来源:arXiv:2507.11079
作者:Li Wang, Qizhen Wu, Lei Chen
单位:北京理工大学,北京航空航天大学
一、背景
在多无人地面车辆(UGV)对抗中,系统需要根据战场环境自动生成协调的战术决策。然而现有方法存在显著不足:
- 基于规则的方法:虽然决策逻辑可解释,但适应性差,规则库膨胀导致复杂度高。
- 强化学习方法:具备一定自适应能力,但策略黑箱化,难以解释,且多集中于动作层控制而非战略层决策。
- 层级强化学习:虽结合规划与控制,但层间接口刚性,难以生成新战术模式。
为此,文章提出一种基于视觉-语言模型与轻量级大语言模型的“指挥官”架构,模拟人类指挥官的思维过程,实现从视觉感知到语言化推理再到战术决策的完整链条。
二、贡献
- 语义驱动的战术推理建模:将战术决策过程重构为自然语言认知过程,在共享语义空间中实现感知与推理一体化,模拟人类指挥官的思考逻辑。
- 基于VLM-LLM的指挥官架构:提出一种由视觉-语言模型和轻量级语言模型组成的全链式结构,实现从图像感知到战术调度的端到端闭环。
- 专家系统辅助训练与语义对齐:设计专家系统生成高质量战术标签与偏好数据,实现VLM与LLM之间的语义一致性,并通过DPO对齐优化推理稳定性。

三、方法
模型整体分为三部分:感知模块、决策模块和专家系统。
1.感知模块(VLM)
- 输入俯视图图像 I ,输出结构化语义信息 S = {Su, Sl, Sr }:
- 单元层 Su :识别各单位的位置、阵营、状态;
- 局部层 Sl :分析邻近单位间的空间关系与可见性;
- 区域层 Sr :总结各战区的敌我分布与区域态势。
- 通过这种层次化语义抽象,LLM能够直接在语义空间进行推理,无需复杂后处理。
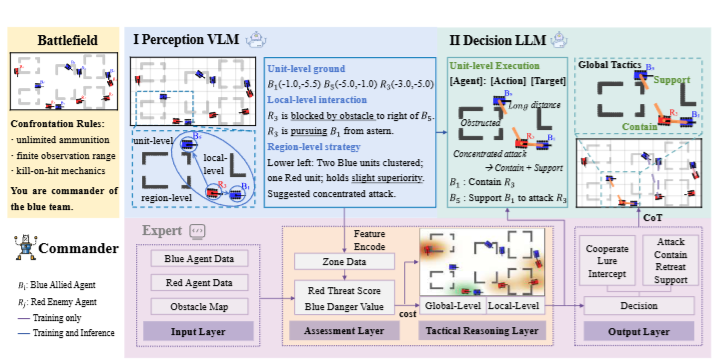
2.决策模块(LLM)
- 接受语义输入 S(t) ,输出战术指令集 U(t):
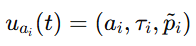
- 其中 τi 为动作类型(Attack, Support, Retreat等),pi 为目标位置。
- LLM负责任务分配、冲突解决与战术规划,可生成如包抄、诱敌、支援等复杂策略。
3.专家系统
- 模拟人类指挥逻辑,计算:
- 威胁值:衡量敌方战略影响;
- 危险值:评估我方受威胁程度;
- 攻击代价:综合距离、朝向、威胁程度与可见性;
- 协同代价:评估多机包抄的效果。
- 基于这些指标,系统生成“规则化战术指令”,作为LLM训练监督信号。
四、实验
- 实验环境:
- 仿真战场:30×16 m,最大步长2000,时间步0.1 s。
- 训练场景:5v5,测试扩展至7v7与9v9。
- 评价指标:感知精度P、召回率R、幻觉率RH、平均决策时间Tc、胜率RW、生存率RS、决策增益指数Idrv 。
- 基线模型: 规则模型(Rule)、强化学习(RL)、单VLM模型(VLM)。
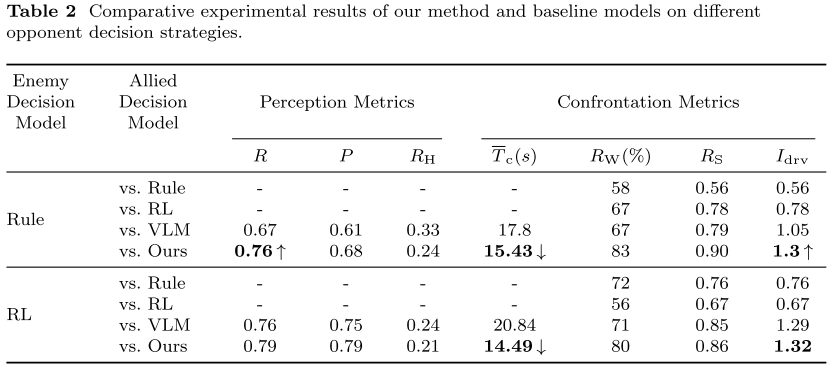
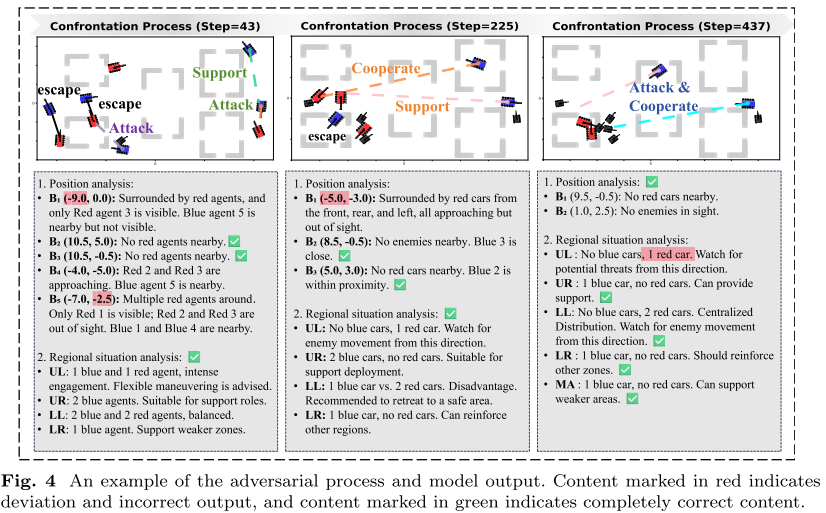
- 结果分析:
- VLM+LLM模型在感知精度、胜率、生存率等指标上均优于基线。
- 平均决策时间降低约 25%,同时保持更高决策质量。
- 即使出现部分视觉定位误差,LLM仍能保持合理推理并形成包围等高阶战术。
- 消融实验表明,去掉专家系统或LLM都会显著降低性能。
- 扩展到更大规模(9v9)后,VLM+LLM的感知准确率稳定在约 75%,体现出良好扩展性与鲁棒性。
五、结论
文章提出的基于视觉-语言模型的指挥官架构实现了从图像感知到战术决策的统一过程:
- VLM 负责场景理解与语义抽象;
- 轻量级 LLM 执行语言化战术推理与指令生成;
- 专家系统提供高质量训练监督与偏好对齐。
实验结果证明该架构在自适应性、可解释性和扩展性上均优于传统方法。