作者:Jan Drole, Ana Gjorgjevikj, Barbara Koroušić Seljak, Tome Eftimov等
单位:Jožef Stefan International Postgraduate School Jožef Stefan Institute等
来源:IEEE BigData 2025 proceedings
时间:arXiv: 2603.09758v1,2026.03.10
链接:[Beyond Fine-Tuning: Robust Food Entity Linking under Ontology Drift with FoodOntoRAG]
一. 研究背景
在食品智能分析里,很多后续能力其实都建立在一个非常基础、但又非常容易被忽视的前提上:系统到底能不能先把“食品是什么”识别清楚。
现实中的食品文本并不规范。配料表、菜单、商品标签里常常会同时出现俗称、别名、技术名、法规名、跨地区表达,甚至同一个词在不同语境下还可能指代不同层级的概念。比如一个词有时表示具体食材,有时表示更泛的品类,有时又只是地域或加工方式描述。对模型来说,这并不只是一个简单的自然语言理解问题,而是一个“语言表达 + 领域本体 + 术语标准化”的复合问题。
这篇论文的价值,就在于它没有继续沿着“针对某个固定数据集、固定本体版本去微调模型”这条常见路线走下去,而是进一步提出:如果食品知识本体本身会变化,术语会扩展,标注粒度会漂移,那么比起不断重训练,更可持续的方式是把知识放到可检索的外部本体里,让模型基于证据去做判断。
作者把这个问题概括为 ontology drift,也就是本体演化带来的概念和层级变化。在这种背景下,传统微调模型很容易被旧版本知识绑定,而 FoodOntoRAG 则试图用检索增强和结构化证据推理,构建一个对本体变化更稳健的食品实体链接框架。
二. 论文概要
作者关注的问题是 food entity linking,也就是如何把自然语言中的食品实体,映射到像 FoodOn 这样的标准本体概念上。
这项工作看似只是一个“标准化”问题,但实际上非常关键。因为无论后面是做营养估计、健康风险识别、食品知识互操作,还是商品之间的对标分析,前提都是先把“原始食品文本”转成统一、可比较、可计算的标准语义对象。
论文提出的 FoodOntoRAG,本质上是一套 few-shot 的食品实体链接流程。它不依赖专门为某一个本体版本微调模型,而是从本体中检索候选概念,再把标签、同义词、定义、关系等结构化证据提供给大模型,由模型在候选范围内做选择、评分和必要的回退重试。作者希望用这种方式,替代“知识写死在参数里”的闭环方案。
论文还给出了两个层面的验证:
一是在标准的食谱类数据集 CafeteriaFCD 上测试其链接表现;
二是在更贴近真实商品场景的 Open Food Facts 配料表数据上,对比它和监督微调模型 FoodSEM 的差异。
从结果看,FoodOntoRAG 在真实品牌食品场景里的优势尤其明显,这一点也让这篇论文不只是“方法上有想法”,而是对真实食品数据处理具有较强启发意义。
三. 方法框架
这篇论文最核心的做法,不是重新设计一个全新的食品大模型,而是把食品实体链接拆成了一条更稳健的推理链:
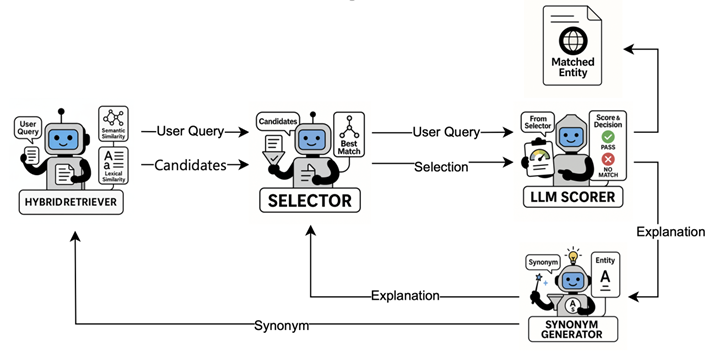
原始 mention 输入 → 混合检索召回候选 → LLM 选择最优实体 → LLM 评分校验 → 同义改写后重试
作者把这套流程称为 FoodOntoRAG。它由四个模块组成:Hybrid Retriever、Selector、LLM Scorer、Synonym Generator。论文第 3 页的流程图把这四个阶段及其回路关系画得很清楚:先检索,再选择,再评分,如果信心不足就触发同义词改写后重新检索。
这一步非常重要。它意味着论文并不是在证明“LLM 自己就会做食品实体链接”,而是在证明:只要让模型基于本体证据而不是只靠参数记忆,它就能在更开放的食品知识环境里做出更稳的判断。
这也是我认为这篇论文最有参考价值的地方。
1)它把检索和判断拆开了
FoodOntoRAG 的第一步是混合检索。作者同时使用了 Whoosh 词法检索 和 FAISS 向量检索:
前者主要依赖标签、同义词、定义等字段做 BM25 检索;
后者用 all-MiniLM-L6-v2 对实体文本做向量表示,再基于语义相似度召回候选。
这种设计兼顾了“字符串很像”和“语义很像”两类情况,能更好应对食品领域里常见的别名、缩写和表达变体。
2)它把“选一个最像的”与“判断这个对不对”拆成了两个角色
论文没有让一个 LLM 一步做完所有事,而是设计了 Selector 和 Scorer 两个分离的代理。
Selector 的任务是:在候选列表里找出最可能的那个;
Scorer 的任务是:再判断这个结果到底是不是一个真正合理的匹配,并给出 0 到 1 的置信度。
作者特别强调,二者分离后效果更稳定,因为“最像的候选”并不总等于“语义上真正正确的匹配”。这其实很符合真实食品语义场景:候选集中经常会有表面相近、但概念类别不同的项。
3)它不是只做实体匹配,还做失败后的语义回退
当 Scorer 认为当前结果不够可靠时,系统不会直接结束,而是会调用 Synonym Generator,根据失败原因生成新的表达方式,再进入下一轮检索。
例如,一个成分可能用技术名写在本体里,但在商品包装上只出现通俗叫法;或者相反,包装里写的是化学名,而用户更习惯日常表达。这个时候,同义词生成器就承担了“术语桥接”的作用。
论文同时限制这个回退只进行一跳,避免在反复改写中逐渐偏离原意。
四. 实验设计与评估
从论文给出的结果看,FoodyLLM 在营养估计、交通灯分类和本体链接这三类任务从论文给出的结果看,FoodOntoRAG 的价值并不只是“能跑通流程”,而是它在不同评测条件下都展示了比较鲜明的特点。
在 CafeteriaFCD 数据集上,作者用 948 个 unique mentions 做评估。在严格 exact-match 的口径下,FoodOntoRAG 的准确率大致稳定在 57% 到 60% 之间。这个数字本身不算特别夸张,但它的意义在于:在没有做专门微调的情况下,依赖检索增强和证据判别,系统仍然保持了稳定表现。
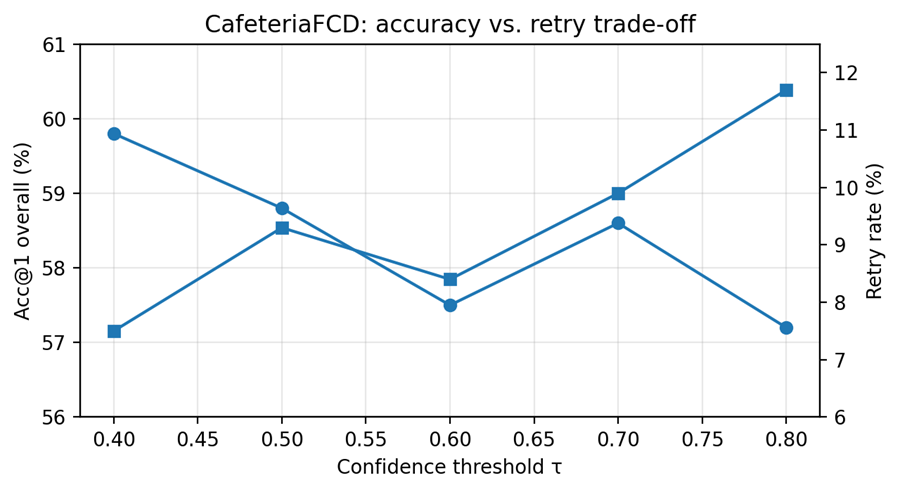
同时论文分析了不同置信度阈值下的表现,发现随着阈值上升,系统会更保守,触发 retry 和 synonym loop 的比例会上升,但准确率提升并不明显,因此大约 0.6 到 0.7 是相对合适的折中区间。
但这篇论文更有价值的地方,是它没有把“和 gold CURIE 不完全一样”简单视作模型错误。作者进一步对 381 个 mismatch 做了 ontology-aware 的复核。结果发现,其中 293 个,也就是 76.9%,可以重新归为 Exact_Match;还有一部分属于 Synonym_or_Lexical 或 Class_vs_Taxon,也就是同义表达差异或者层级/类型差异,而不是真正语义错误。真正被归类为 Model_Incorrect 的只有 35 个,占 9.2%。
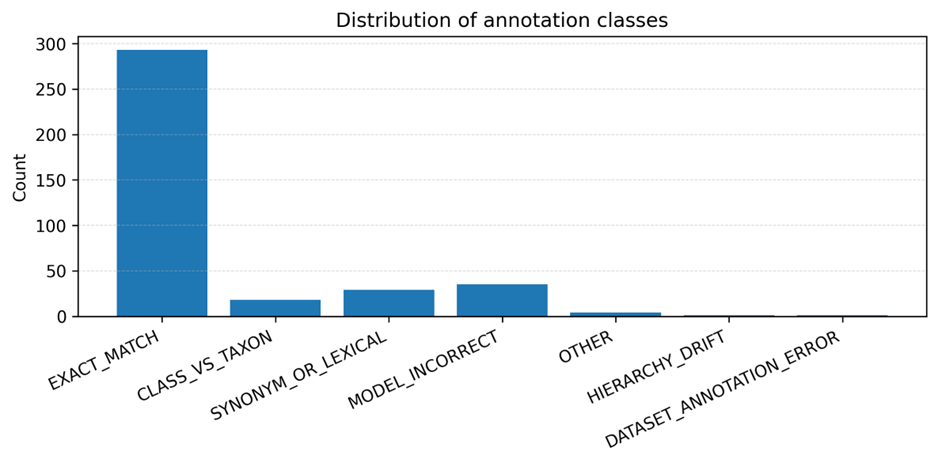
这说明一个非常重要的问题:在食品实体链接任务中,很多表面上的“错”,其实是因为评测集只允许一个标准答案,而真实本体世界里可能存在多个语义上成立的表示方式。 论文在完成这种复核后,报告最终准确率可达到 97%。
在更贴近真实世界的 Open Food Facts 配料表数据上,FoodOntoRAG 的优势更加明显。
作者将其与监督微调模型 FoodSEM 做比较,结果显示:FoodOntoRAG 的准确率达到 90.7%,而 FoodSEM 只有 36.9%;第二位标注者复核时,FoodOntoRAG 依然有 83.3%,FoodSEM 为 29.2%。
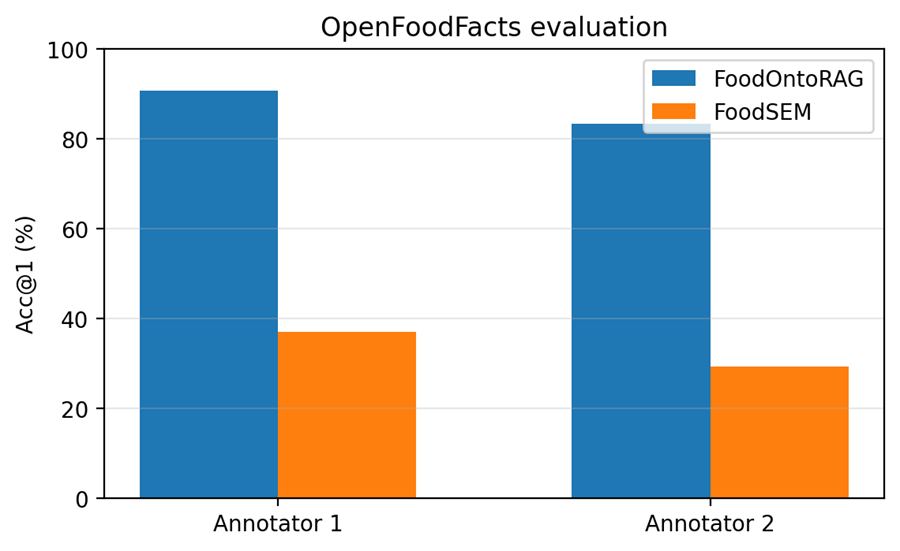
论文解释说,FoodSEM 主要在食谱型训练数据上学习到食品成分映射,而真实商品配料表中还包含大量添加剂、色素和化学成分,这些实体超出了它的训练分布,因此泛化明显较弱。这个结果说明,如果目标场景是开放世界的真实商品语料,那么依赖检索增强的实体链接方法,比只依赖训练样本分布的微调模型更稳健。
如果把这篇论文映射到“食品评分 / 健康评估 / 性价比判断”这类系统中,我觉得它最有价值的地方不是直接输出最终评分,而是提供了一个非常清楚的上游语义标准化层设计:
食品文本解析 → 配料实体归一 → 本体映射 → 结构化食品知识表示 → 下游营养推理与评分解释
这条链路虽然不直接等于完整的食品评估系统,但几乎可以直接迁移到更大的食品智能框架中。其中:
- 本体映射可以支撑品类识别、别名归一、添加剂标准化
- 结构化实体表示可以支撑知识检索与规则判断
- 后续再叠加营养估计、价格归一、规格换算和同类商品比较,就能进一步形成健康度与性价比分析体系
也就是说,FoodOntoRAG 很适合承担“从原始食品文本到标准化知识实体”这一层,但它本身并不等于完整的消费决策系统。论文聚焦的是实体链接和本体漂移鲁棒性,并没有直接处理营养补全、价格推理和商品价值判断。
五. 对齐思考
FoodOntoRAG 当前最擅长处理的是:把食品文本中的实体表达稳健地链接到本体概念上。
但现实中的包装食品场景仍然更复杂。一个商品可能只有配料表,没有精确比例;可能存在复合配料、品牌专有表述、法规简称、营销化命名,甚至同一个词在不同品类中含义都不同。在这种情况下,即使实体归一化做得很好,系统距离完整的商品评估仍然还有几步。论文也很诚实地指出,它的重点并不是营养推断或价格分析,而是先把食品语义标准化这一步做好。
本文构建了一条清晰的食品实体链接推理链:原始 mention 输入 → 候选召回 → 实体选择 → 置信校验 → 同义重试 → 结构化输出。
它提供了一个非常值得复用的基础框架:先把配料表、商品名称、菜单文本中的原始术语,转成标准化、可检索、可计算的本体实体,再进一步衔接营养分析、风险识别和评分解释。论文也明确了 LLM 在这个问题上的合理定位:适合做证据归纳、候选判别和语义解释,不适合在缺乏知识支撑时直接“猜”标准概念。因此,在系统设计上,更稳妥的方案是采用“检索负责召回知识,LLM 负责基于证据推断”的分层思路。
论文对应的核心目标是:提升食品术语标准化能力,增强食品知识表示在开放场景中的稳定性和可解释性。
映射到公众服务或食品智能分析场景,就是让系统先把食品成分、别名、添加剂和相关概念“看懂、对齐、链准”,再面向用户给出营养解读、风险说明和比较分析。这篇论文没有覆盖价格与性价比问题,因此对本课题的启示是:它非常适合作为“食品语义理解与标准化底座”,再额外挂接营养估计、价格规范化、同类对标和综合评分模块。
这篇论文可以映射为一条可落地链路:食品解析 → 配料标准化 / 本体映射 → 标准化知识实体构建 → 营养与规则模块接入 → 评分 / 性价比解释。
其中,本体映射可支撑品类识别、别名归一、添加剂规范识别与跨数据库对齐;如果进一步结合营养表、价格信息、单位换算与同类商品比较,则可以继续扩展到健康度和性价比分析。
需要注意的是,FoodOntoRAG 解决的是“术语标准化”和“本体链接稳健性”问题,并不直接处理商品中配料比例缺失、品牌配方差异、价格波动和价值判断逻辑。因此,如果主要面向包装食品评估场景,还需要在它之上补充:营养补全、商品级属性约束、价格归一化以及评分解释模块。