作者: Junsong Chen
单位: Huawei Noah’s Ark Lab, Dalian University of Technology, HKU, HKUST
来源: arXiv preprint
时间: 2023.12
一、研究背景
1.现有模型的高昂训练成本 尽管 DALL-E 2、Imagen 和 Stable Diffusion 等 T2I 模型开启了逼真图像合成的新时代,但它们的训练需要巨大的计算资源 。
2.环境影响与碳排放 巨大的计算量导致了大量的二氧化碳(CO2)排放,给环境带来压力 。例如,RAPHAEL 的训练产生的二氧化碳排放量高达 35 吨,相当于一个人 7 年的排放量 。
3.阻碍创新与社区发展 高昂的成本和资源需求为研究社区和初创企业设立了极高的门槛,严重阻碍了 AIGC(人工智能生成内容)社区的基础创新 。绝大多数研究者和创业者难以承担从头构建高质量生成模型的成本。
4.现有训练流程与数据的低效 论文指出导致训练缓慢的原因主要在于训练流程和数据两个方面:
任务纠缠: 现有方法通常将像素依赖学习、文本-图像对齐和美学质量提升这三个任务混合在一起,使用海量数据从头训练,导致效率低下 。
数据质量问题:现有的文本-图像对数据集(如 LAION)存在文本描述缺失、词汇频率低和长尾效应等问题。文本往往只能描述图像中的部分对象,这种信息密度低的“弱”文本-图像对严重阻碍了模型的训练效率,导致需要数百万次迭代才能实现稳定的对齐。
二、核心贡献
训练策略分解:将传统的 T2I 训练任务分解为 三个子任务,从而提高训练效率:像素依赖性学习:通过低成本的类条件模型(例如使用 ImageNet 预训练)来捕获自然图像的像素分布。文本-图像对齐:精确地对齐文本和图像,采用高信息密度的文本-图像对来加速对齐学习。美学质量提升:通过使用高质量的美学数据对模型进行微调,进一步提升生成图像的艺术感。
高效的 T2I Transformer:基于 Diffusion Transformer (DiT),PIXART-α 引入了 跨注意力机(Cross-Attention) 来注入文本条件,同时简化了传统的计算密集型类别条件分支,减少了计算量和资源消耗。
高信息密度数据:传统的文本-图像数据集存在文本描述不完整和信息密度低的问题。PIXART-α 使LLaVA 模型自动生成高质量的文本描述,提高了数据集的概念密度,帮助模型在训练时更高效地对齐文本和图像。
训练效率:PIXART-α 显著提高了训练效率。例如,PIXART-α 仅用了 12% 的 Stable Diffusion 训练时间,且 CO2 排放减少了 90%,成本大幅降低。相比 RAPHAEL 等大型模型,PIXART-α 的训练成本只有 1%,且节省了 近 300,000 美元。
图像质量:尽管训练成本和资源消耗大幅降低,PIXART-α 在图像质量方面仍表现出色。它的生成图像在 FID 等指标上表现优异,并且在 T2I-CompBench 中展示了在文本-图像对齐、属性绑定、对象关系等多个维度的优势。
定制化功能:PIXART-α 还支持与 DreamBooth 和 ControlNet 集成,提供定制化图像生成能力,可以精确修改图像的颜色、风格等属性,进一步提升其在实际应用中的灵活性(例如定制特定风格或修改对象颜色)。
总结:PIXART-α 通过其创新的设计,使得文本到图像生成不仅更加高效,而且大幅降低了训练成本和环境影响。它为研究人员、初创公司等提供了一个 低成本、高质量 的生成模型构建方案,为 AIGC(生成式人工智能内容)社区带来了新的突破和思路。
三、方法
1.训练策略分解(Training Strategy Decomposition)
PIXART-α 将训练过程分为 三个阶段,每个阶段聚焦于不同的任务,从而提高训练效率:
阶段1:像素依赖性学习
该阶段的目标是学习图像的像素分布,并通过类条件模型初始化,以低成本进行自然图像生成。
阶段2:文本-图像对齐学习
在此阶段,模型的目标是确保生成的图像与输入文本的描述精确对齐,PIXART-α 通过高信息密度的文本-图像对来加速这一过程。
阶段3:高分辨率和美学质量生成
最后,模型通过使用高质量的美学数据进行微调,以生成高分辨率、视觉质量优秀的图像。
2.高效的 T2I Transformer(Efficient T2I Transformer)
PIXART-α 基于 Diffusion Transformer (DiT),并对其进行了优化以提高效率:
跨注意力机制(Cross-Attention):每个 Transformer 块中加入了多头跨注意力层,以便更有效地与文本嵌入进行交互。
AdaLN-single:通过只使用时间嵌入(time embedding)并消除类别条件,减少了模型的参数量,提升了效率。
3.高信息密度数据(High-Informative Data)
PIXART-α 通过 LLaVA 模型生成高质量的文本描述,显著提高了数据集的概念密度,并减少了歧义,从而加速了文本和图像的对齐过程。
4.数据集构建(Dataset Construction)
PIXART-α 使用了多样化的数据集,包含了 SAM 数据集 和其他高质量的数据集,如 JourneyDB 和 内部数据集,以确保高效训练和高分辨率图像生成。
四、实验
1.实验准备基础架构: 采用 DiT-XL/2 作为基础网络架构 。
文本编码器: 使用 T5 large language model (4.3B Flan-T5-XXL) 提取文本特征,这比 CLIP 的文本理解能力更强 。
Token 长度: 将提取的文本 Token 长度调整为 120(通常为 77),因为该研究使用了信息密度更高的密集描述(Dense Captions)。
VAE: 使用来自 LDM 的预训练且冻结的 VAE 。
硬件与时间: 最终模型在 64 张 V100 GPU 上训练了约 26 天 。换算为 A100 GPU 大约为 753 GPU days 。
2.性能对比 (Performance Comparisons)实验从三个主要维度进行了评估:图像保真度 (Fidelity)、文本对齐 (Alignment) 和 用户偏好 (User Study)。
A. 图像保真度 (Fidelity) – FID 指标 结果: PIXART-α 在 MSCOCO 数据集上的 Zero-shot FID-30K 得分为 7.32 。对比:优于 Stable Diffusion v1.5 (9.62) 和 GigaGAN (9.09)。接近拥有巨大资源消耗的 RAPHAEL (6.61)。效率优势: 达到这一性能仅消耗了 SD v1.5 12% 的训练时间,以及 RAPHAEL 1% 的训练成本(数据量仅为 RAPHAEL 的 0.5%)。
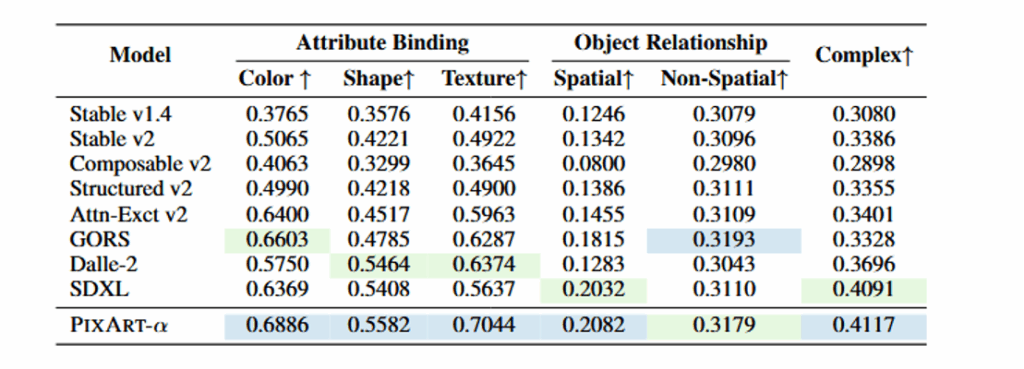
B. 文本对齐 (Alignment) – T2I-CompBench 测试基准: 使用 T2I-CompBench 评估组合生成能力(如属性绑定、物体关系、复杂组合等)。结果: PIXART-α 在 6 项评估指标中有 5 项 表现优异(如颜色绑定、形状绑定、空间关系等)。优势: 优于 SDXL 和 DALL-E 2,这归功于第二阶段训练中使用了高信息密度的精确图文对,极大地提升了细粒度的语义对齐能力 。
C. 用户研究 (User Study)方法: 选取 300 个固定提示词,邀请 50 名评估者对比 PIXART-α 与 DALL-E 2、SDv2、SDXL 和 DeepFloyd 的生成结果 。
结果:在感知质量 (Quality) 和语义对齐 (Alignment) 上,PIXART-α 均优于对比模型 。
例如,相比 SDv2,PIXART-α 在图像质量上提升了 7.2%,在对齐性上大幅提升了 42.4% 。
消融实验 (Ablation Study)
为了验证架构改进的有效性,作者重点对比了不同的设计选择:
重参数化 (Re-parameterization) 的必要性:
如果不使用重参数化(w/o re-param),模型无法有效利用 ImageNet 预训练权重,导致生成的图像扭曲且缺乏细节 。
adaLN-single vs. adaLN:
效果: 论文提出的 adaLN-single 结构在视觉效果上与标准的 adaLN 相当 。
效率: adaLN-single 减少了 21% 的显存占用(29G -> 23G)和 26% 的参数量(833M -> 611M)。这证明了精简架构是高效训练的关键。
- 扩展应用 (Application Extensions)
实验还展示了 PIXART-α 良好的扩展性和兼容性,类似于 Stable Diffusion 生态:
DreamBooth (个性化定制):
模型可以轻松结合 DreamBooth 进行微调。实验展示了仅需几张图片,就能生成特定物体(如特定的狗或汽车)在不同场景下的高保真图像,甚至改变物体颜色 。
ControlNet (结构控制):
通过冻结 DiT 块并添加可训练副本(ControlNet 架构),模型能够接受边缘图(HED Edge)等作为控制信号。实验显示 PIXART-α 能精准地根据边缘图生成对应结构的图像 。
五、总结
总结:PIXART-α 提出了一个新的高效文本到图像生成框架,通过创新的 训练策略分解、高效的 Transformer 架构 和 高信息密度数据,在显著降低训练成本和计算资源消耗的同时,仍能生成高质量的图像。它的高效训练方式和卓越的生成能力使其成为研究人员和初创公司构建低成本高质量生成模型的有力工具。
未来方向:作者还指出,未来可以通过扩展 PIXART-α 的规模和性能,进一步提升生成质量,并针对生成细节和文本生成能力进行改进。此外,PIXART-α 为图像生成中的 定制化功能 提供了新的思路和工具,未来可以探索更广泛的应用场景。
六、对其思考
1.0 技术创新——训练策略解耦与高效架构框架。 PIXART-α 的核心在于“任务拆解 + 架构精简 + 数据增密”的高效训练范式。 架构精简(Efficient DiT): 在 DiffusionTransformer(DiT)基础上引入 Cross-Attention 注入文本条件,并创新性提出 adaLN-single 模块,在保持生成效果的同时减少了约 26% 的参数量和 21% 的显存占用。数据增密:利用多模态大模型(LLaVA)自动标注 SAM 数据集,生成高信息密度的伪描述,解决了传统数据描述稀疏导致的对齐效率低问题 。
2.0 技术目标——低成本高保真生成。 PIXART-α 的技术目标是在极低的计算资源消耗下,实现媲美甚至超越 SOTA 商业级模型的图像生成质量。 其核心在于打破“高质量=高成本”的定式,将训练成本降低至同类模型的 1% 左右 。
3.0 应用场景——可控与定制化图像合成。PIXART-α 不仅支持原生的高分辨率(最高 1024×1024)写实图像生成 ,还展现了极强的下游任务扩展能力。 它可以无缝结合 DreamBooth,仅需少量样本即可实现特定主体的高保真个性化生成与属性修改;同时支持结合 ControlNet,通过边缘检测图等条件信号,精准控制生成图像的空间结构与布局。