来源: 2024, CVPR
作者: Jiawei Ma, Po-Yao Huang, Saining Xie
单位: Colubmia University
一、论文主要工作
这篇文章提出了混合数据专家(模式),并通过聚类学习了CLIP 数据专家系统。每个数据专家都在一个数据集群上接受培训,对其他集群中的假阴性噪声不那么敏感。在推理时,通过应用任务元数据和集群条件之间的相关性确定的权重来集成它们的输出。为了准确估计相关性,一个聚类中的样本在语义上应该是相似的,但数据专家的数量仍然应该是合理的,以便进行训练和推理。因此,这篇研究考虑了人类语言中的本体,并提出使用细粒度的聚类中心来表示粗粒度的每个数据专家。
二、模型
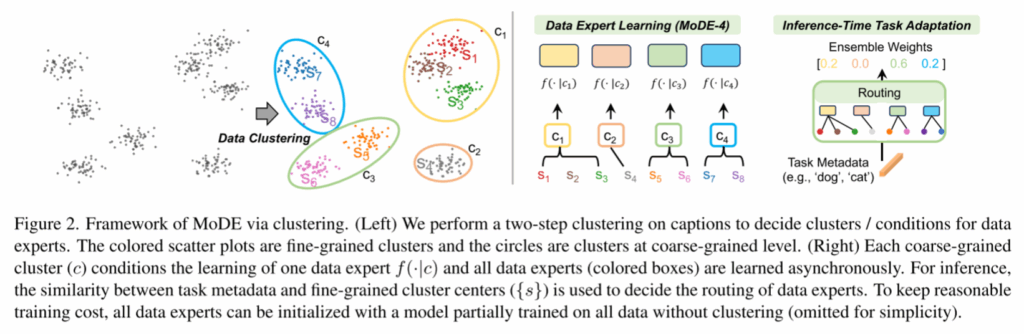
三、算法






四、实验结果
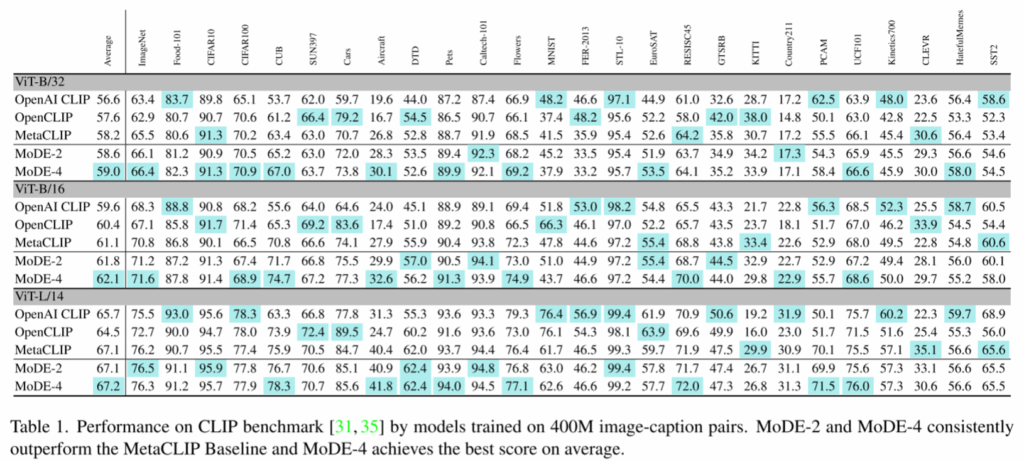
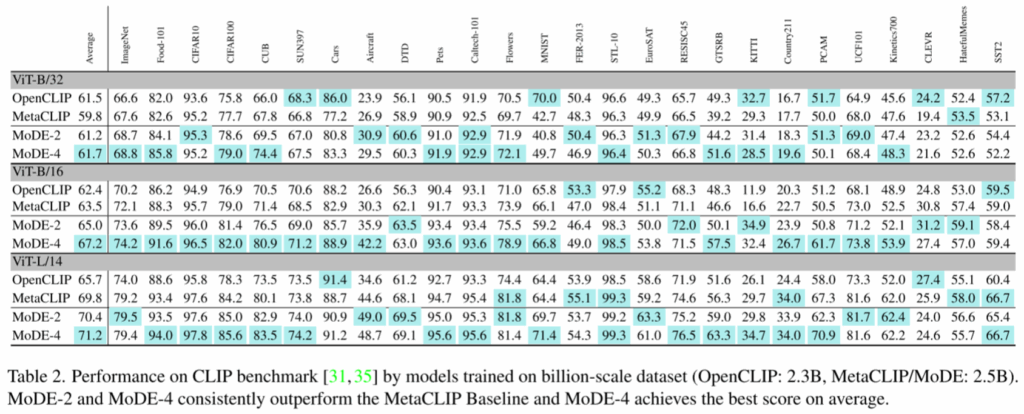
五、总结
课题综合对齐思考:
技术创新—数据拓扑标签计算:这篇研究所使用的技术手段是传统的
k-means,与我目前研究的数据拓扑标签计算关系不大。
技术目标—跨域知识结构对其:这篇研究的目的是使得文本与图像更好的对齐,不过其文本与图像都是已存在只需要做对应的映射学习就行;与我的跨数据集知识结构对齐关系不大。
场景功能—食养通:这篇研究所使用映射学习框架可以帮助食养通更好的将配料表与营养成分对齐。