- 作者:Tianzhe Zhao 等
- 发表单位:西安交通大学、曼彻斯特大学、湖南大学、新加坡国立大学等
- 发表在:ACM SIGIR 2026
核心内容
本文围绕“大语言模型在多源知识冲突场景下的推理可靠性问题”展开研究,系统性地提出了一个新的研究方向:跨知识源冲突下的推理机制分析。
论文的核心贡献可以概括为三个方面。首先,作者指出当前 RAG 系统在整合多源知识(如文本与知识图谱)时,会不可避免地引入冲突信息,而现有方法缺乏对这类冲突的系统研究。其次,论文构建了一个新的基准数据集 ConflictQA,用于系统评估模型在跨来源冲突场景下的表现。最后,作者提出了一种两阶段推理框架 XoT(Explanation-based Thinking),通过显式拆解推理过程来提升模型在冲突场景中的表现。
整体而言,这篇论文不仅提出了一个新的问题设定,还提供了标准化评测方式以及初步解决方案,具有较强的研究完整性。
背景
随着 RAG(Retrieval-Augmented Generation)的广泛应用,LLM 逐渐从“纯参数知识”转向“依赖外部知识”的推理范式。在这种范式下,模型能够利用文本、知识图谱等多种异构数据源,从而提升知识覆盖范围与推理能力。
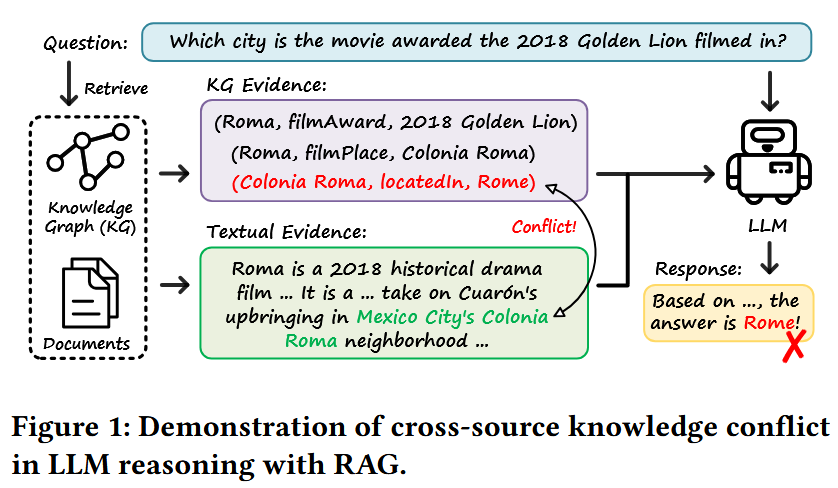
然而,这种多源融合也带来了新的问题。在真实环境中,不同来源的知识往往存在不一致,例如文本描述可能过时、噪声较大,而知识图谱中的事实也可能存在错误或不完整。这些因素会导致模型在推理过程中接收到相互矛盾的证据。
现有研究大多关注两类冲突:一类是模型内部参数知识与外部知识之间的冲突,另一类是在单一知识源内部人为构造的冲突。然而,对于“不同外部知识源之间的冲突”,尤其是文本与知识图谱之间的冲突,仍然缺乏系统性研究。
本文正是在这一背景下提出,旨在填补“跨来源知识冲突”这一重要但被忽视的研究空白。
技术方法
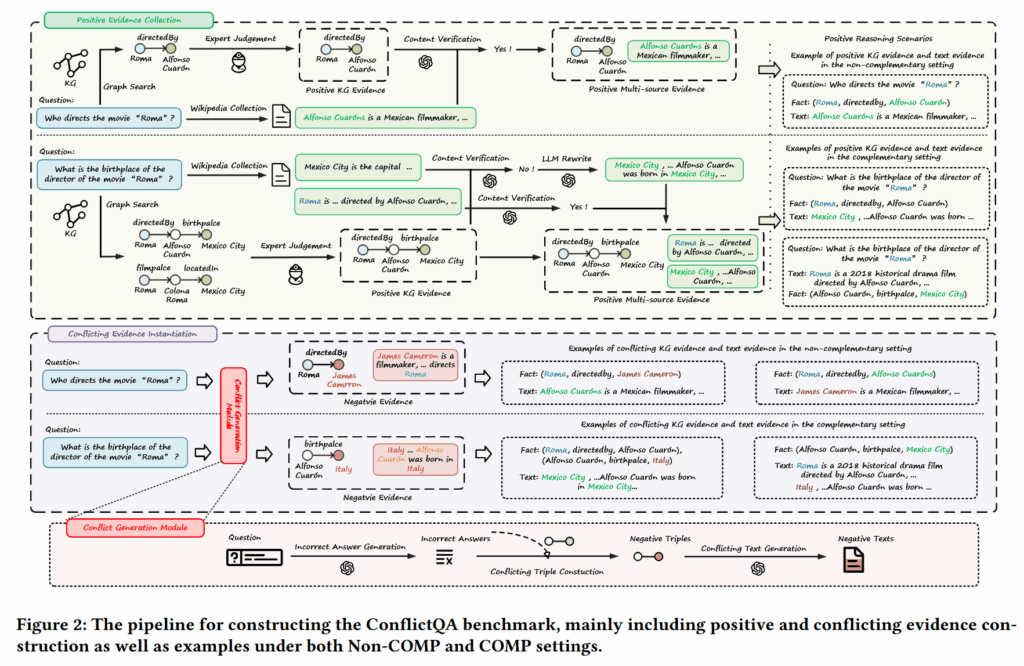
论文的方法主要包括两个部分:ConflictQA 基准构建与 XoT 推理框架。
- 构建 ConflictQA 基准:该基准基于现有 KGQA 数据集,通过两步流程生成
- 第一步是构造“正确信息”,从知识图谱中通过图搜索获取支持答案的三元组,并从 Wikipedia 中提取对应文本描述,同时通过人工或 LLM 验证其一致性。
- 第二步是构造“冲突信息”,通过替换实体生成错误的知识图谱三元组,并利用 LLM 生成与之对应的错误文本,从而形成语义合理但事实错误的证据。
在此基础上,作者定义了两类冲突场景:
- Non-COMP(非互补场景),即任一知识源单独即可回答问题;
- COMP(互补场景),即需要同时结合文本与 KG 信息才能完成推理。
此外,还区分了 TextConf 与 TripleConf 两种冲突来源,用于分析不同类型冲突对模型的影响。
在方法层面,论文提出了 XoT 推理框架。该方法的核心思想是将传统的“直接生成答案”过程拆分为两个阶段:
- 第一阶段要求模型枚举所有可能的候选答案,并为每个答案生成解释;
- 第二阶段则基于这些解释进行综合判断,从而选择最终答案
通过这种方式,模型能够避免在早期阶段对某一类证据产生偏置,从而提升推理的稳定性。
整体来看,技术方法的关键在于:将“冲突问题显式化”,并通过结构化推理流程缓解模型的隐式偏好。
实验
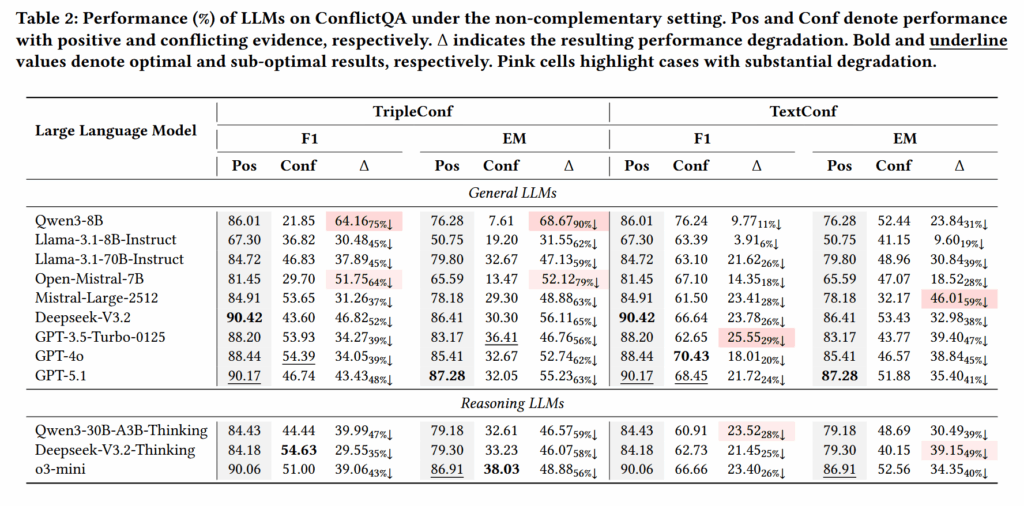
实验结果表明,在存在跨来源冲突的情况下,所有主流大语言模型的性能均出现显著下降,部分场景下 Exact Match 甚至下降超过 60%。这说明当前模型在面对冲突信息时缺乏可靠的判断机制。
进一步分析发现,模型在推理过程中存在明显的“证据偏好”。在直接问答提示下,模型更倾向于相信结构化且简洁的知识图谱三元组;而在使用 Chain-of-Thought 提示后,则更容易受到文本信息的影响。这种偏好表明模型并非真正理解证据的可靠性,而是在不同信息形式之间进行启发式选择。
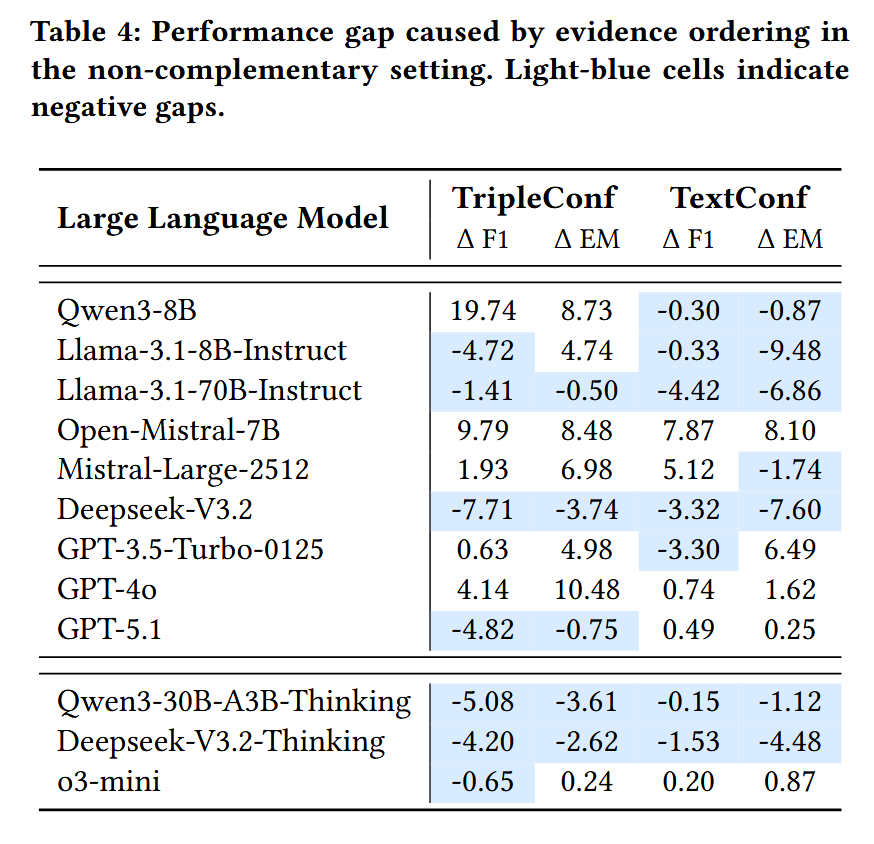
此外,实验还发现模型对证据顺序较为敏感,进一步说明其推理过程缺乏全局一致性。
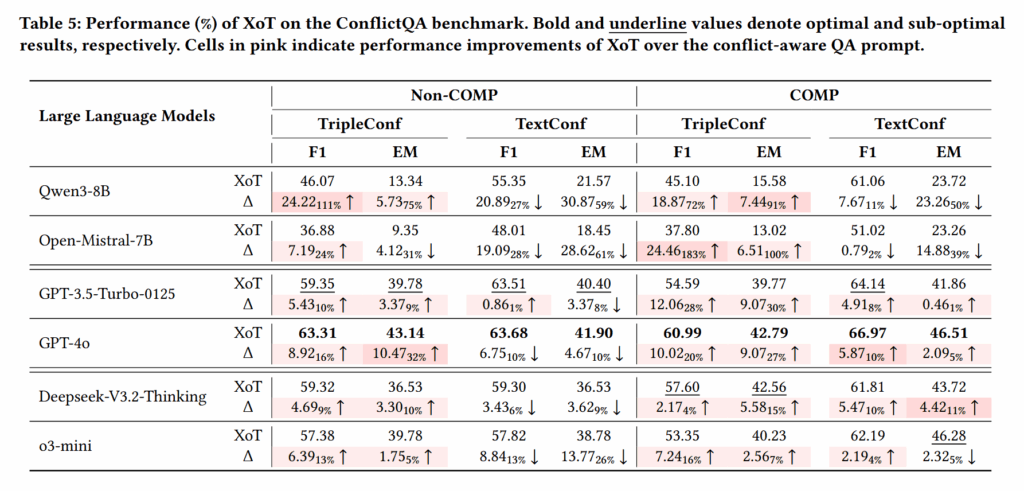
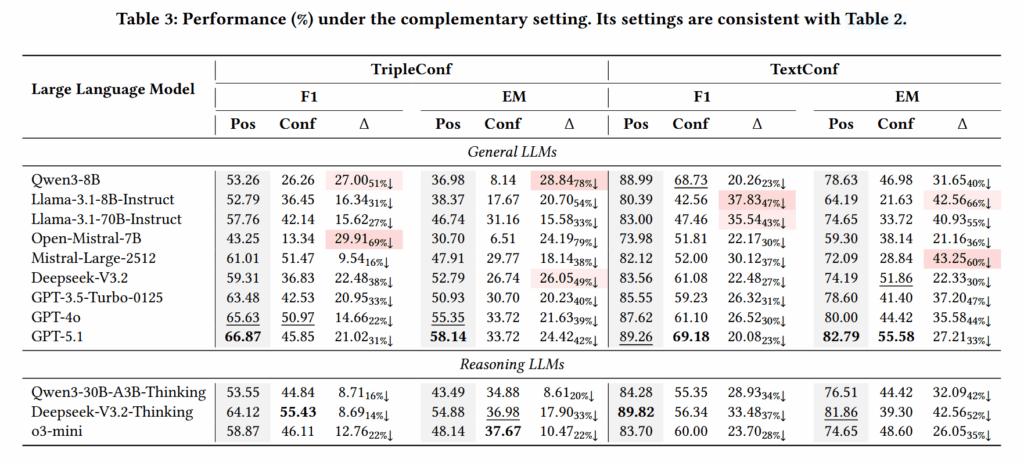
在方法方面,XoT 在多数场景下能够有效提升模型表现,尤其是在知识图谱冲突场景中表现较为稳定。但在文本冲突场景下,提升效果不稳定,说明模型仍然难以评估复杂文本信息的可靠性。
结论
- 本文系统性地研究了大语言模型在多源知识冲突场景下的推理问题,重点关注来自文本与知识图谱等异构外部知识之间的不一致性对模型推理行为的影响。通过构建 ConflictQA 基准,本文首次从跨来源冲突的角度,对 LLM 的推理能力进行了系统评估,揭示了当前模型在面对冲突信息时普遍存在的可靠性不足问题。
- 研究表明,现有 LLM 在处理冲突证据时缺乏稳定的判断机制,推理过程容易受到证据形式、提示策略及信息呈现方式的影响,反映出其在证据可信度建模与冲突解析能力方面的不足。针对这一问题,本文提出了 XoT 推理框架,通过将推理过程拆分为候选生成与解释驱动决策两个阶段,在一定程度上缓解了模型的偏置问题,提升了推理的稳健性。
- 总体而言,本文从问题定义、基准构建与方法探索三个层面,推动了对“跨来源知识冲突”这一关键问题的理解。未来工作可进一步从知识表示与结构建模角度出发,构建更具可控性与可解释性的推理机制,以实现更加可靠的多源知识融合与推理。
启发与评价
- 方法创新点【逻辑思维推理框架】:发现了 LLM 在冲突发生的时候普遍倾向于认同 KG 证据并且否定文本证据,从而导致错误的发生;而现有研究几乎没有关注异构知识数据的冲突问题。基于此他们建立了一个冲突数据集来填补这部分空白。这对于多种知识数据联合推理来说很有意义。
- 技术目标点【跨域知识结构对齐】:区分了含有干扰项和必须联合推理的两类问题,研究了两种东西的相互影响
- 中试产品点【食养通】:这种替换实体的方法可能不是很适合构建适用性问题的 benchmark