作者:Zinan Lin, Tadas Baltrusaitis, Wenyu Wang, Sergey Yekhanin
来源:arxiv
单位:Microsoft Research,Cambridge,Redmond
时间:2025年5月
背景
DP合成数据和原始数据在特征分布相似同时可以保持强大的隐私保障,与此同时,private evolution算法作为一种最近备受关注的合成数据算法,原始算法通过访问基础模型的推理API,可以利用最先进大模型的强大功能,但对于特定私有数据的领域不一定有合适的基础模型,当基础模型的训练数据和私有数据分布存在显著差异的时候,PE算法的性能远远落后于基于训练的方法。在不涉及私有数据的传统合成数据领域,存在强大的非神经网络数据合成器,如果让PE框架兼容这些模拟器,将极大扩展DP数据合成的适用。
论文核心贡献
1、提出了Sim-PE框架,在基础的PE算法框架上,将pe扩展为兼容非神经网路的版本,拓宽了pe框架的兼容性。
2、Sim-PE首次将模拟器引入DP合成数据,结合模拟器在特定数据领域的优秀性能,实现了dp特性的合成数据高效方法
3、Sim-PE实现了显著的性能提示,Mnist数据集上,分类准确率有原始PE的27.9%提升至89.1%,同时探讨了基础模型和弱模拟器相结合的性能提升效果
技术框架
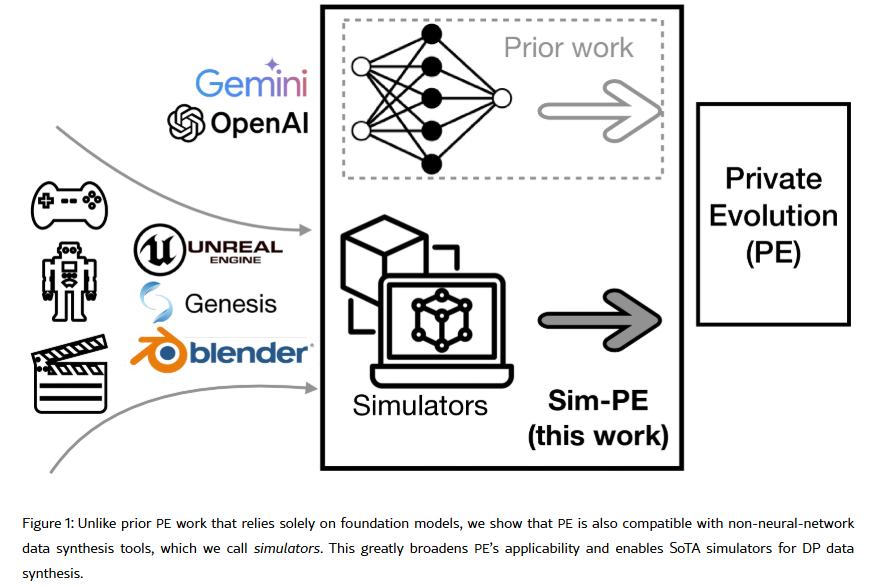
Sim-pe的技术框架中心思想是在原始PE框架的方法上保留原始的隐私机制和迭代结构,替换原始PE框架的RANDOM_API和VARIATION_API
方法框架的数据集选择的是计算机图像生成的特定领域,而在此特定领域中,部分模拟器开源,但是部分的模拟器在渲染器中使用的资产通常是专用的,许多模拟器仅仅发布数据集,而不是模拟器代码。所以Sim-pe按照作者分为具有模拟器访问的Sim-pe和使用模拟器生成数据的Sim-pe
具有模拟器访问的Sim-pe
不同的模拟器的不同编程接口可以抽象为一组抽象的接口参数,p分类参数ξ1,…,ξp
和q数值参数ϕ1,…,ϕq,RANDOM_API只需要从相应的可信集中随机绘制参数
RANDOM_API=𝒮(ξ1,…,ξp,ϕ1,…,ϕq),
而对于VARIATION_API,需要通过扰动输入的图像参数来生成变化,对于q数值参数添加对应的噪声,而p数值参数不适用于直接添加噪声, 因此需要按照一定概率从可行集中重新绘制参数
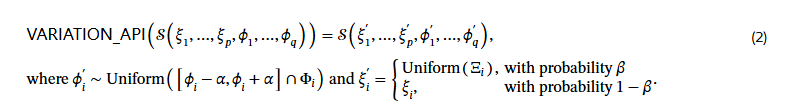
使用模拟器生成数据的Sim-pe
由于模拟器会生成大量的合成数据,避免让私有样本考虑整个Ssim,将隐私预算浪费在评估上,基于此,Sim-pe采用两条重要策略1、只从Ssim中随机抽取N_syn作为当前候选集。2、对于被抽中的样本只在最近邻k样本采用,避免将远离私有数据的区域引入下一轮, 同时控制近邻范围
模拟器和基础模型结合的Sim-pe
论文简单探讨了模拟器和基础模型的结合,探索了简单的策略,在早期的 PE 迭代中使用模拟器来生成不同的种子样本,然后在后面的迭代中切换到基础模型来完善细节并增强真实感,这种方法在实验中优于单独使用模拟器或者基础模型。
实验及分析
数据集:MNIST数据集(数字分类)、CelebA数据集(人脸性别分类)
模拟器类型:文本渲染程序、基于计算机图像的人脸图像渲染器、基于规则的头像生成器
下游分类器:ResNet、WideResNet、ResNeXt
评估指标:FID、下游分类器的准确性
隐私预算参数设为 ϵ=1,10, δ=1/(NlogN)
结果分析

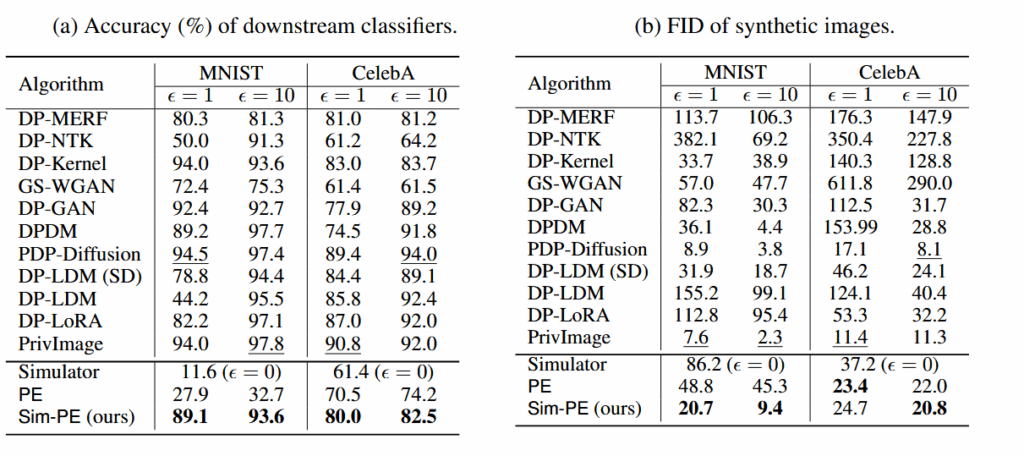
在 MNIST 上,Sim-PE 把 PE 的性能从 ~28% 提升到 ~89%(ε=1),对于 CelebA(真实人脸),PE 本身效果已相对不错,但 Sim-PE 仍带来明显改进(≈ +9 到 +8.3 百分点)
在 MNIST 上,Sim-PE 不仅提升分类准确率,也显著改善 FID(尤其在 ε=10 时 FID 降到 9.4,接近训练型方法的水平);在 CelebA 上,Sim-PE 的 FID 与 PE 相当或稍优,这说明当基础模型与私有数据更接近时,Sim-PE 保持或微幅提升质量。
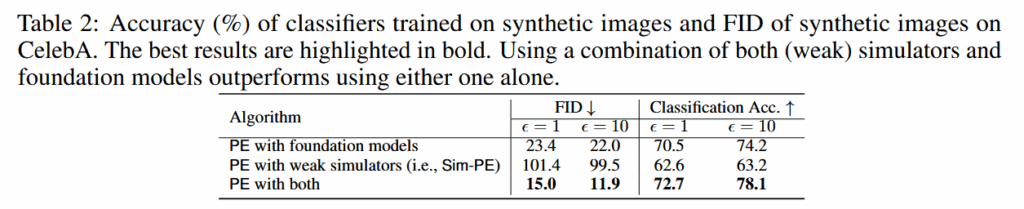
弱模拟器本身图像不真实(高 FID),直接用 Sim-PE 效果有限,但生成的样本仍保留正确的面部布局(眼鼻嘴位置等),作为种子能显著提高后续 foundation model 的采样效果;因此“模拟器 + foundation model”的协同是一个有价值的方向。
总结及启发
总结:论文基于pe框架,提出了Sim-pe,用模拟器替代基础模型作为生成器,从而达到特定数据领域的优秀能力,核心能力扩展pe的API结构,使任何可生成数据的系统都可以参与DP数据生成,在没有大模型可访问的场景下,仅依靠公开模拟器也可以实现DP数据生成,在性能上,在 MNIST 上准确率从 27.9%(PE)→ 89.1%(Sim-PE),同时推理效率优于原始pe框架,在隐私预算低的情况下仍然表现稳健。
启发:论文是pe框架的扩展方向,主要是模拟器的兼容,对于音频数据的生成具有一定的启发性,探索音频数据在pe框架的适配可以用音频合成器来进行隐私音频数据的生成,其中模拟器的参数可以相对应的更改为音高、声纹、语速、环境噪声等于音频数据的特征,其中噪声是否可以替换为音频特征空间的扰动,来保证说话人的匿名和隐私保护。