作者:Weiqi Yan1 , Lvhai Chen1 , Shengchuan Zhang1∗ , Yan Zhang1 and Liujuan Cao1
时间:2025.8
来源:IJCAI 2025
单位:Xiamen University
背景
- 伪装目标检测(COD)的痛点:深度融合于背景的伪装目标使得像素级的标注非常困难且成本高昂。
- 现有半监督方法的缺陷:现有的半监督COD方法通常只使用少量标注数据和大量无标签数据,但它们主要依赖随机采样来选择标注数据,往往选出许多对模型学习没有价值的“废数据”;此外,面对极少量的标签数据,现有模型很难充分学习到复杂的伪装先验知识,导致分割性能不佳。
贡献
- 提出了一种创新的半监督伪装目标检测模型 SCOUT。
- 提出了 自适应数据增强与选择(ADAS)模块,通过对抗性增强和评分采样策略,专门挑选出对模型最有价值的数据进行标注,避免了无意义的标注工作。
- 提出了 文本融合模块(TFM),利用图像级指示性文本引导视觉模型,通过文本-视觉交互帮助模型更好地学习伪装相关知识。
- 构建了一个新数据集 RefTextCOD,为现有的主流COD数据集补充了近万张图像级的详细文本描述标注。
方法
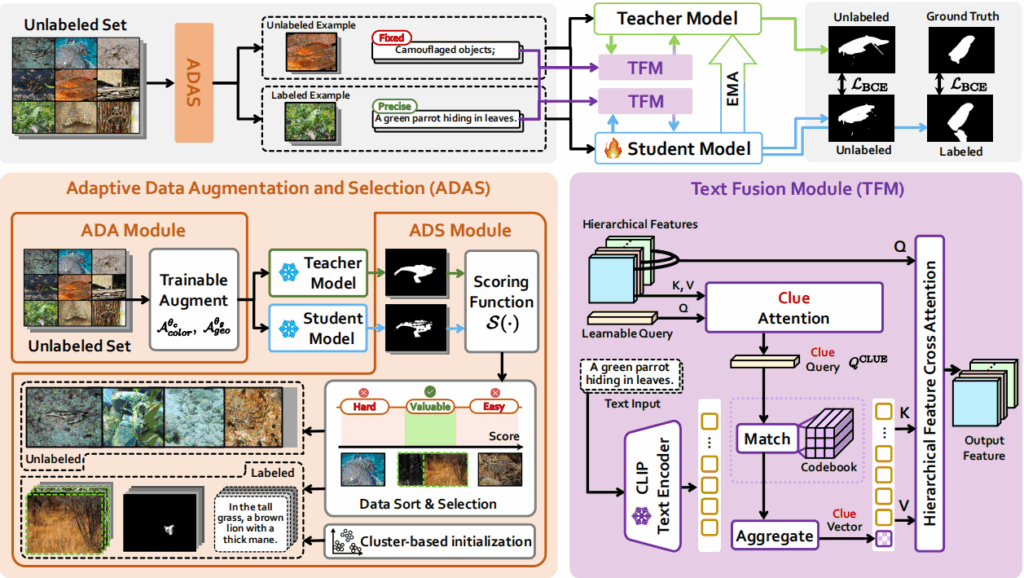
SCOUT由两个核心模块组成:
- ADAS模块(选数据):
- 自适应数据增强(ADA):使用可学习的颜色和几何增强策略,对无标签数据进行对抗性增强。
- 自适应数据选择(ADS):让“教师模型”和“学生模型”对无标签数据进行预测,计算两者预测结果的SSIM(结构相似度)和MAE(平均绝对误差)。得分为0代表太难(可能是纯噪声点),得分为1代表太简单(无学习价值)。模型专门挑选得分在 0.5左右(中等难度、半懂不懂) 的样本交给人工/系统进行标注。
- TFM模块(用文本辅助视觉):
- 利用冻结的 CLIP文本编码器 提取指示性文本(例如“草丛中藏着一辆绿色的装甲车”)的特征。
- 提出“线索注意力机制(Clue Attention)”和“特征码本(Codebook)”,将文本提取的类别先验知识与视觉特征进行交叉注意力融合(Cross-Attention),从而精准定位伪装目标区域。
实验
- 训练集:从CAMO和COD10K数据集中按 1%、5%、10% 的比例通过ADAS挑选标注数据进行训练。
- 测试集:CHAMELEON, CAMO, COD10K, NC4K 四大主流基准测试集。
- 测试设置:测试了使用“固定文本(如:伪装目标)”和“精准文本(具体描述目标细节)”两种推理情况。
- 对比基线:与Mean Teacher, CamoTeacher, SCOD-ND等最新的半监督模型对比。
结果
- 定量分析:SCOUT在所有测试集和所有评估指标(S-measure, F-measure, E-measure, MAE)上均超越了之前所有的半监督SOTA模型。尤其在MAE上提升了52.0%,S-measure上提升了19.1%。
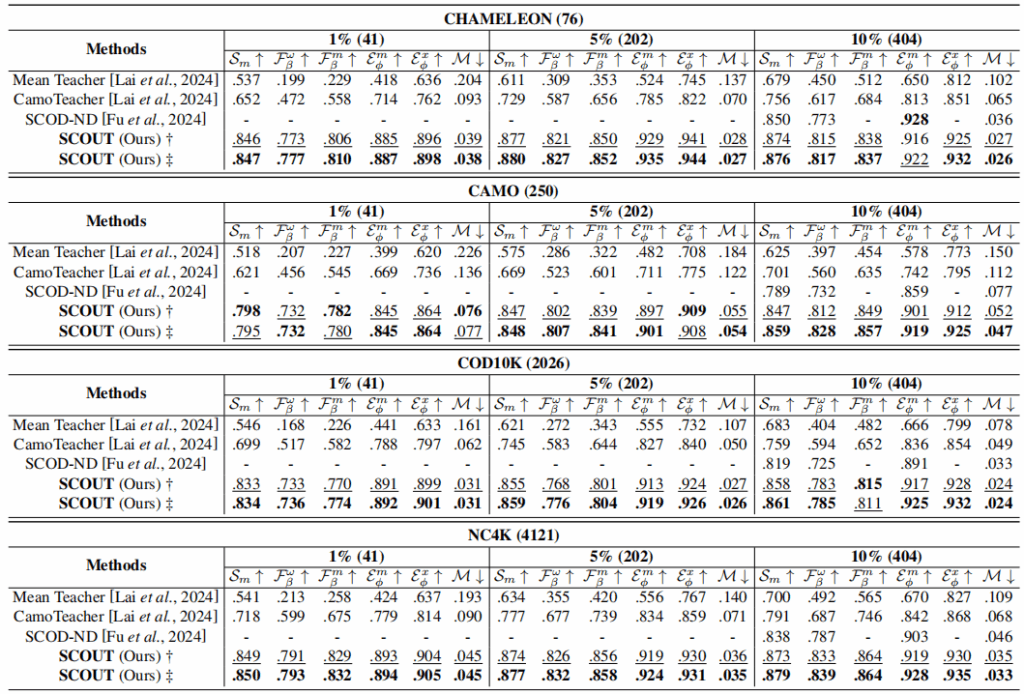
- 定性分析:在多目标、严重遮挡、小目标等极其挑战性的场景中,SCOUT分割的边界更清晰,误报更少。
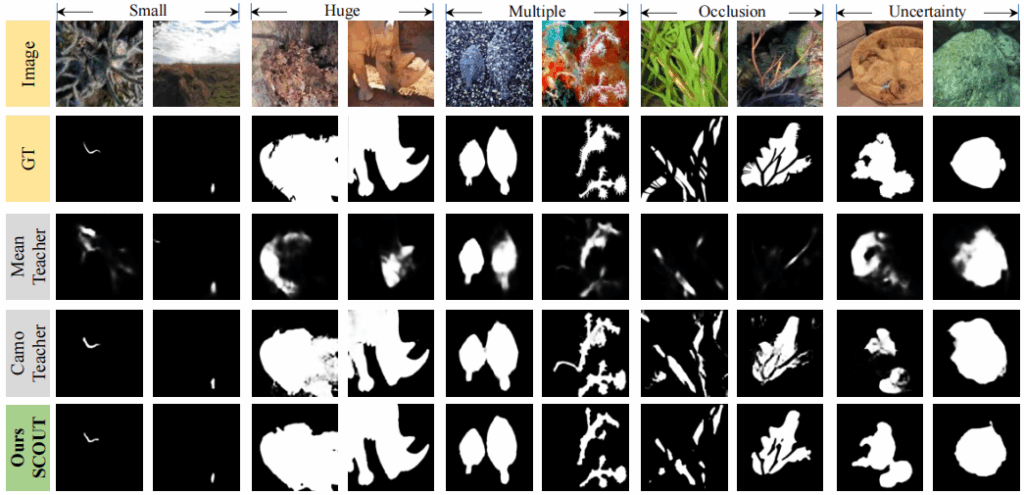
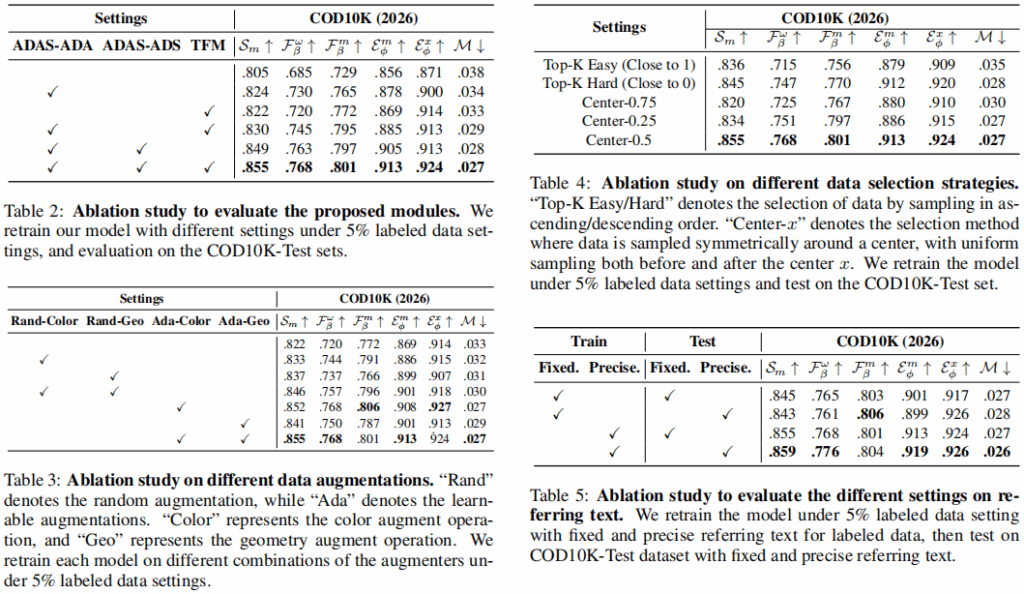
- 消融实验证明:只依靠精确文本引导(TFM)或只依靠自适应选数据(ADAS),都能大幅提高模型表现;两者结合达到了最佳。
启发
- 可以引入论文的Mean Teacher半监督框架,将Unity生成的有标签仿真数据与真实无标签野外侦察影像结合,通过教师模型生成稳定伪标签来指导学生模型。
- 借鉴ADAS(自适应数据选择)模块的打分机制,利用双模型对无标签数据预测的结构相似度(SSIM)与绝对误差(MAE)计算不一致性,精准筛选出得分在0.5左右的高难度、高价值边缘样本,极大降低无效数据的处理成本;
- 最后,在目标发现与意图认知环节,借鉴TFM(文本融合模块)的核心思想,将大语言模型(LLM)生成的战术布局建议作为指示性文本(Referring Text),利用线索注意力机制(Clue Attention)提取视觉上的疑似目标线索,并与系统构建的“军用伪装特征码本(Codebook)”进行先验匹配提取线索向量,最终通过交叉注意力实现文本情报语义与视觉特征的深度融合。
对齐思考
1. 技术创新—多模态拓扑认知
论文通过计算文本与视觉多层级特征的交叉注意力来挖掘局部线索,但在实际场景下,目标往往不仅是像素级的隐蔽,更是空间拓扑布局上的伪装(如战车依托山体反斜面、营地与植被的几何嵌套)。
我们可以将大语言模型基于战术生成的“地形-目标布局建议”转化为拓扑语义图谱。可以构建一个“3D拓扑先验码本”,存储各类军用装备在特定地形下的典型空间分布特征。当系统通过无人机/卫星提取到基础视觉特征后,不再仅做 2D 的像素匹配,而是通过“语义-几何交叉注意力机制”,让 LLM 的战术拓扑先验去引导视觉模型,实现从“寻找孤立的伪装像素”到“认知整体战术阵型拓扑”的升维,从而更精准地预测敌方的集结/潜伏意图。
2. 技术目标—虚拟声景孪生生成
传统的 Unity 战场孪生往往依赖穷举或随机参数生成,缺乏针对性。我们可以借鉴 ADAS 寻找“0.5分高价值难例”的博弈逻辑:将大语言模型(LLM)输出的战术布局作为骨架,而将 Unity 引擎中的环境变量(如植被密度、光影斑驳度、雾气浓度、伪装网材质覆盖率)作为可动态调节的“增强参数”。
构建自适应孪生闭环: 在孪生场景生成过程中,系统将当前 Unity 渲染的场景实时输入敌方感知模型。若感知模型极易识别出战车(得分接近1,无伪装难度)或完全被环境遮蔽致盲(得分接近0,纯噪声),则系统驱动 Unity 自动重构环境参数;核心目标是不断逼近并生成让感知模型产生最大分歧、置信度徘徊在 0.5 左右的“高价值边缘对抗场景”。通过这种基于模型反馈的对抗性孪生生成机制,我们不仅能自动化产出海量高质量的 Sim2Real(虚实迁移)训练数据,也从根本上确保了生成的“景”具备实战级的伪装难度与极高的评估价值。
3. 场景功能—EchoMie
我们可以反向应用这种“文本引导视觉重塑”的技术思想,实现情绪文本对视频渲染的精准驱动。EchoMie 接入 LLM 分析出的“用户情绪/心情”即相当于论文中的指示性文本(Referring Text)。我们可以建立一个基于潜在空间的“情绪-视觉特征码本”(例如将“忧郁”映射到冷色调与缓慢粒子特效,“开心”映射到高饱和度与跳跃AR元素)。当 LLM 评估出用户情绪为“治愈”时,系统利用 Clue Attention 提取原视频中的关键视觉线索,在码本中匹配出最适合的“治愈系”卡通渲染权重与 AR 资产向量。最后,通过 Cross-Attention 将这些“情绪向量”作为条件注入到视频生成模型中。这种机制确保了 EchoMie 添加的每一种卡通滤镜和 AR 元素,都不是随机的贴图,而是严格受底层“情绪文本”约束与引导的视觉重构,实现真正“懂你心情”的个性化沉浸式视频二创。