2025.10.15-gongchenhao
作者:肖超君、胡雪玉、刘知远、涂存超、孙茂松
来源:AI Open
单位:清华大学计算机科学与技术系,北京航空航天大学
发表日期:2021.6.23
一.论文介绍
随着人工智能技术的飞速发展,法律人工智能(LegalAI)旨在利用自然语言处理(NLP)技术赋能法律系统,提升司法效率并促进司法公正。近年来,预训练语言模型(PLMs)在各类NLP任务中取得了巨大成功。然而,将PLMs直接应用于法律领域仍面临一个核心挑战:法律文档(如案例、判决书)通常长达数千字,远超主流PLMs(如BERT、RoBERTa)512个令牌的长度处理极限。
本论文提出了 Lawformer,这是首个专为中文法律长文档理解而设计的预训练语言模型。
在多个典型的LegalAI任务上对Lawformer进行了全面评估,并与BERT、RoBERTa及在法律语料上继续预训练的RoBERTa(L-RoBERTa)等强基线模型进行对比。
实验结果表明,Lawformer能够有效处理中文法律长文档,并在相关任务上实现显著性能提升。本论文释放的模型、代码与数据集将为法律AI社区的发展提供重要支撑。
二、核心内容
- 核心问题:
主流预训练语言模型(如BERT)最多只能处理512个令牌的文本,但中文法律文档平均长度超过1260个令牌。直接截断输入会导致信息丢失,严重制约了法律人工智能的性能。 - 解决方案:
提出 Lawformer——一个专为中文法律长文档设计的预训练语言模型。
架构创新:采用 Longformer 的高效注意力机制(结合滑动窗口、膨胀窗口和全局注意力),将文本处理长度提升至4096个令牌,并能以线性计算复杂度捕获长距离依赖。
领域适配:在大规模中文法律语料(84GB,含数百万刑事/民事案例)上,从通用模型(RoBERTa)继续预训练,使其精通法律语言。
- 关键贡献:
首个专为法律长文档设计的预训练模型。
构建并发布了新的长文档判决预测数据集 CAIL-Long,其案例长度分布更贴近真实世界。
在法律判决预测和类似案例检索等依赖长文档输入的任务上,性能显著优于BERT、RoBERTa等基线模型。
- 核心结论:
Lawformer 有效解决了法律长文档的处理瓶颈,证明了领域专用的长文本模型对于提升LegalAI任务性能至关重要,为法律AI的发展提供了重要的基础模型和基准。
三、实验评估
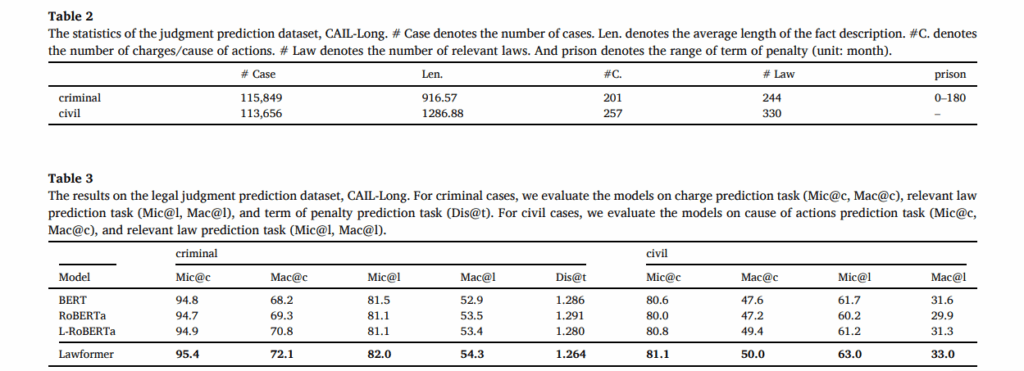
四、总结与思考
Lawformer的成功,本质上在于它精准地构建并实现了三个关键要素的高度对齐:
明确的领域痛点:精准识别了法律AI的核心矛盾——长文档与短模型之间的鸿沟。
务实的技术路径:没有从头造轮子,而是巧妙地集成了先进的Longformer架构与领域自适应预训练范式,以最高效的方式解决了核心问题。
可靠的数据与评估:不仅使用了大规模数据,更构建了CAIL-Long这一更贴近现实的基准,为验证模型性能和推动后续研究奠定了坚实基础。
Lawformer的出现标志着领域AI进入“深水区”。它表明,在通用大模型的基础上,针对特定领域的核心痛点进行“深度定制”,是推动AI落地应用的必由之路。这种方法论不仅可以应用于法律,同样可以迁移到金融、医疗、科研等任何具有复杂、长文本和专业知识的领域。
Lawformer是一座里程碑。它成功地证明了领域专用长文本模型的必要性和可行性,为法律AI的研究与应用打开了新局面。同时,它也是一块“跳板”,其成果与局限共同为未来研究绘制了清晰的路线图:从处理长文档,走向实现深知识与强生成的下一代法律智能系统。