来源:WWW ’25
作者:Yuhan Li、Xinni Zhang等
单位:香港科技大学、香港中文大学、华为.
发表时间:2025 年 4月
一、研究背景
- 传统推荐系统(如协同过滤、矩阵分解、图神经网络 GNN)在预测准确性上取得了显著进展,但普遍存在:黑箱性、缺乏个性化解释、静态建模
- 大语言模型:近年来,LLM(如 GPT、LLaMA)在自然语言生成、推理和对话方面展现出强大能力,被广泛用于可解释推荐,但纯LLM方法存在幻觉问题、缺乏结构化用户行为建模等缺陷。
- 检索增强生成(RAG):应从用户-物品交互图中检索出“可解释的、显式的协同证据”(如相似用户行为、物品共现路径),再将这些证据以自然语言形式输入 LLM,引导其生成忠实、个性化解释。
- 传统推荐系统 → 准确但不可解释
- 纯LLM推荐 → 可解释但不准确/易幻觉
- GNN+LLM初步融合 → 仍存在隐式表示与模态鸿沟
核心问题:让 LLM 能理解图结构中隐式的协同过滤信息(CF signals),并生成可解释的推荐理由(explanation)。
方法:Graph Retrieval-Augmented Generation(GraphRAG)
二、G-Refer框架
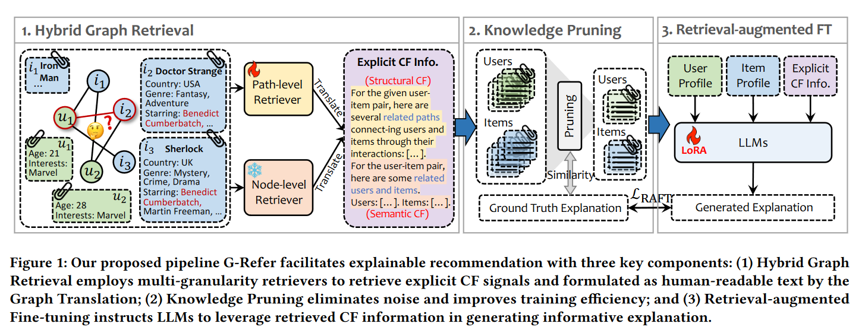
模块1:混合图检索器(Hybrid Graph Retriever)
目标:从原始的用户-物品交互图中,显式地检索出与当前用户-物品对相关的、可解释的协同信号,而非依赖隐式的图神经网络嵌入。
- 检索的两个互补粒度:
- 节点级检索:找出与当前用户或物品语义或行为相似的其他用户/物品。
- 路径级检索:挖掘用户与物品之间高阶连接路径,揭示间接协同关系。
模块2:知识剪枝(Knowledge Pruning)
目标:与真实标签对齐,从原始检索到的候选证据集合中,自动筛选出与“真实解释”最相关、最有解释力的子集,仅用这个子集进行微调。
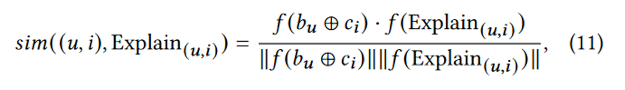
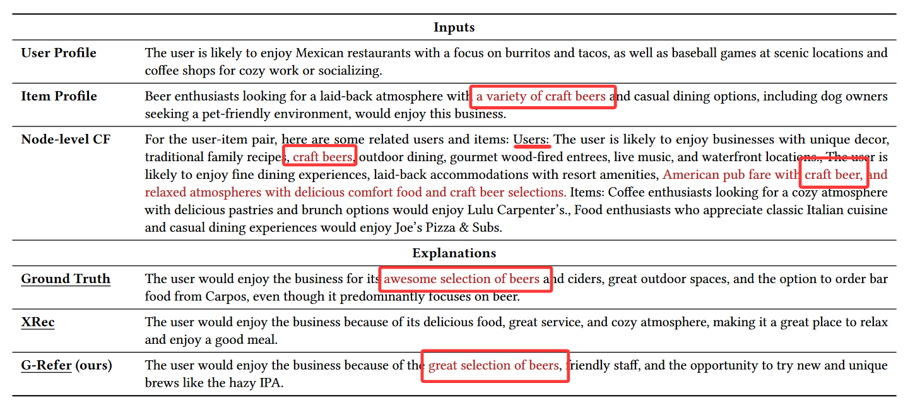
使用一个语义相似度模型计算:用剪枝后的证据子集替代原始证据;作为 LLM 的输入进行微调。
模块3:检索增强微调(RAFT)
目标:训练 LLM 学会有效利用检索到的图翻译文本,生成准确、个性化、流畅的推荐解释。
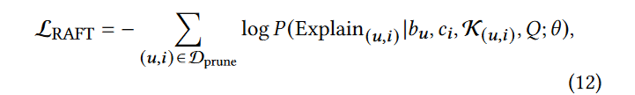
把 RAG 的“推理时行为”前置到“训练阶段”,让模型内化“如何用检索结果”。
结果表明:3B 和 7B 几乎一样好
三、实验
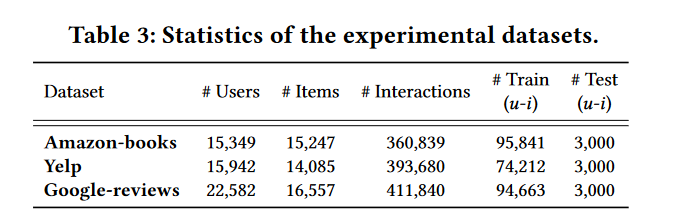
数据集选择
评估指标(采用语义级指标)
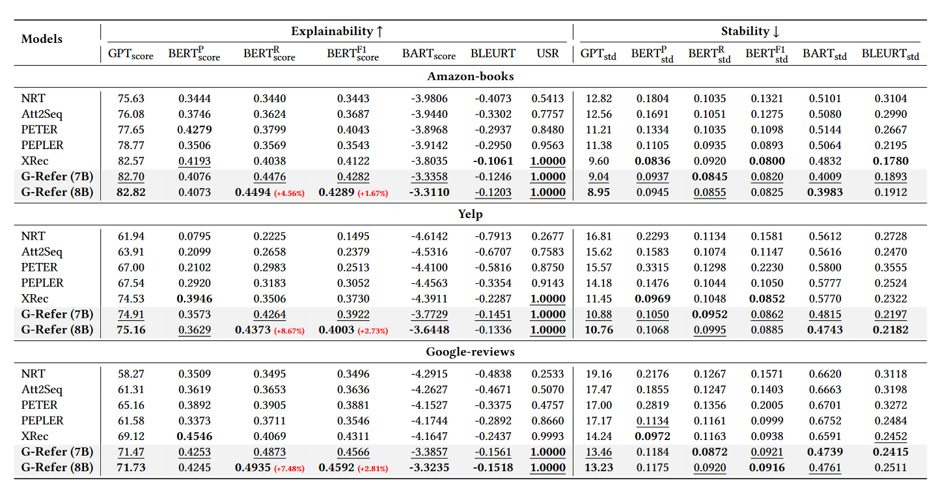
- GPTScore:用 GPT-3.5-turbo 判断生成解释与参考解释的语义一致性。
- BERTScore (F1/Recall):衡量 token-level 语义对齐;Recall 特别用于评估检索 CF 信息的完整性。
- BARTScore:基于 BART 的序列到序列评分。
- BLEURT:Google 提出的鲁棒语义评估指标。
- USR:用户模拟器评估(User Simulation Reward)。
核心实验结果
四、总结与综合对其思考
(一)论文核心内容
G-Refer 首次将图检索增强生成(Graph-RAG)引入可解释推荐,通过混合图检索 + 知识剪枝 + 检索增强微调,显著提升大语言模型生成解释的准确性、语义质量与稳定性:
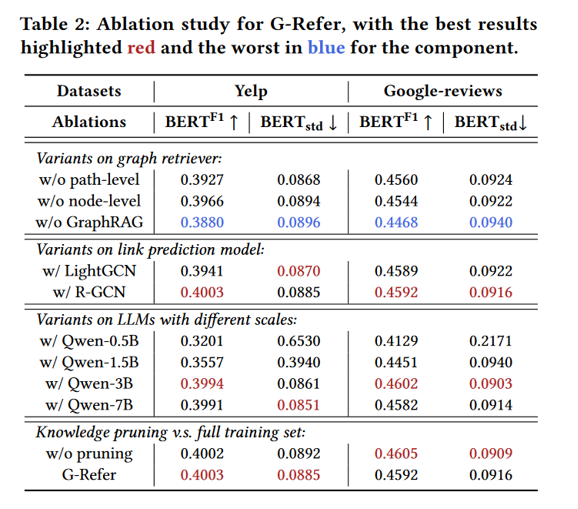
- 混合图检索:联合路径级与节点级检索,从用户-物品交互图中提取显式协同过滤(CF)证据。
- 知识剪枝:基于相关性过滤低质量检索样本,去噪提效。
- 检索增强微调(RAFT):用 LoRA 微调 LLM,使其学会融合图证据生成忠实、可解释的推荐理由。结果表明一个3B模型能达到7B效果。
(二)综合对其思考
- “食物相似度”检索:利用论文中Hybrid Graph Retrieval 思路,将“食物相似度”从单一语义向量扩展为图结构+语义双通道的检索,使候选B的来源更有依据。
- 检索改进:检索阶段可借鉴G-Refer的Graph Translation思路,将知识图谱检索结果翻译为自然语言输入,结合“检索 → 语言模型生成解释”的GraphRAG这种流程。