- 作者:Peng Q, Cui J, Xie J, et al.
- 发表单位:南方科技大学、香港理工大学
- 发表在:ACM MM 2025
核心内容
- 大型语言模型(LLM)在医学领域显示出巨大的潜力。然而,现有模型在面对现实世界中复杂的医疗诊断任务时仍然存在不足。这主要是因为它们缺乏足够的推理深度,导致在处理大量专业医学数据时出现信息丢失或逻辑跳转,从而导致诊断错误。
- 提出了推理树(ToR),这是一种多 Agent 框架,旨在处理复杂的场景。具体来说,ToR引入了树形结构,可以清晰地记录LLM的推理路径以及相应的临床证据。同时,作者提出了交叉验证机制来保证多智能体决策的一致性,从而提高多 Agent 在复杂医疗场景下的临床推理能力。
- 医疗数据的实验结果表明,本文的框架可以实现比现有基线方法更好的性能
背景
- LLM 在医学问题上获得了很多的关注,可以通过推理大大提升临床决策的效率,减轻医生负担。但是作者质疑现有的工作都专精于医学考试里面的某类问题,可泛化性不够。
- 现实中来说,医生经常通过多学科会诊来诊治癌症这样的牵连多学科的疾病。受此启发,很多多智能体方案被开发出来了。但是作者认为现有的多智能体方法有这些问题:(1)不提供可解释证据链,这在医学这种领域是难以接受的;(2)不同的智能体之间的冲突会增加推理不确定性,提高生成问题建议的风险。
- 作者同时受到了循证医学方法的启发,提出了这样一个方法来提高可解释性以及解决智能体之间的冲突。
技术方法
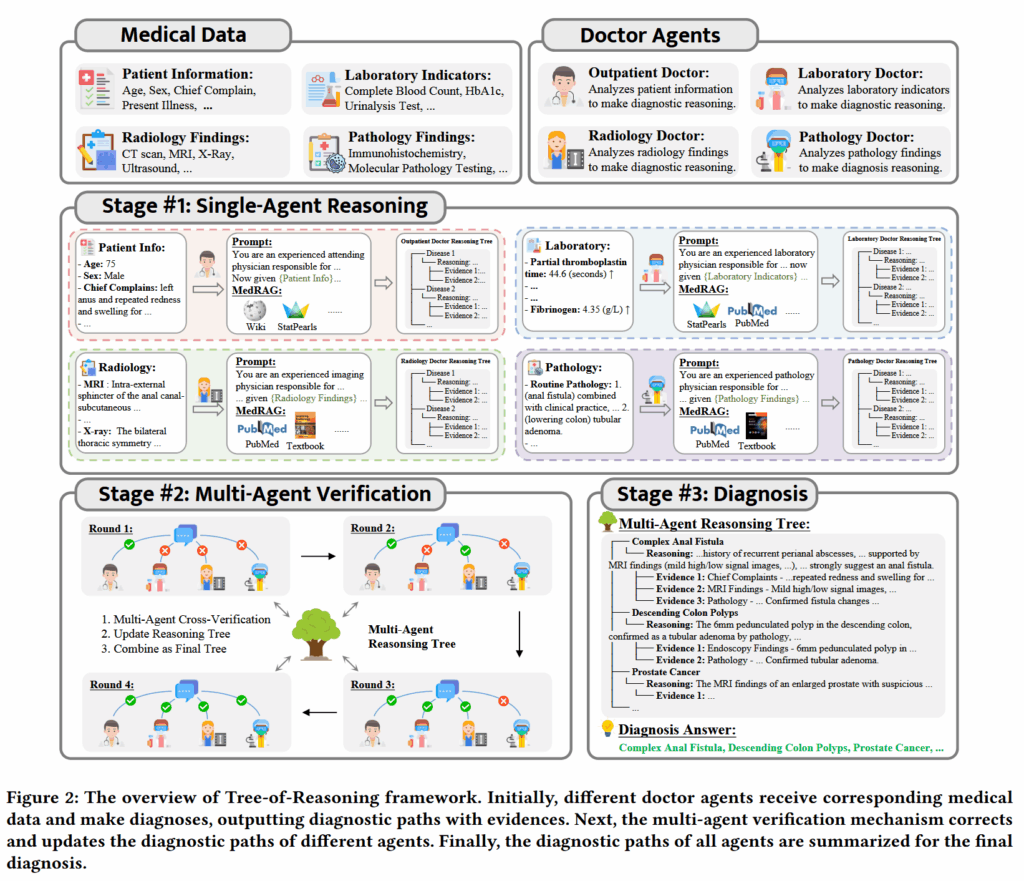
推理树
为了解决 AI 诊断“黑箱化”的问题,作者提出将推理过程写成一棵“树”:
- 第一层 (根节点):初步诊断结果(如:肺癌)。
- 第二层 (中间节点):推理路径(解释为什么得出这个诊断)。
- 第三层 (叶子节点):具体的临床证据(对应的症状、具体的化验数值或影像描述)。
类似这种:
┌── 肺结核 (Tuberculosis)
│ └── 推理分析:患者有2周咳嗽史,伴随乏力和消瘦,且影像学显示右肺上叶模糊阴影,
│ 虽然痰找抗酸杆菌阴性,但临床表现高度疑似。
│ ├── 证据 1: 临床症状 - 持续2周的咳嗽和近期体重下降5kg。
│ ├── 证据 2: 影像学发现 - X光显示右肺上叶有边缘模糊的阴影。
│ └── 证据 3: 实验室检查 - C反应蛋白(CRP)升高至 45 mg/L。
└── ... (其他鉴别诊断)
它不是直接给一个概率分数,而是把 AI 内部的推理链路可视化了,方便医生快速复核。在多智能体讨论阶段,如果病理科智能体发现证据 3 其实指向的是肿瘤而非结核,Agent 可以直接针对这个具体的树枝提出反驳,并更新该节点。
角色分工
ToR 框架通过模拟医院里的多学科团队 (MDT) 协作模式,让不同的 AI 智能体扮演不同的医生角色,共同分析患者病例。框架内设计了四种专业医生智能体,每个智能体只关注其擅长领域的医学数据:
提供显式的证据、推理和诊断。他们设计了 4 个子智能体,分别扮演门诊、检验科、影像科、病理科四大部门的医生来联合会诊。然后定义了推理树,一棵自顶向下分别是初步诊断、推理路径和临床证据的树。每个智能体先生成自己的推理树,然后发生冲突时多个智能体互相辩论,达成共识后生成综合诊断。
- 门诊医生 (Outpatient Doctor):分析患者的临床症状、体格检查结果和既往病史。
- 检验科医生 (Laboratory Doctor):分析血液、尿液、生化指标等实验室检测结果。
- 影像科医生 (Radiology Doctor):分析 X 光、CT、MRI、超声等影像学发现。
- 病理科医生 (Pathology Doctor):分析活检组织、细胞涂片等病理诊断结果,确定肿瘤类型和分级。
三阶段工作流
ToR 的运行分为三个关键阶段:
- 第一阶段:单智能体推理 (Single-Agent Reasoning)
每个“医生”根据自己领域的资料,初步生成自己的推理树。 - 第二阶段:多智能体交叉验证 (Multi-Agent Verification)
这是最核心的步骤。当不同医生的结论出现冲突时(例如:影像科觉得像结核,但病理科觉得像肺癌),他们会进入讨论和辩论模式。智能体会相互审阅对方的推理路径和证据,修正错误,补充遗漏的信息。 - 第三阶段:综合诊断 (Final Diagnosis)
经过多轮讨论达成共识后,框架将所有智能体的推理树合并成一棵最终的、完整的推理树,并给出最终诊断答案。
在交叉验证环节,ToR 会通过多轮循环来审阅和解决冲突:
- 审阅与冲突检测:智能体之间会互相交换彼此的“推理树”。如果一个智能体发现其他人的结论与自己的证据相矛盾(例如:门诊医生根据症状怀疑是肺炎,但病理医生根据活检发现是肺癌),就会触发“讨论”。
- 交叉辩论:
- 提出意见:智能体针对冲突点提出质疑。
- 证据溯源:被质疑的智能体需要回溯其推理树中的“叶子节点”(具体证据),解释其判断依据。
- 动态更新:智能体会根据其他人的强有力证据来修正自己的推理路径。
算法中设置了 maximum rounds k(通常为 2 轮)和 maximum turns t,通过迭代不断缩小分歧。
达成共识:各智能体不断完善自己的推理树,直到形成一致的看法或在证据树上达成互补。最后,将多轮讨论后优化过的各个分支(来自不同专家的推理路径)合并成一棵巨大的、完整的多智能体推理树 (Multi-Agent Reasoning Tree),形成可回溯的逻辑推导过程。
实验
实验数据集为作者团队自构建的非公开数据集;其中 Relevance 和 Completeness 是抽样 30 个交给真正的医生打分的结果。
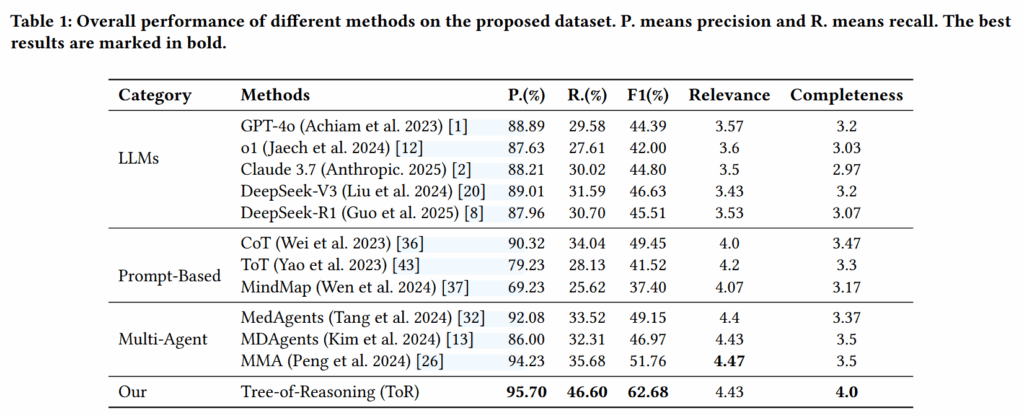
- 对比顶级模型:ToR 的 F1 分数达到 62.68%,而单独使用 GPT-4o 仅为 44.39%,DeepSeek-R1 为 45.51%。
- 对比同类框架:相比于之前最强的多智能体医疗框架 MMA (51.76%),ToR 的表现提升了超过 10%。
- 关键结论:多智能体协作(分工)比单纯增加模型的逻辑深度(如 CoT 或 o1)在处理复杂医疗数据时更有效。
案例分析

结论
- 提出了推理树(ToR),这是一种多智能体框架,旨在通过引入基于临床证据的推理树结构来处理复杂的医疗诊断任务。
- 这个方法首先分配不同领域特定的医生代理来分析各种类型的医疗数据并生成相应的推理路径和证据。然后引入多智能体交叉验证机制来更新每个智能体的推理过程和相应的证据,从而得出最终的多智能体协作诊断结果。这种显式多智能体推理框架不仅增强了复杂场景下的推理能力,而且提供了更好的可解释性。
- 实验表明,ToR 方法优于其他基线,凸显了结合推理树来改善医学诊断的好处。
启发与评价
- 1.0 技术创新——逻辑思维推理框架:
- 强迫模型输出结构化推理链(在这里是推理树)是一种惯常的、可以大大增强可解释性的手段,推理链的结构化方式将会直接影响推理效果;
- 通过多个角度分析互相辩论可以有效地消解冲突,但是这种方法并不直接指向冲突消解的底层原理,即命题逻辑分析;
- 推理树用的这种现有结论后有分析的方案在我看来是有点问题的,会有引入幻觉的地方
- 2.1 技术目标——专业手册公众服务:
- 领域专家智能体+结构化推理是一个不错的方法,可以应用于其他需要深度、可审计推理的专业领域
- 把自己作为一个临床决策支持系统而非取代医生的系统,也体现了这个系统的证据推理本质。这样的做法可能才是非权威人士开发的系统能够承受专业性质疑的原因。
- 3.1 场景功能——食养通:
- 可以根据不同人士对食品的不同角度来设计相似的多 agent 协作系统,比如健身教练、医生、营养学家等;这个框架把已有的 workflow 类创新收纳了进来,让这些创新都可以发挥作用。