作者:Wenxuan Zhou Kevin Huang Tengyu Ma Jing Huang
来源:AAAI
单位:University of Southern California;JD AI Research;Stanford University
发表日期:2021.2
论文介绍
背景动机
随着知识图谱与信息抽取的发展,关系抽取逐渐从句子级扩展到文档级任务。真实关系往往跨越多个句子,需要模型理解整篇文档中的实体交互信息。
文档级关系抽取中,一个文档包含大量实体对,且同一实体对可能具有多个关系标签。
现有方法多依赖固定阈值或复杂图结构,难以同时兼顾效率与预测准确性。
长文档中只有少量上下文真正决定实体关系,但现有方法通常使用全局实体表示。这会引入大量无关信息,导致模型难以准确定位与当前实体对相关的关键证据。
研究目标
提出文档级关系抽取模型 ATLOP,利用预训练语言模型提升复杂文档中实体关系识别能力。
通过 自适应阈值机制(Adaptive Thresholding),解决多标签关系预测中固定阈值不适应不同实体对的问题。
通过 局部上下文池化(Localized Context Pooling),定位与实体对相关的关键上下文信息,减少无关信息干扰。
核心内容
Adaptive Thresholding
传统多标签关系抽取通过固定阈值判断关系是否成立,但不同实体对的预测置信度分布存在差异。
本文引入 threshold class (TH),将阈值作为可学习类别,通过比较关系得分与 TH 得分决定关系是否成立,从而实现 自适应关系决策阈值。
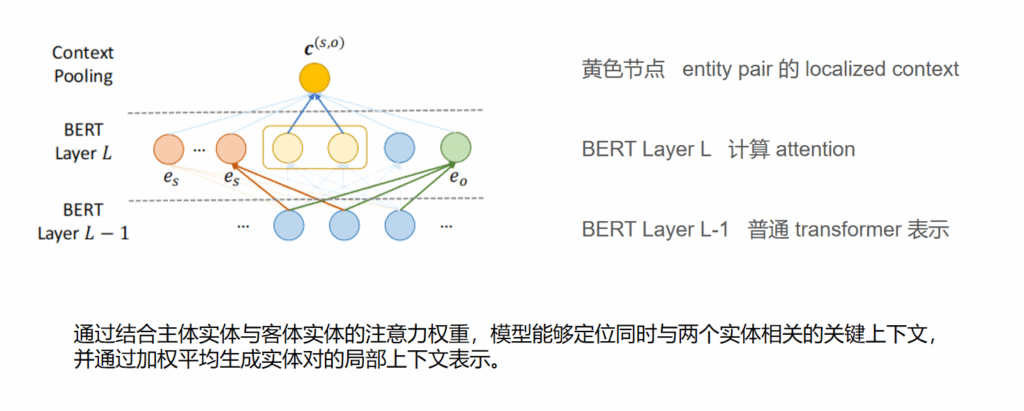
Localized Context Pooling
传统方法为每个实体生成 统一的全局表示,
但文档中只有 少量上下文真正决定实体关系,其余信息会引入噪声。

为每个实体对生成专属上下文表示,减少无关信息干扰,提高关系预测准确性。
实验评估
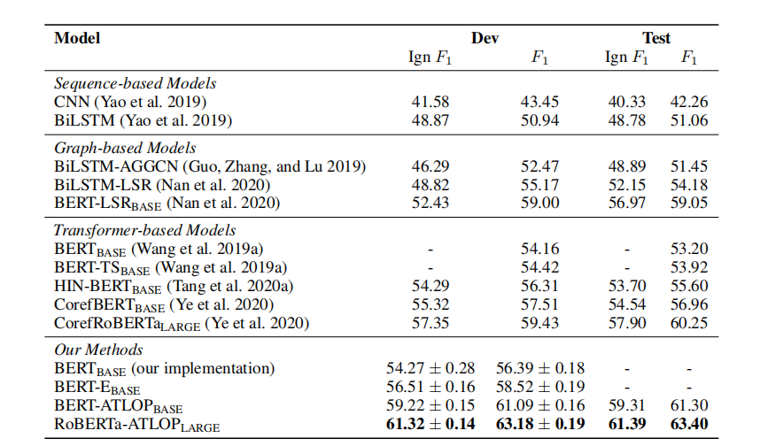
ATLOP 在 DocRED 数据集上显著优于现有方法,其中 RoBERTa-ATLOP 达到 63.40 F1,取得当前最佳性能。
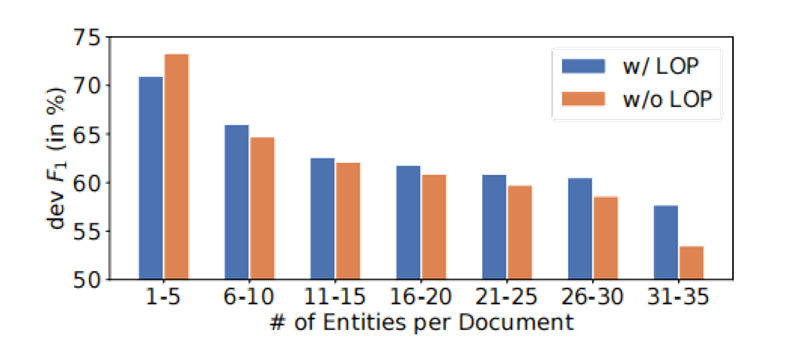
随着文档中实体数量增加,加入 Localized Context Pooling(LOP) 的模型始终优于不使用 LOP 的模型,说明该方法能够更有效地捕获多实体文档中的关键上下文信息。
总结思考
论文总结
1.文档级关系抽取任务相比句级关系抽取更加复杂,一个文档中通常包含多个实体对,并且同一实体对可能对应多个关系标签,导致模型需要同时解决多实体(multi-entity)和多标签(multi-label)问题。传统方法往往依赖构建文档图结构进行推理,但在预训练语言模型(如 BERT)已经能够捕获长距离依赖的情况下,图结构的必要性仍存在争议。
2.本文提出 ATLOP(Adaptive Thresholding and Localized Context Pooling)模型,通过两个关键技术提升文档级关系抽取性能:
Adaptive Thresholding(自适应阈值):引入可学习的阈值类别替代传统全局阈值,使不同实体对能够自动学习最合适的关系判定阈值,从而更好地解决多标签分类问题。
Localized Context Pooling(局部上下文聚合):利用预训练模型的注意力权重定位与实体对相关的上下文信息,并构建针对实体对的局部语义表示,减少无关上下文带来的噪声。
3.实验在 DocRED、CDR 和 GDA 三个数据集上进行验证,结果表明 ATLOP 在文档级关系抽取任务上显著优于现有方法,在 DocRED 数据集上达到 63.4% F1 的新 SOTA。实验分析还表明,自适应阈值机制能够有效缓解多标签决策问题,而局部上下文聚合可以在实体数量较多的文档中更准确地定位关系证据
启发思考
1.1技术创新-逻辑思维推理框架:ATLOP 提出了 Adaptive Thresholding 与 Localized Context Pooling 两种机制,用于解决文档级关系抽取中的 多实体、多关系标签问题。该方法通过利用预训练模型的注意力机制定位实体对相关上下文,并通过自适应阈值动态判断关系标签,有效减少无关上下文和固定阈值带来的误判。这一思路说明,在复杂文本抽取任务中,简单拼接长文本并不能保证模型有效利用关键信息,需要通过结构化上下文组织或注意力机制强化关键信息建模。
2.1技术目标-专业手册公共服务:提升模型在复杂文档中的关系识别能力,使模型能够在包含大量实体与上下文信息的文档中准确识别实体关系。然而 ATLOP 仍然局限于 单文档关系抽取任务,无法直接处理跨文档信息整合问题。针对这一不足,本课题可以在其基础上引入 检索增强机制(RAG)或跨文档证据聚合模块,使模型能够在多个专业文档之间进行证据检索与推理,从而更好地服务于专业知识抽取与公共知识服务场景。
3.1场景功能-食养通:可以在 ATLOP 的基础上构建 跨文档关系抽取框架,例如通过实体对驱动的文档检索、证据段落选择以及跨文档推理模块,实现对“成分—功效—适用人群”等关系的综合抽取。这将有助于提升系统在健康饮食知识服务场景中的信息整合能力,同时增强系统结果的可解释性与实用价值。