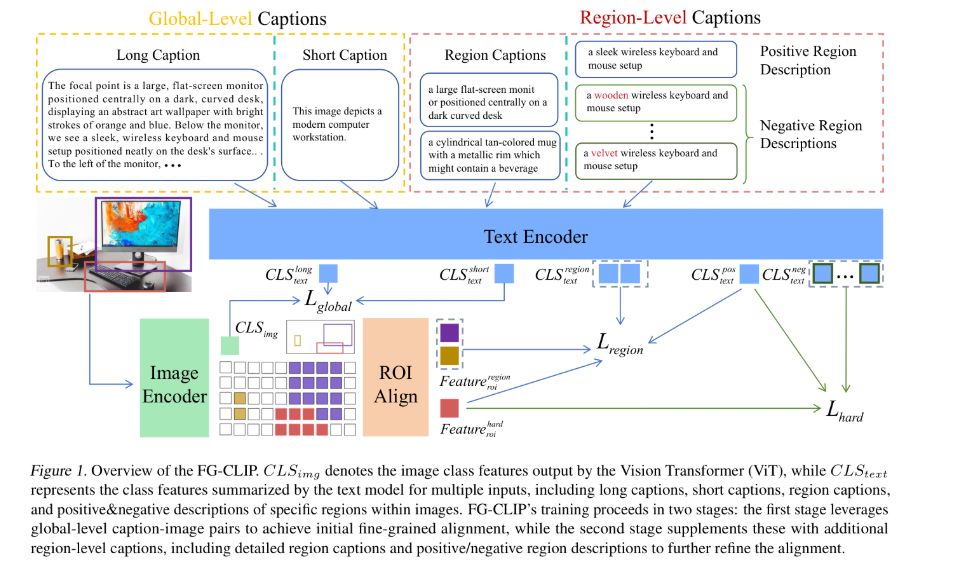
FG-CLIP 的训练分为两个阶段:
第一阶段:全局对比学习
利用 CogVLM2 对 16 亿图文对重新生成详细长 caption(约 100-200 词),将文本位置编码从 77 扩展至 248 token。训练目标 L_global 同时对齐长 caption 和短 caption 与图像 CLS 特征,使模型在保持原有短文本理解能力的同时获得长文本编码能力。
第二阶段:区域对比 + 硬负样本学习
基于 FineHARD 数据集,引入两个新的训练目标:
- L_region:通过 RoIAlign 从 ViT 特征图提取区域特征,与对应的区域文本描述对齐
- L_hard:利用 Llama-3.1-70B 生成属性篡改的硬负样本(修改颜色、材质、数量等),强制模型在正/负描述之间进行细粒度区分
关键设计在于硬负样本的构造策略——不是随机打乱,而是通过 LLM 精准篡改单一属性,使负样本与正样本仅有微小语义差异,迫使模型学习真正的细粒度区分能力。
实验
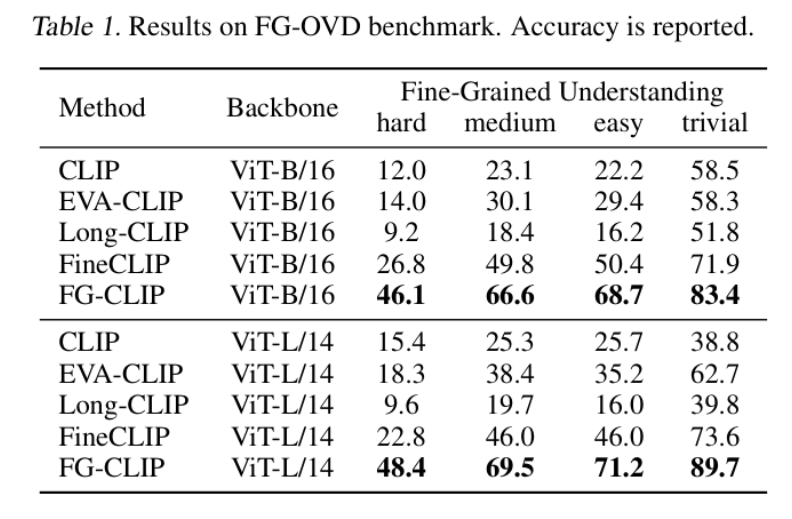
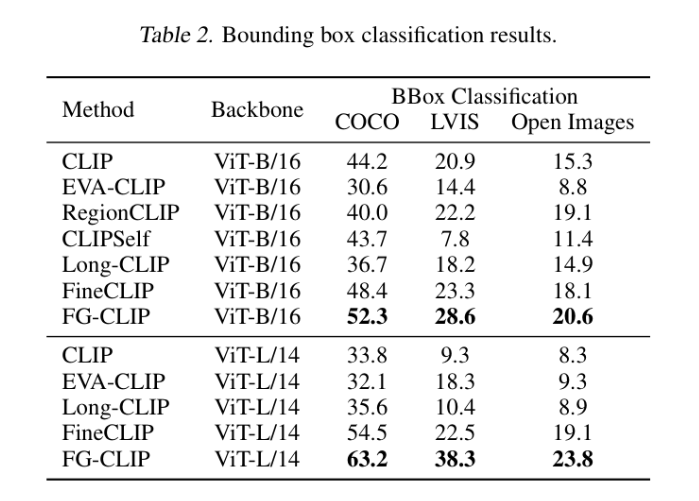
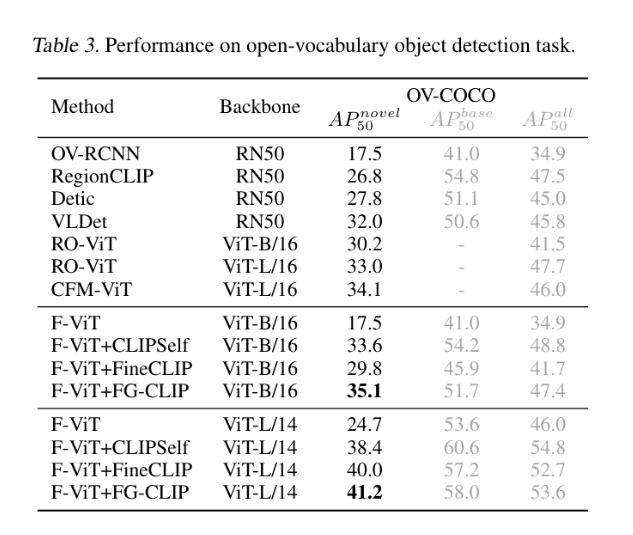
主要结果(见上图 Tables 1-3):
- FG-OVD 细粒度基准:hard accuracy 从 22.8%(FineCLIP)提升至 48.4%,提升幅度超过一倍
- Bbox 分类:COCO 上 63.2%(ViT-L/14),比 FineCLIP 高 8.7 个点
- 开放词汇检测:OV-COCO AP_novel_50 达到 41.2,超越所有对比方法
- 图文检索:ShareGPT4V I2T 达 97.4%,MSCOCO I2T 达 68.9%
- 零样本分类:ImageNet-1K 达 81.1%(ViT-L/14)
- 多模态大模型:替换进 LLaVA-v1.5 后 RefCOCO testB 提升 7.0 个点
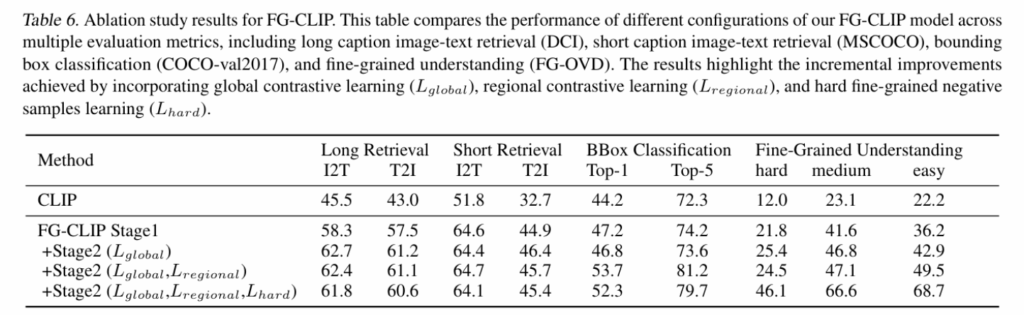
消融实验(Table 6)清晰展示了各组件的贡献:Stage 1 全局对比打基础,L_region 引入区域对齐,L_hard 带来最大增益(hard accuracy 从 24.5% 到 46.1%)。
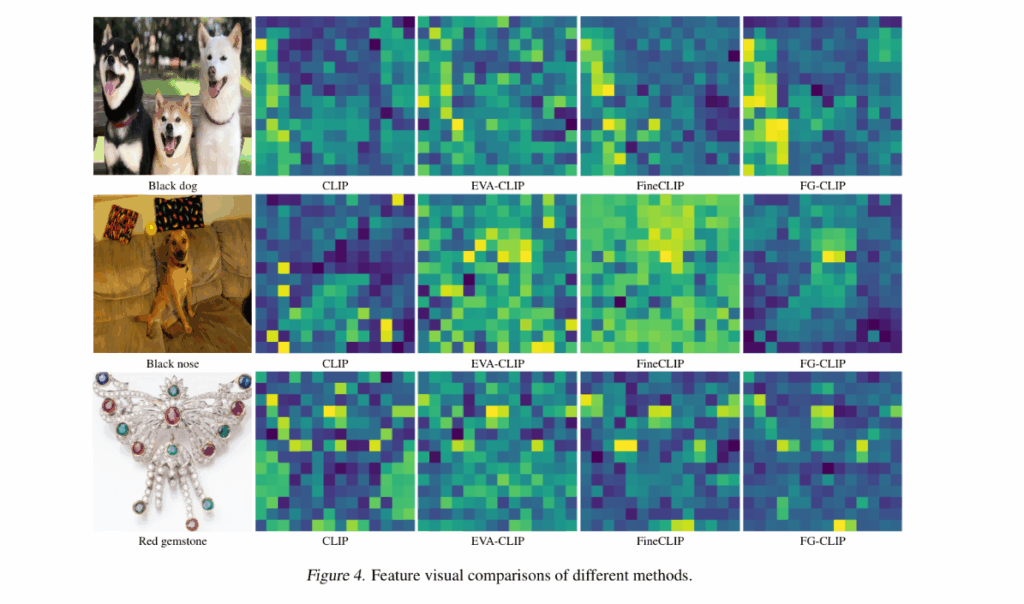
特征可视化(见上图 Figure 4)直观展示了 FG-CLIP 相比 CLIP、EVA-CLIP、FineCLIP 在区域定位上的精确性——对”black dog”、”red gemstone”等查询能精准激活对应区域。
结论
- FG-CLIP 证明了在不修改 CLIP 架构的前提下,通过大规模高质量数据构建(16 亿重标注 + 1200 万区域标注)和精心设计的训练策略(三阶段 loss),可以显著提升细粒度视觉-语言对齐能力。这一”数据驱动而非结构驱动”的路线对预训练模型改进具有普适意义。
- 硬负样本学习是最关键的技术贡献。消融实验表明 L_hard 贡献了最大性能增益,说明在对比学习中构造高质量的困难样本比增加数据规模更为重要。这与 NLP 领域对比学习的经验一致。
- 作为即插即用 backbone 的泛化性是其工程价值所在:无需修改下游模型架构,只需替换视觉编码器即可获得一致提升。
启发与评价
- 方法创新点【数据工程驱动的细粒度对齐】:核心贡献不在模型架构,而在数据构建方法论——用 VLM 生成长 caption、用 LLM 生成硬负样本,本质上是用更强的模型来教更高效的模型。16 亿级别的重标注规模远超此前工作,体现了”数据即模型”的思路。
- 技术目标点【区域级视觉-语言对齐】:FineHARD 数据集首次系统性地将区域标注、区域描述与硬负样本三者结合,为细粒度 CLIP 训练提供了标准化的数据范式。hard accuracy 翻倍的提升证明了这条路线的有效性。
- 中试产品点【食养通】:FG-CLIP 的区域级理解能力可直接用于食材识别场景——对”红枣”vs”干枣”、”嫩姜”vs”老姜”等细粒度食材区分可能有帮助;但其训练数据以通用物体为主,食材领域需要额外微调。