作者:Beilong Tang, Xiaoxiao Miao, Xin Wang, Ming Li
单位:杜克昆山大学
来源:IEEE ASRU, 2025
时间:2025年
技术背景
语音匿名化旨在在保留语言内容和副语言属性的同时,消除说话人身份信息。在VPC背景下,传统方法多依赖于解耦表示学习,通过显式提取说话人嵌入(Speaker Embedding,SE)并替换为伪身份来实现匿名,这类方法依赖于显式说话人的提取,目前的一种新兴方向侧重于无显式说话人嵌入的神经方法进行匿名合成(Speaker Embedding Free,SEF),这种方法避免了对于说话人的显式建模,但是该方法基于一个共享的SSL编码器,在面对强知情攻击的时候,对于隐私保护效果差。
核心创新
1、论文在SEF框架下引入了multi-k-means量化策略,通过多个独立训练的k-means模型对于SSL特征进行随机量化,通过构建多模型池(Model Pool)提升匿名化过程的随机性与非线性。
2、论文提出的多模型随机量化机制从结构上破坏了同一说话人跨话语的表示一致性,使说话人身份难以在匿名空间中对齐,从而显著提升对强攻击者的鲁棒性
3、论文系统分析了提出的SEF-MK框架在隐私和效用之间的新型权衡关系,量化器的数量可以一定程度提升语言内容和情感的保留度
技术框架
对于VAS中基于SEF的方向,流行的方法是基于KNN进行模型训练,阶段分为编码、匿名、解码阶段,编码阶段通过提取源说话人和目标说话人的SSL特征;在匿名阶段,目标是从源WavLM表示中删除说话人信息,执行KNN搜索找出目标说话人的最相似前k帧,通过目标说话人的最相似帧替换源说话人的最相似帧;在解码阶段,前k目标帧取平均值,通过传递给声码器用于合成匿名语音
论文提出的框架SEF-MK VAS,论文提出通过多个k-means量化器用于抑制说话人信息。SEF-MK 框架跳过了传统的“提取-替换-合成”链路,采用直接的特征变换逻辑
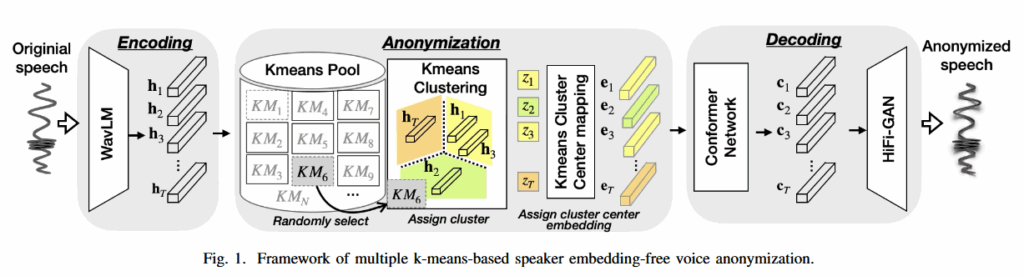
SSL 特征提取: 使用 WavLM 模型提取包含丰富上下文信息的连续语音特征表示。
多模型训练与映射: 将大规模语料按说话人子集划分,独立训练多个 k-means 聚类模型。匿名阶段,对输入特征序列,系统随机选择一个量化模型,将连续特征向量映射为质心索引。
语音重构:将量化后的特征输入由 Conformer 组成的解码器和 HiFi-GAN 声码器,重建音频。
框架的隐私优势在于匿名映射的随机性和对于SSL特征通过非均匀分布进行重采样,说话人的精细声纹被”粗粒度化“擦除
实验及分析
实验设置
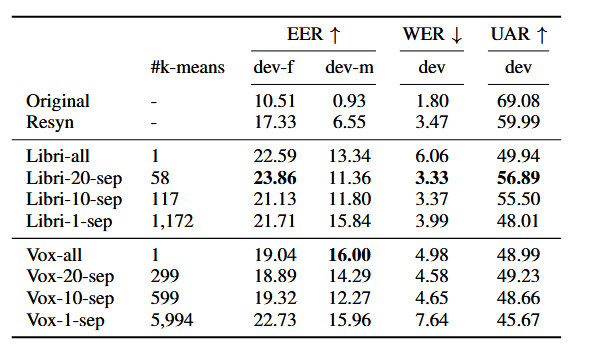
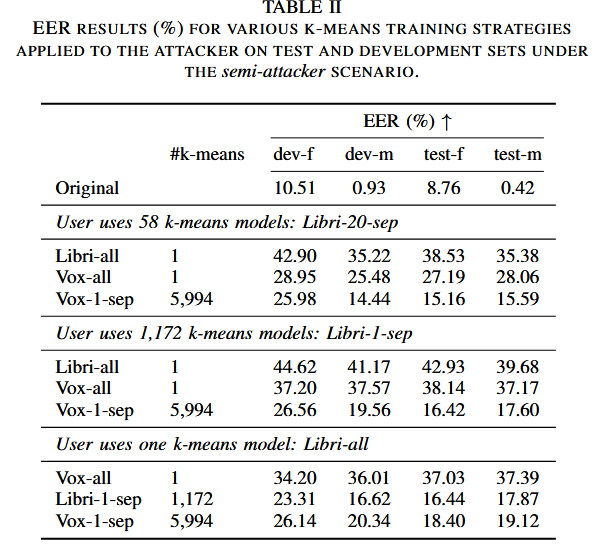
在 LibriSpeech 和 VoxCeleb 上进行验证。评估指标包括隐私性(EER)、语言保留度(WER)和情感保留度(UAR)。引入了半知情攻击(Semi-informed)和全知情攻击(Full-informed)场景
全知情攻击
半知情攻击
其他基线比对实验
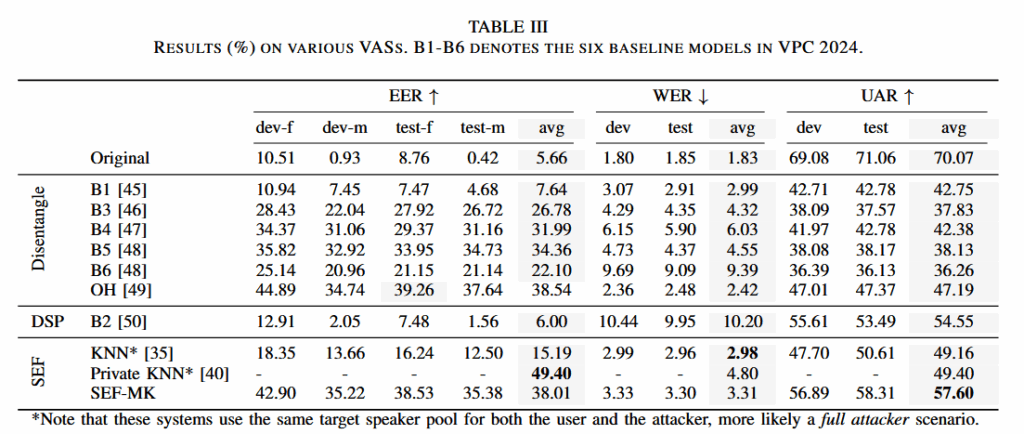
实验结论:
实验提出的SEF-MK框架,结果表明 multi-kmeans 相较于单 k-means 在隐私与效用之间表现出更优的平衡,不同训练分割策略的对比显示,以每个模型覆盖约 20 名说话人的配置在两个数据集上均取得最佳综合表现。跨数据集比较进一步表明,VoxCeleb 上的 EER 变化趋势与效用下降与其更高噪声和说话风格多样性密切相关,说明 k-means 的训练数据质量对匿名效果具有重要影响
启发思考
1.1、技术创新–数据拓扑标签计算:
论文中提出的方向SEF区别于VCP比赛的大多数方案通过硬解耦来实现去隐私,SEF是通过统计模糊化来弱化数据特征空间的身份信息,同时论文在多量化器的随机映射策略也很大程度上干扰了全知情攻击场景下的攻击效力,论文的多量化器和随机映射策略对于探索音频数据隐私保护具有参考价值,可以融入实验设计中探索更优化的方案
2.2、技术目标–虚拟声景孪生生成:
音频数据隐私生成是研究的技术目标,对于SEF-MK中出现的Resyn基线可以看出本身提取-匿名-解码链路存在一定效用下降的代价,优化的方向在于逼近链路基线的同时,对于隐私和效用取良好的平衡,或者在考虑保持身份匿名的前提,引入对于情绪等副语言属性的控制。
3.2、场景功能—echomie
场景功能针对于应用中的数据复用部分,论文中的m-k-means量化器是预训练好的,在真实场景中的时间问题以及相关的不可预测的动态匿名机制需要结合场景功能重新设计,同时在场景功能下,数据的直接复用需要在框架上引入MOS、F0等多项自然读、流畅性指标进行考虑