2025年11月17日-gongchenhao
来源:ICML
作者:Junnan Li
单位:Salesforce AI Research
发表时间:2023
一、研究背景
视觉-语言预训练(VLP)的快速发展但成本极高
近年来,大规模图文模型(如 CLIP、BLIP、SimVLM、CoCa)不断刷新多模态任务效果,但大多依赖:
超大规模数据(数亿级)
端到端训练视觉模型 + 文本模型
巨额训练成本(计算资源昂贵
大模型出现“视觉能力缺失”问题
LLM(GPT、OPT、Flan-T5 等)具备强大的语言理解与生成能力,但:
它们在预训练时没有见过图像
无法直接进行视觉理解或视觉推理
因此如果强行端到端训练,会出现:
模态对齐困难
灾难性遗忘(forgetting)
训练极其昂贵
二、核心贡献
- 提出 Q-Former:轻量高效的视觉—语言桥接模块
利用一组可学习查询向量主动从冻结视觉模型中提取语言相关视觉特征,构建“信息瓶颈式”跨模态接口。 - 创新性两阶段训练策略,解决冻结 LLM 的模态对齐难题
通过“表示学习(ITC/ITG/ITM)+ 生成学习(LLM 接入)”逐步对齐视觉与语言空间,在不更新 LLM 的前提下实现稳定跨模态能力。 - 利用冻结视觉模型 + 冻结 LLM,实现极低训练成本的高性能多模态模型
仅训练 Q-Former 即可达到甚至超过 Flamingo 等大规模端到端模型的效果,训练参数量缩小 50× 以上。 - 建立通用可复用的多模态框架
视觉模型、语言模型均可自由替换,形成灵活的“即插即用式”多模态系统架构。 - 展示强大的零样本视觉任务能力
无需微调即可完成 VQA、图像描述、视觉对话、常识推理等任务,表明模型具备通用多模态推理能力。
三、方法
- 模型架构:Q-Former(Querying Transformer)
Q-Former 是 BLIP-2 的唯一可训练模块,由以下组成:
一组 learnable queries(可学习查询向量)
多层 Transformer
与视觉模型的 跨注意力(cross-attention)层
可作为编码器/解码器的自注意力结构(通过不同 mask 控制)
其作用是:
主动从冻结视觉模型抽取高度语言相关的视觉语义,并生成一组紧凑的视觉特征(32×768)。 - 第一阶段:视觉—语言表示学习(Representation Learning)
目标:
让 Q-Former 学会抽取文本相关的视觉特征。
使用三个任务联合训练(都不更新视觉模型):
① 图文对比学习(ITC)
对齐图像与文本的全局语义
queries 与文本的 [CLS] 进行对比
② 图像引导文本生成(ITG)
强迫 queries 提取能支撑文本生成的信息
采用多模态 causal mask,使文本 token 能看见 queries
③ 图文匹配(ITM)
学习细粒度跨模态对齐
使用双向注意力 mask,让 queries 与文本深度交互
三种损失共同促使 queries 学会“提取对语言最重要的视觉信息”。 - 第二阶段:视觉 → 语言生成学习(Vision-to-Language Generative Learning)
目标:
让 LLM 能理解 Q-Former 的视觉表示,但保持 LLM 完全冻结。
做法:
将 Q-Former 输出的 queries 线性投影到 LLM 的 embedding 维度
作为 soft visual prompts 拼接到语言输入前
使用 LLM 的语言建模损失训练 Q-Former(LLM 不更新)
两种 LLM 方式:
Decoder-only(OPT):直接做 LM loss
Encoder-Decoder(FlanT5):Prefix-LM loss(前缀输入,后缀预测)
效果:
LLM 获得视觉理解能力,而无需任何参数更新,也避免灾难性遗忘。 - 训练策略与整体框架
全流程中,视觉模型和 LLM 均冻结
仅训练 Q-Former(约 188M 参数)
两阶段训练分别进行:
250k 步(stage1)
80k 步(stage2)
四、实验
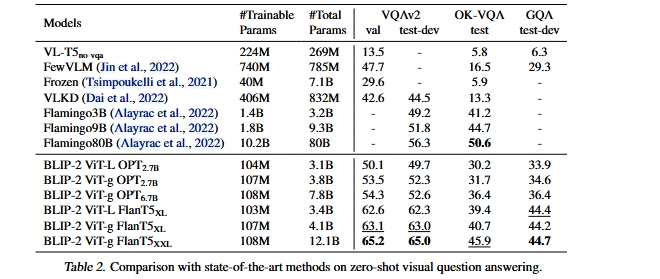
BLIP-2 在多个视觉语言任务上进行了全面实验,验证其在冻结视觉模型 + 冻结 LLM + 仅训练 Q-Former的设定下,仍能取得强于现有大型端到端模型的效果。

五、总结
一、核心范式:利用与桥接
BLIP-2确立了一种新范式:直接利用冻结的、成熟的单模态模型(如CLIP、OPT),并通过一个轻量的 Q-Former 作为桥梁来连接它们。Q-Former充当“信息瓶颈”,负责将视觉信息高效地“翻译”成语言模型能理解的“视觉提示”。
二、核心贡献与成果
高效卓越:以极少的可训练参数(1.88亿),在多项任务上达到最先进性能,实现了效率与效果的卓越平衡。
指令跟随:解锁了零样本指令跟随能力,能根据自然语言指令进行图像描述与对话,展现了通向多模态对话AI的潜力。
通用可扩展:作为一个通用框架,可“即插即用”地兼容更强的视觉或语言模型,具备长期生命力。
六、思考
1.0 技术创新——逻辑思维推理框架
BLIP-2 的核心创新在于提出 Q-Former 并采用“两阶段跨模态对齐”框架:
轻量级 Q-Former 作为视觉 → 语言的信息瓶颈,实现主动选择高价值视觉语义。
冻结视觉模型 + 冻结大语言模型,只训练 Q-Former,大幅降低训练成本。
2.0 技术目标——跨域知识结构对比
BLIP-2 的技术目标是:
让视觉模型负责感知、LLM 负责推理与生成,
中间用 Q-Former 实现跨域知识对齐与压缩,
达到用极少参数获得接近端到端大模型的效果。
3.0场景功能—图文编辑增强
利用BLIP-2的零样本图像描述与视觉问答能力
自动检测图片内容与文案是否一致
识别图片中未提及、描述错误或遗漏的信息
生成差异报告,辅助运营、媒体编辑提高内容准确度