作者:Yuhang Qian1,2, Haiyan Chen2, Wentong Li1, Ningzhong Liu2, Jie Qin1
时间:2025年11月
来源:AAAI 2026
单位:南京大学
背景
迷彩图像生成(CIG)是计算机视觉领域的新兴方向,核心目标是合成目标物体与周围环境和谐融合、视觉一致性强的图像。
现有问题:现有 CIG 方法主要分为两类范式,但均存在明显缺陷:
- 背景适配范式:通过改变物体颜色和纹理使其融入背景,但破坏物体外观且忽略前景与背景的逻辑关系,导致生成结果不符合自然伪装规律。
- 前景引导范式:利用生成模型基于前景物体补全背景,但缺乏语义考量,生成的背景存在严重伪影,真实感不足。·
- 关键瓶颈:现有方法均未有效解决 “物体与背景的逻辑合理性” 问题,且迷彩训练数据集稀缺,进一步限制了技术发展
主要贡献
- 提出迷彩揭示对话机制(CRDM):借助大型视觉语言模型(VLM)的图像感知和上下文理解能力,为迷彩数据集生成高质量文本提示,填补了现有 COD 数据集缺乏文本标注的空白,使文本引导的迷彩生成范式成为可能。
- 设计 CT-CIG 框架:以稳定扩散模型(Stable Diffusion)为骨干,整合轻量级控制器和频率交互细化模块(FIRM),实现可控、高保真的迷彩图像生成,同时保证物体位置形状精准性和纹理细节丰富度。
- 引入交叉归一化(CN):解决控制特征与含噪潜变量的分布差异问题,提升训练稳定性;结合 LPIPS 感知损失,进一步优化生成图像的自然真实感。
- 全面验证有效性:通过多组实验验证了方法在图像质量(FID、KID)和文本对齐性(CLIPScore)上的优势,为文本引导迷彩生成提供了完整的技术方案和基准。
方法
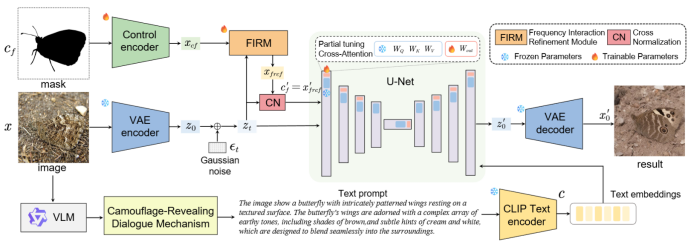
输入三种信息:掩码图(黑色代表主体,白色代表背景)、原始图像、VLM 生成的描述性文本
- 用 control encoder 对掩码图编码,形成控制信号矩阵;
- 用 VAE 编码输入的原始图像,输出清晰潜变量(z₀),给 z₀加入高斯噪声后,得到带噪声潜变量(zₜ);
- VLM 生成的描述性文本传入 CLIP 编码器,输出文本嵌入。
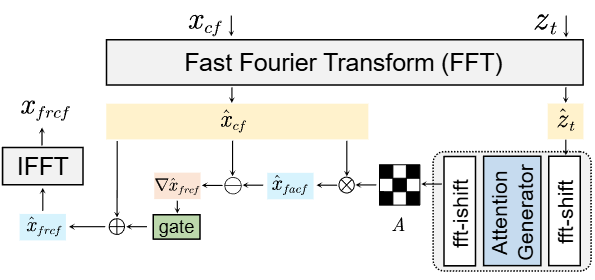
FIRM 结构:带噪声潜变量和控制信号分别经傅里叶变换转至频率域;带噪声潜变量的频率域结果取绝对值,得到频率幅度矩阵,输入注意力生成器(两层卷积层提取高频纹理特征),输出注意力权重图 A;将控制信号的频率域结果与注意力权重图 A 相乘,通过门控机制调整增强强度,得到增强的频率域特征;再通过傅里叶逆变换,将频率域信号转回特征域,输出增强后的控制特征。增强后的控制特征输入 CN 结构做交叉归一化,输出与带噪声潜变量分布对齐的控制特征矩阵。
U-Net 阶段:对齐后的控制特征矩阵、带噪声潜变量(zₜ)、文本嵌入三类输入传入 U-Net;U-Net 从带噪声潜变量中提取的图像特征作为 Q,文本嵌入作为 K/V,通过交叉注意力匹配语义;U-Net 在控制特征(形状 / 位置约束)和文本嵌入(语义约束)下,预测 zₜ中的噪声,从 zₜ中减去该噪声完成去噪,输出清晰潜变量(z₀’)。
清晰潜变量 z₀’ 经 VAE 解码器解码,生成最终的伪装像素图像。
实验
实验设置:
1、数据集与指标:采用 LAKE-RED 数据集,包含 4040 张训练图像、19419 张验证图像和 5066 张测试图像。训练集由 COD10K和 CAMO的伪装图像组成;测试集分为三类:伪装物体、显著物体和普通物体,每类各 6473 张图像。通过 VLM 处理这些图像,形成相关图像 – 文本对;使用 CLIPScore衡量训练和测试过程中的图像 – 文本对齐度。选择 FID和 KID量化生成图像质量,以 COD10K 的 5066 张伪装图像为评估基准。
2、硬件与参数:通过 VLLM 框架构建 Qwen2.5-VL,基于 ControlNext 实现 CT-CIG,以预训练 SDXL 为扩散基础。训练过程中,将图像和控制掩码调整为 512×512 大小,转换为 128×128 的潜变量,批大小设为 4;控制尺度设为 1.2,轻量化控制网络和 FIRM 的学习率设为 1e-4(便于控制信号适配),SDXL UNet 的学习率设为 5e-6(谨慎微调)。使用 4 块 NVIDIA RTX A5000 GPU 训练 CT-CIG 80 个 epoch,耗时约 8 小时。
实验设计
对比实验:与 11 种现有最优(SOTA)方法对比,涵盖背景适配、前景引导和文本引导三类范式,包括 LCGNet、LAKERED、ControlNet 等经典方法。
消融实验:验证核心组件的有效性,包括 “无 FIRM&CN”“无 CN”“无 FIRM” 三种配置,以及不同文本提示(简单提示、详细提示、含轮廓描述提示等)的影响。
实验结果

CT-CIG 在整体设置下的图像质量和文本对齐度均最优,整体FID为52.88、KID为0.0169、CLIPScore,0.3243,显著优于其他对比方法。在类别特异性任务中也保持高度竞争力,在迷彩物体、显著物体和普通物体三类测试集中均保持竞争力,其中迷彩物体生成的FID 低至30.59展现出最具优势的性能。
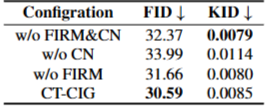
消融实验显示,完整CT-CIG 框架的性能最优,去除FIRM或CN后,FID均出现不同程度上升,验证了各组件的必要性。
启发与局限
核心启发
多模态融合价值:文本与图像的跨模态引导能够有效解决 “逻辑合理性” 问题,为生成类任务提供了新的优化思路。
模块化设计优势:通过轻量级控制器、频率细化模块等专用组件,在不重构骨干模型的前提下,实现了对特定任务的精准适配,降低了训练成本。
数据增强新思路:利用 VLM 生成高质量标注数据,可有效缓解小众领域数据集稀缺的瓶颈,为同类研究提供了数据构建方案。
局限性
小物体处理不足:VLM 难以准确识别小尺寸迷彩物体,导致这类目标的生成结果存在逻辑偏差或内容错误。
未见过物体适配差:对于训练数据中未包含的物体类别,模型缺乏相关伪装模式的先验知识,生成的迷彩效果不佳,甚至出现位置偏移。
对齐思考
1.技术创新—多模态拓扑认知
现有模型在多模态对齐任务中常依赖注意力机制实现局部特征匹配,但往往忽视了模态内部语义结构与跨模态全局关联的一致性,这也使得类似本论文伪装图像生成任务中,易出现 “局部纹理匹配但物体与环境逻辑矛盾” 的问题 。
尽管论文通过 VLM 的对话机制建立了图文语义关联、借助 FIRM 实现了控制信号与图像纹理的频率域融合,但这类处理仍聚焦于单模态细节或局部特征的对齐,未显式约束多模态语义流形的全局结构。而引入拓扑保持约束(如持久同调、拓扑距离损失)或跨模态结构映射,能够让模型在对齐图像、文本、控制信号等模态时,主动维持各模态语义结构的一致性(例如 “蝴蝶” 在图像中的形状结构、文本中的物种描述、控制信号中的轮廓约束需在拓扑层面统一),这类将拓扑认知融入多模态对齐的思路,在当前相关研究中尚属稀缺,既能够解决全局逻辑矛盾的痛点,也能为后续生成任务提供更稳定、结构化的多模态基础表示,具备较强的创新潜力。
2.0技术目标—虚拟声景孪生生成
依托本论文所采用的交叉注意力与多模态可控生成框架,可进一步拓展至 “虚拟声景孪生生成” 的技术目标:
首先是从视觉场景预测音频,借鉴论文中视觉 – 文本的交叉注意力逻辑,通过视觉 – 音频交叉注意力建模视觉场景中的声源位置(如伪装图像里蝴蝶所处的枯叶区域)与材质反射特征(如枯叶纹理对应的沙沙声频谱),使生成的音频与视觉场景在感知层面高度一致;
其次是从音频反推环境视觉结构,结合论文中频率域特征融合的思路,通过拓扑一致性约束学习声音传播路径(如回声对应的空间大小)与环境视觉布局的关联,辅助数字孪生空间的结构重建;
最后是实现图文声三模态联合生成,结合当前三模态生成模型的发展趋势,将论文中 “文本引导图像生成” 的架构扩展为统一框架,完成 “描述性文本 — 视觉场景 — 匹配声景” 的一体化生成,最终实现视觉与声学特征协同的虚拟场景孪生。
3.2场景功能—EchoMie
借助融入拓扑认知的多模态对齐能力,EchoMie 系统能够在视觉、语音、文本等模态间建立结构化关联,从而更精准地识别用户情绪状态 —— 例如获取用户所处环境的视觉图像(类似论文中的原始图像输入)、语音信号与文本表达后,系统可通过跨模态拓扑对齐,将用户面部表情的形状结构、语音的节奏能量特征、文本的情感倾向映射至统一的情绪语义拓扑空间,避免单一模态噪声导致的情绪误判,形成稳定且一致的情绪表征,这一表征也将为后续生成模块提供清晰的语义结构基础。
而依托虚拟声景孪生生成技术,EchoMie 可基于识别出的情绪状态,构建与现实环境无违和感的舒缓体验:例如针对悲伤情绪,系统会生成与用户当前环境(如办公室桌面)拓扑匹配的暖色调视觉元素(类似论文中伪装图像的环境融合逻辑),同时搭配轻柔的环境声景(如桌面绿植对应的微风声);针对焦虑情绪,则生成低刺激的自然视觉场景与柔和的白噪音,且视觉与声景会通过交叉注意力机制实现语义连贯,并非简单的元素叠加。
具体来看,EchoMie 的功能可围绕这一逻辑展开:实时捕捉用户的多模态输入(环境图像、语音、文本),通过跨模态拓扑对齐追踪情绪趋势并在 AR 视图反馈;基于情绪状态,利用类似论文的可控生成能力,在现实视野中叠加与环境融合的安抚性虚拟元素(如匹配桌面纹理的虚拟绿植、具备空间感知的轻柔声景);结合用户指令,通过图文声三模态生成能力提供个性化情绪引导(如治愈系短句、冥想提示);若扩展至用户生活空间的数字孪生,还能依托拓扑关联的环境适配能力,在真实房间中叠加匹配布局的柔和灯光、虚拟植物等元素,实现 “环境级” 的情绪关怀体验。