作者:Henry Li Xinyuan, Zexin Cai, Ashi Garg el
单位:Johns Hopkins University, United States
来源:Voice privacy 2024
时间:2024年
论文背景
随着语音数据在智能设备和云服务中的广泛应用,语音中蕴含的说话人身份信息(如声纹)成为重大隐私风险。全球多项法规(如GDPR、CCPA、POPIA等)要求对语音数据进行有效匿名化处理,同时保留其语言内容与情感表达。说话者匿名化是一种广泛研究的隐私保护解决方案。
在2024年的voicePrivacy中不仅强调了音频数据的最大匿名性,同时需要保持可懂度和可用性,而主流方法中的VC方法容易保留韵律、音素持续时间等问题,同时帧对齐的数据结构会有大量的身份信息残留,而同时级联ASR-TTS方法匿名效果强蛋对于音频数据中的副语言属性损失严重。
核心创新
1、论文实现了基于kNN-VC 的匿名化适应,通过 WavLM content 特征替代传统声学特征并离散化处理,构建匿名友好的伪目标生成机制,实现语音内容与身份信息解耦
2、基于WavLM的神经网络匿名化转换,使用 CTC 离散化转换目标结合对抗性 speaker-ID 损失和重建损失,在去除说话人身份的同时保持语音自然度与可懂度,并利用伪标签进行有效监督。
3、论文提出ASR–TTS 与 VC 的随机混合匿名策略,在多个匿名化生成管道间随机切换,使攻击者难以识别样本来源,显著增强语音匿名化系统的安全性与隐私保护能力
技术方案
论文围绕两大方法 VC和ASR-TTS方法,进行优化实验,同时进一步提出了随机选择的策略来平衡隐私保护和语音的效用
基于kNN-VC 的匿名化适应
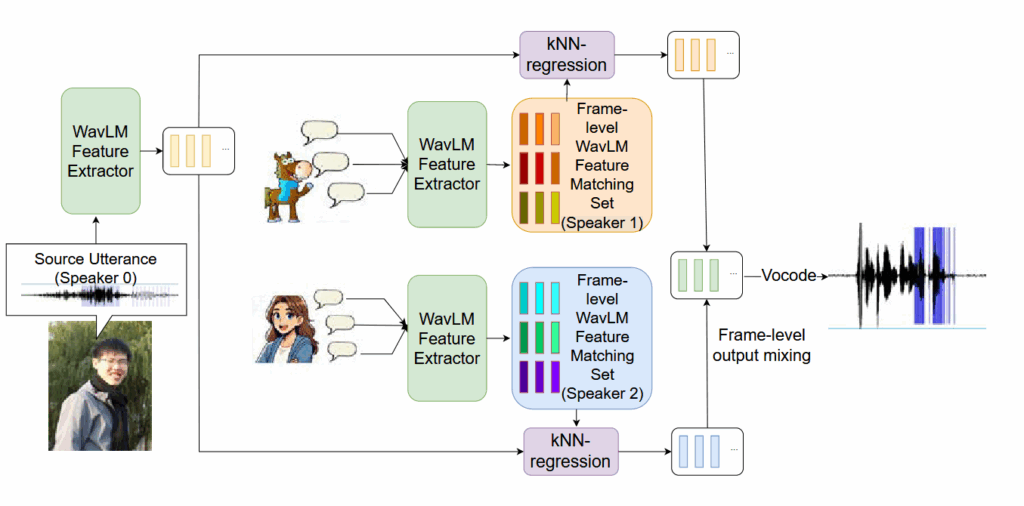
论文选用了kNN-VC 的匿名化适应版本用于基线的效果比较,同时将提取的数据特征用于后续的神经VC的ctc loss训练,将源语音和目标说话人语音映射为 WavLM 特征,对每个源语音帧,在目标说话人的特征池中寻找 k 个最近邻,取平均后通过 HiFi-GAN 声码器重建语音,论文方案通过在目标说话人中使用随机选择,提升了鲁棒性,同时对于语音和WavLM特征进行加噪,提高了隐私保护
WavLM 转换模型
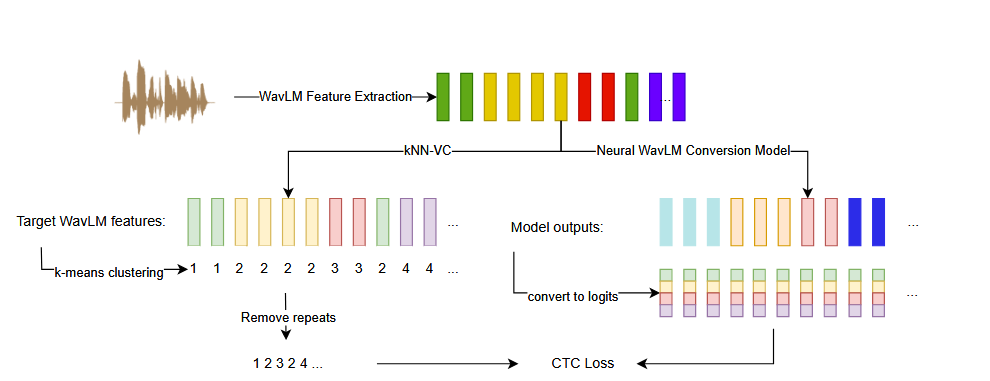
对于KNN中存在匿名性不足的问题,通过神经网络进行优化,方案架构基于 FastSpeech2 的非自回归编码器-解码器结构,处理 WavLM 特征而非梅尔谱,训练策略主要采用目标重构联合训练+联合对抗训练+离散对齐目标。
目标重构旨在通过替换训练中部分(w(u), k(w(u)))对,改为使用目标说话人大块语料,保证重建目标说话人的语音特征。
联合对抗训练是指模型训练中增加一个说话人识别器,目标是让识别器无法正确预测说话人。
离散对齐目标是论文中神经WavLM的核心模块,通过将连续声学特征离散化,并对齐成 token 序列,训练模型预测离散 token。原有FastSpeech2使用L1和L2损失来进行对抗训练,但是保留了数据中序列级信息,通过kmeans聚类方法对于wavlm特征进行离散化,在将源话语转换为离散token序列,通过模型的输出每一帧数据计算和kmeans质心的余弦距离用作logits,同时通过CTC损失用于约束训练,目的是让 token 序列预测任务与目标语音内容一致,而不复制原说话人的时序
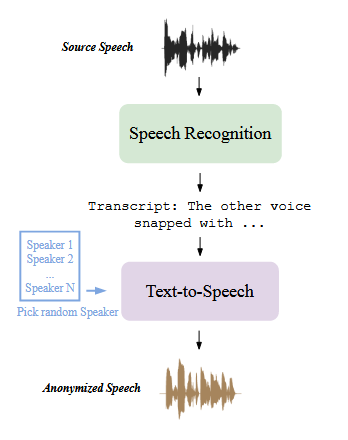
级联ASR-TTS匿名方法
论文采用的ASR-TTS级联匿名方法主要用于高匿名化数据的合成,来作为后续随机混合策略的选择方案,
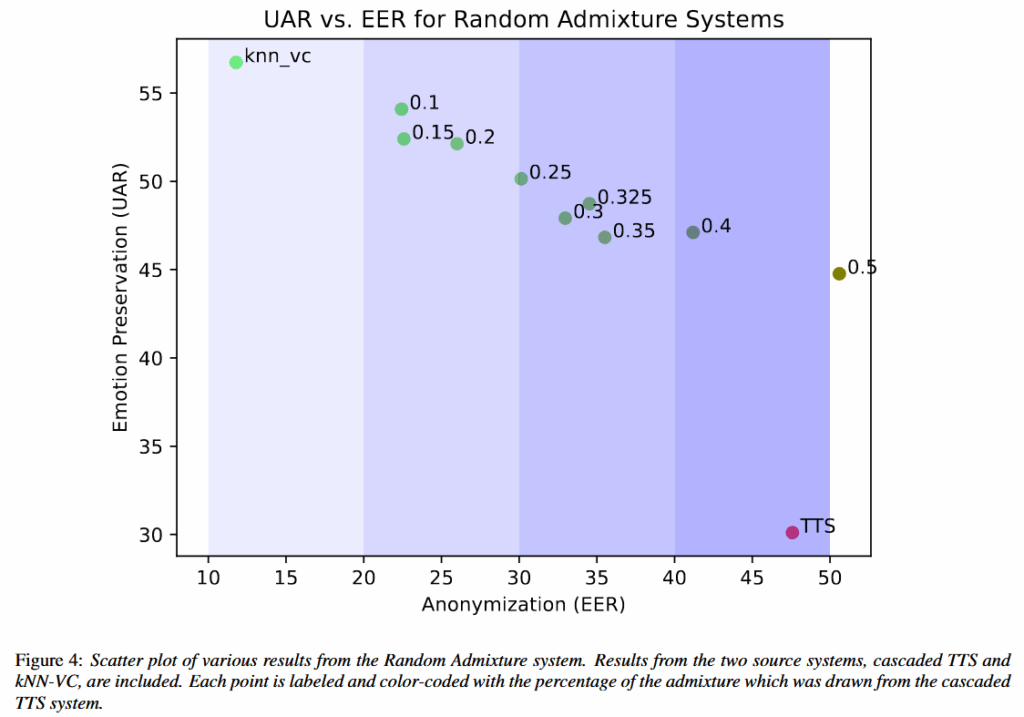
随机混合策略
论文从对神经网络的中毒攻击获得灵感,模型攻击时对于非线性数据的预测性差,可以通过在推理时以概率 p 随机选择使用 TTS 系统或 VC 系统,实现情感效用和隐私保护的灵活权衡,混合低质量/不同分布数据可显著干扰攻击者模型,从而使性能优于线性插值。
实验设置及分析
论文采用LibriSpeech和IEMOCAP语料库的子集,指标采用单词错误率WER和非加权平均回归UAR来评估匿名数据中的情绪状态保留。
课题对齐启发思考
1.1 技术创新–数据拓扑标签计算:基于VC方向的音频处理采用使用 WavLM content 层特征替代传统 MFCC/SF 或谱包络特征,同时采用离散化将连续声学特征 token化,降低数据在韵律和音色的信息泄漏,同时通过kNN-VC生成伪标签,为神经VC提供并行数据,减少真实数据的依赖
2.2 技术目标–虚拟声景孪生生成:对于音频数据的隐私保护,论文在生成中通过离散化连续声学特征,用于减少原本WavLM特征层中存在的韵律语速等时不变特征,同时针对于隐私保护效果的提升,在推理阶段使用随机选择策略,混合低质量/高匿名样本可非线性地削弱攻击模型性能,性能优于单一方案,这种生成策略可以一定程度指导正确的数据合成
3.2 场景功能—echomie:场景是需要实现用户音频数据在去隐私化的下游任务可复用,可以结合论文方案中的随机选择策略,通过非线性数据优化整体的隐私性