来源: 2025, arXiv
作者: Sajjad Shahabodini, Mobina Mansoori, Farnoush Bayatmakou, Jamshid Abouei
一、论文主要工作
目前基于掩模的方法通过捕捉全局背景来产生高质量的掩模。然而,如何确地对这些掩码进行分类,特别是在边界模糊和类别分布不平衡的情况下,仍然是一个开放的挑战。这篇文章介绍了一种新的两阶段分割框架VIT-P,它将掩码生成与分类分离。
第一阶段使用命题生成器来产生经典掩码,而第二阶段利用 VIT上的基于点的分类模型来改进预测。
VIT-P充当无需预训练的适配器,允许集成各种预先训练的VIT,而无需修改其架构,确保对密集预测任务的适应性。
二、模型
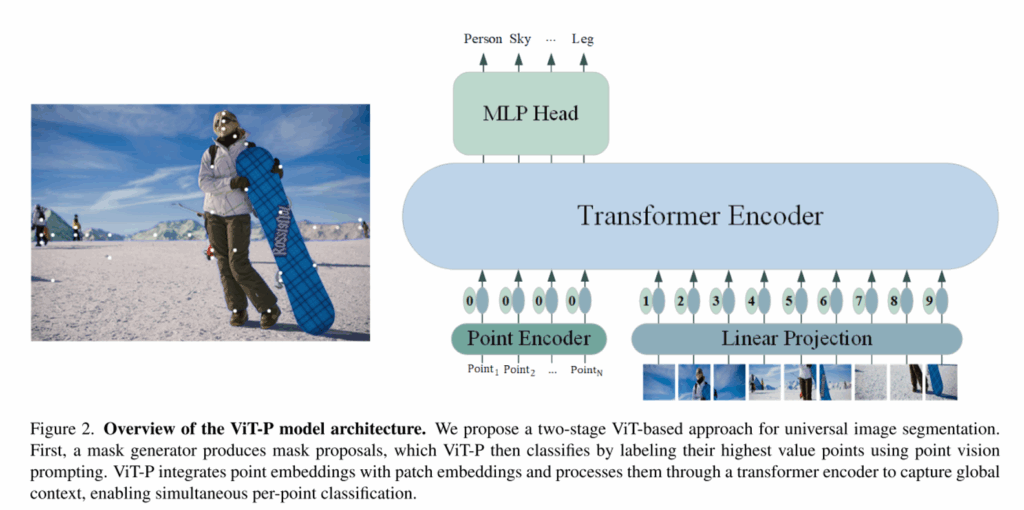
三、实验结果
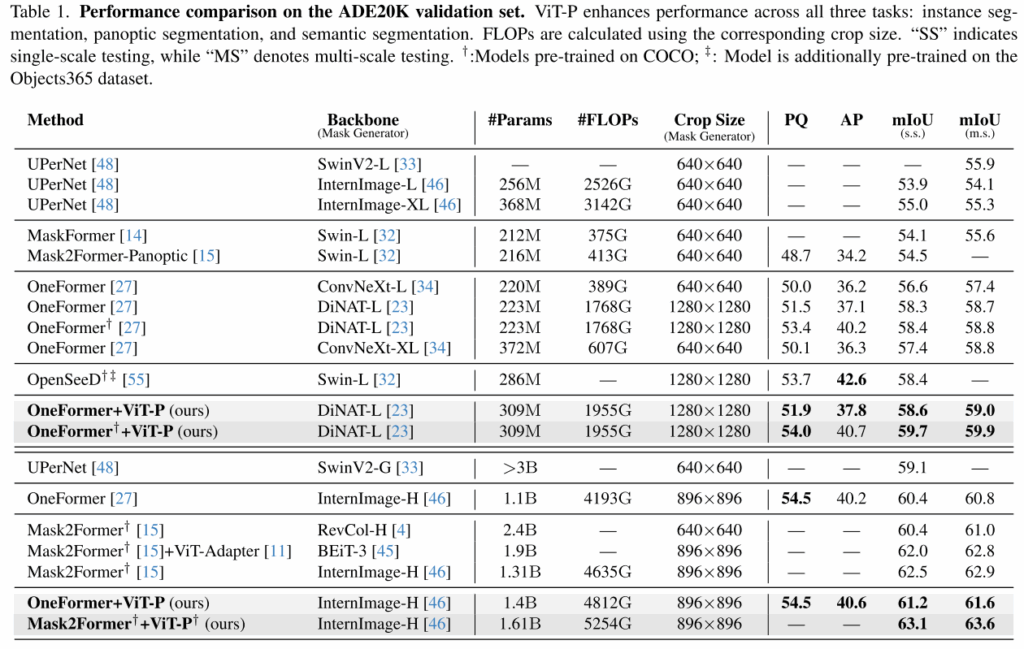
四、总结
课题综合对齐思考:
技术创新—数据拓扑标签计算:这篇研究贡献点在于改进VIT网络,做一个点的分类预测,并不存在数据拓扑标签计算。
技术目标—跨域知识结构对齐:这篇研究并不包含明显的跨域知识结构对齐。
场景功能—食养通:可以用于食物图片的分割。