来源:ACL
作者:Nianqi Li等
单位:Shanghai Key Laboratory of Data Science,Fudan University.
发表时间:2025 年 8月
一、研究背景
历史类比的重要性
历史类比通过将当代陌生事件与已知历史事件进行比较,帮助人们理解现实、辅助决策。
广泛应用于政策制定、危机应对(如用1918大流感类比新冠疫情)。
人类在使用历史类比时的局限性
容易依赖表面相似性;
常选择最先想到的类比,缺乏系统分析;
需要广博的历史知识,门槛高。
这篇文章提出“历史类比获取”任务:给定一个当代事件及其描述,自动生成一个在多维度上相似的历史事件。
二、主要框架
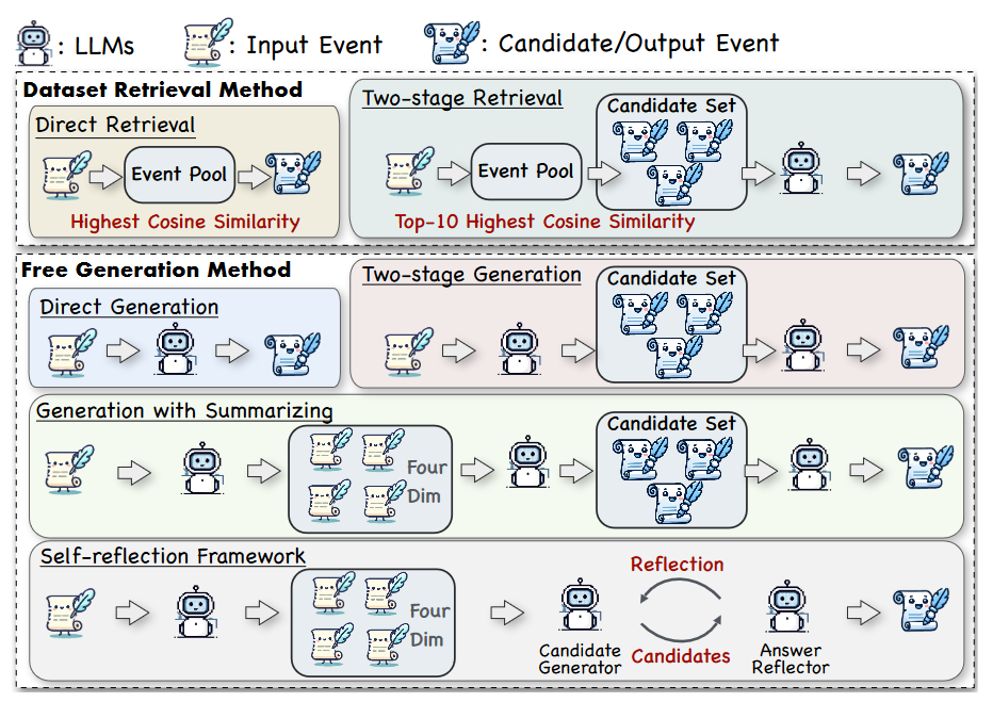
- 任务定义:历史类比获取输入:一个当代事件 E 及其文本描述 D
例如:“2020年美国国会山骚乱”)
输出:一个历史上真实存在的事件 在多个维度上与 E构成有效类比
2. 类比维度(基于史学理论):
Topic(主题):事件的核心议题(如“政治暴力”)
Background(背景):发生的社会/政治/经济条件
Process(过程):事件如何发展、关键节点
Result(结果):短期/长期影响、后果
目标不仅是“看起来像”,而是结构相似、逻辑可比。
| 范式 | 核心思想 | 优点 | 缺点 |
| 数据集检索法 | 从固定历史事件库中查找最相似项 | 结果真实、可控 | 覆盖有限、更新困难 |
| 自由生成法 | 利用LLM内部知识直接生成类比 | 灵活、覆盖面广 | 易产生幻觉、刻板印象 |
3. 使用 Google Arts & Culture 中的658个历史事件作为候选池。
(1) 直接检索(Direct Retrieval)
步骤:
用 text-embedding-3-small 对输入事件描述和所有候选事件描述编码;
计算余弦相似度;
返回相似度最高的历史事件。
特点:简单高效,但仅依赖表面语义匹配。
(2) 两阶段检索(Two-stage Retrieval)
步骤:
先用嵌入召回 Top-10 候选;
将这10个事件的描述输入LLM,提示其选择“最合适的类比”。
优势:引入LLM的推理能力,提升相关性。
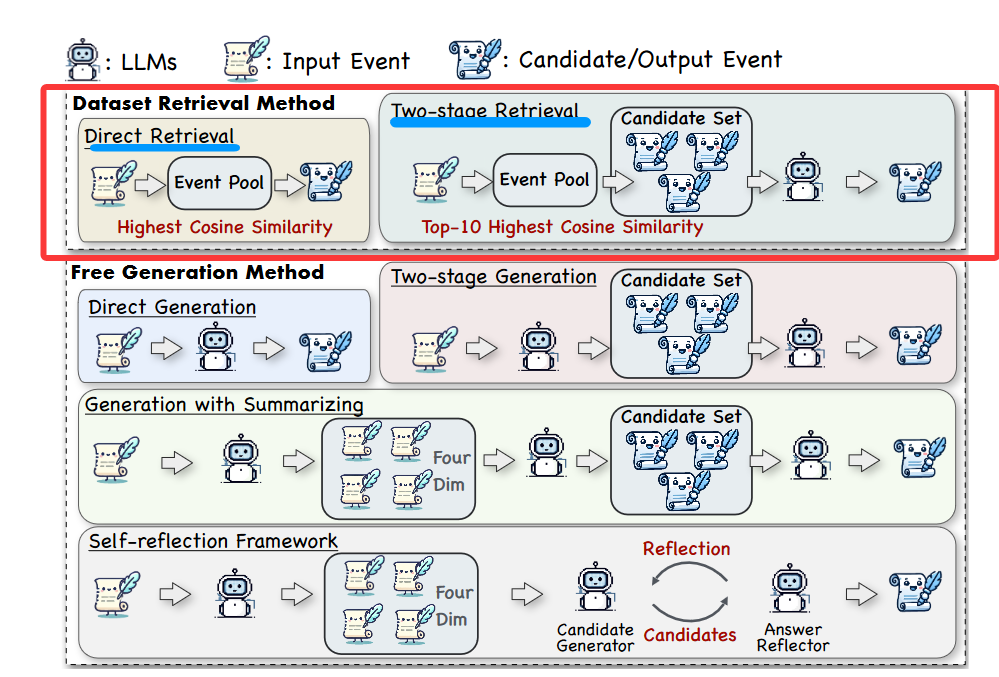
4. 利用LLM参数中隐含的历史知识,无需依赖外部数据库。
(1) 直接生成(Direct Generation)
“Given the event ‘X’, generate a historically analogous event.”
问题:易受训练数据偏见影响,可能生成虚构事件(如“19世纪法国AI革命”)。
(2) 两阶段生成(Two-stage Generation)
LLM生成10个候选历史事件;
通过Wikipedia API验证每个候选是否真实存在;
对真实候选,获取其维基描述;
LLM比较输入事件与候选描述,选出最佳类比。
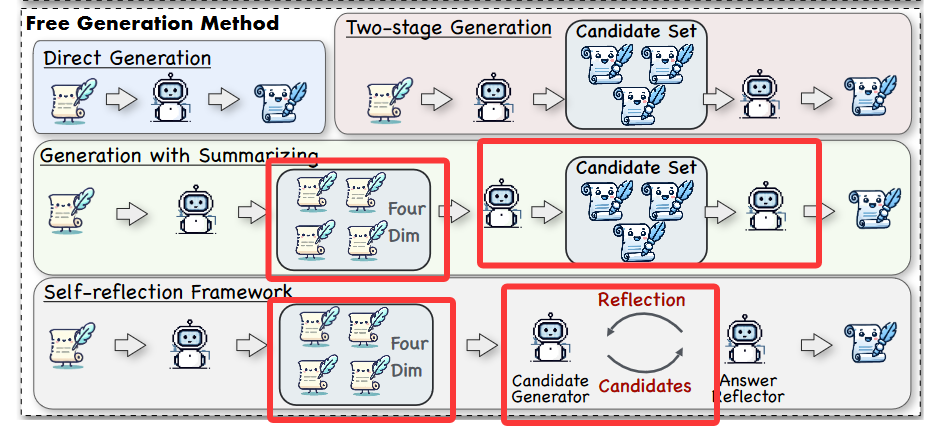
(3)带摘要生成(Generation with Summarizing)
创新点:先将输入事件和候选事件分别按四个维度(Topic, Background, Process, Result)结构化摘要(由GPT-4完成),再基于这些摘要进行比较和选择。
效果:信息更浓缩、对比更聚焦,提升类比质量。
(4) 自反思框架(Self-reflection Framework) :迭代优化机制,包含两个LLM模块:
| 模块 | 功能 |
| Candidate Generator(候选生成器) | 基于四维摘要,每次生成5个候选历史事件 |
| Answer Reflector(答案反思器) | 评估候选:• 若有合适类比 → 输出结果• 若无 → 给出反馈(如“避免聚焦同一国家”),要求重新生成 |
三、实验
数据集构建:
Popular Analogy(20个):公众熟知、有标准答案的类比(如新冠 vs 西班牙流感)。
General Analogy(160个):从Google Arts & Culture收集,涵盖战争、政治、文化、经济四大主题,无标准答案。
模型选择:
闭源模型:gpt-3.5-turbo-0125(OpenAI)
开源模型:Llama3.1-8B-Instruct(Meta)
温度(temperature)统一设为 0.1,确保输出稳定性
评估方式:
人工评估:历史专业学生对生成结果排序(Fleiss’s κ=0.97,高一致性)。
自动评估:提出 多维相似度指标 MDS(Multi-dimensional Similarity):
维度:主题(Topic)、背景(Background)、过程(Process)、结果(Result);
结合 抽象相似度(GPT-4打分)与 字面相似度(Jaccard,去重词);

实验结果:
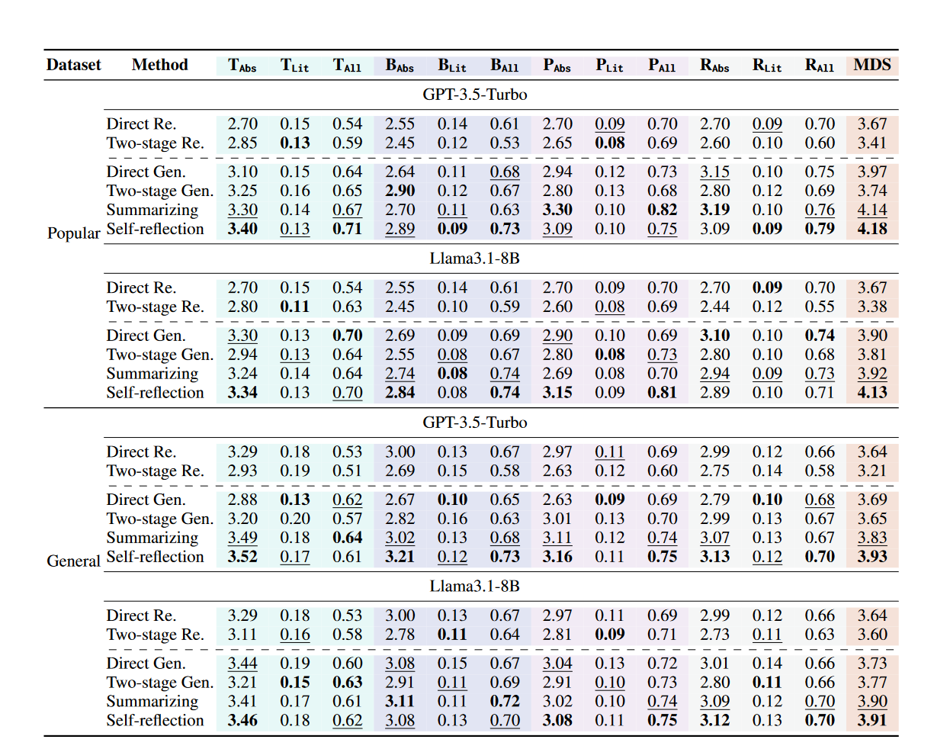
人工评估结果
Self-reflection 获得最高平均排名分和最高“被评为最佳”概率;
Direct Generation 在 Popular 上表现尚可,但在 General 上明显下降;
人工评价趋势与自动评估 高度一致,验证 MDS 可靠性。

四、总结与综合对齐思考
(一)论文核心内容
提出“历史类比获取”任务,给定当代事件,自动生成结构相似的历史事件(从主题、背景、过程、结果四维度类比)。其核心贡献包括:
构建首个历史类比评测基准(含20个流行类比 + 160个通用类比),并设计多维自动评估指标 MDS,与人类判断高度一致(r > 0.72)。
这篇文章提出一种基于双重推理循环的自反思框架(Self-reflection Framework),通过协同调用LLM的生成式推理与批判性评估能力,实现对历史类比的迭代优化。
(二)三维度对齐思考
1.0 技术创新-逻辑思维推理框架
这篇论文提出的多维结构化比较机制(主题/背景/过程/结果)启发食品领域的推理维度(营养成分、健康目标适配、行为友好性、综合优选),确保比较逻辑系统且可解释。同时参考其自反思框架通过“生成–批判–修正”闭环,从而提升推荐可靠性。
2.0 技术目标-专业手册公众服务
主要是在食品这个领域,帮助用户降低决策成本,结合营养成分含量,用户个性化喜好,自动帮用户选出更适合且更健康的食品。
3.0 场景功能-食养通
在pk比选这个部分进行应用,针对用户选中的食品,在系统中自动推出结合用户个性化的更健康产品,并展示出对比性解释说明提升推荐效果。