作者:Kun Li, Tianhua Zhang, Xixin Wu,Hongyin Luo, James Glass, Helen Meng
单位:The Chinese University of Hong Kong, Hong Kong SAR, China
来源:arxiv
时间:2024
一、研究背景及意义
研究背景:
1. LLMs的局限性 大型语言模型虽然在各种自然语言处理任务上表现出色,但在知识密集型场景中仍面临两个核心问题:缺乏准确的事实知识和容易产生幻觉。这限制了LLMs在需要精确事实推理的任务中的应用。
2. 知识图谱的优势与挑战
知识图谱以结构化和显式的方式表示知识,是理想的外部知识源。然而,如何有效地将LLMs与KGs结合用于问答任务仍存在挑战。
3. 现有方法的不足 当前KGQA方法主要分为两类,都存在明显局限:
迭代提示方法:通过复杂指令让LLMs逐步在KG上推理,但对模型能力要求极高,通常需要GPT-4或Llama2-70B等大参数模型
子图检索方法:依赖专门训练的检索器提取相关子图,但需要大量标注数据,且在跨域场景下泛化能力差
研究意义:
1. 理论创新
- 首次提出”well-formed chain”概念,为在知识图谱上进行忠实且可靠的推理提供了理论基础
- 该概念确保推理链中的每个事实三元组都存在于KG中,且每步推理都基于先前访问过的实体
2. 技术突破
- 创新性地提出图感知约束解码(graph-aware constrained decoding)方法
- 通过KG拓扑结构约束LLMs的解码过程,从硬约束层面保证生成well-formed chains
- 实现了LLMs逐步推理能力与KGs结构化知识的深度融合
二、研究思路及内容
研究思路
DoG的核心思路是让LLMs直接在知识图谱上进行逐步推理,而不是依赖外部检索器或复杂的迭代指令。如图1所示,整个推理过程从问题”What is the national flower of the location where the movie ‘Blue Hawaii’ is set?”开始,系统需要找到一条从查询实体”Blue Hawaii”到答案”Hawaiian hibiscus”的推理链。
研究的关键洞察是:LLMs擅长生成连贯的推理步骤,而KGs提供了结构化的事实连接,两者可以通过约束解码机制深度融合,实现faithful且sound的推理过程。
核心方法与技术内容

Well-formed Chain定义与图感知约束解码
DoG首先定义了”well-formed chain”概念,要求推理链中的每个三元组都存在于KG中,且每步推理都基于之前访问过的实体。图1(b)展示了初始的查询中心子图Gq,包含所有与查询实体”Blue Hawaii”相关的三元组。
约束解码的核心是动态构建Trie数据结构来限制有效token。如图1(c)所示,在第一步推理中,系统构建了一个Trie树,根节点下分别有”Blue Hawaii”通往不同关系的路径。当生成到”Blue Hawaii”时,有效token集合Wval只包含{“film.performance.actor”, “film.film.featured_film_locations”},LLMs在这个约束下更可能选择与问题相关的”film.film.featured_film_locations”。
动态子图扩展与多步推理
推理过程是动态的。图1(d)显示第一步推理结果后,系统选择了三元组”Blue Hawaii → film.film.featured_film_locations → Hawaii”。随后如图1(e)所示,查询中心子图Gq动态扩展,将所有涉及新访问实体”Hawaii”的三元组加入子图(用虚线表示)。这种扩展确保了下一步推理的所有可能性都被考虑。
第二步推理中,系统进一步发现”Hawaiian hibiscus → location.symbol_of_administrative_division.official_symbol_of → Hawaii”,最终形成完整的推理链并得出正确答案。
Beam Search优化与实现细节
系统采用两层beam search:token级别的beam search生成多个候选三元组,三元组级别的beam search保留得分最高的推理链。每个三元组的得分基于LLM对该三元组的条件概率,链得分是所有三元组得分的累加。
整个过程中,约束解码只在生成三元组结构时生效(<T_BOS>到<T_EOS>之间),而中间的分析文本和最终结论采用无约束生成,保持了LLMs的自然语言表达能力。
实验结果
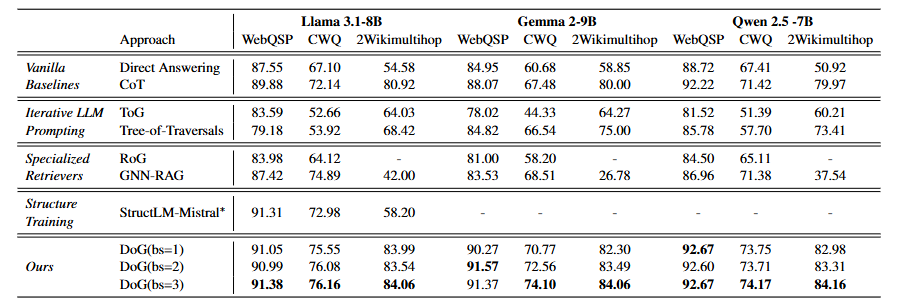
在WebQuestionSP上,Direct Answering就能达到87-88%的性能,说明LLMs对简单图结构有一定理解能力。但在多跳问题更多的CWQ和2Wikimultihop上,Direct Answering性能显著下降(CWQ约60-67%,2Wikimultihop约50-58%)。
DoG的表现始终优异:在WebQuestionSP上达到91-93%,CWQ上达到73-76%,2Wikimultihop上达到82-84%。特别值得注意的是,DoG在所有三个LLM上都超越了专门训练的StructLM方法,证明了约束解码的有效性。
专门检索器(RoG、GNN-RAG)在训练域内表现较好,但无法适应2Wikimultihop的Wikidata背景,体现了跨域泛化的困难。而DoG在所有数据集上都保持稳定的高性能。

表4对比了DoG在完整KG输入vs局部子图输入下的性能。结果显示,全局可见性在大多数情况下都带来性能提升,特别是在Qwen模型上差异明显(如2Wikimultihop上83.31% vs 76.22%)。这说明让LLMs看到完整的图结构有助于更好的路径规划,尽管会带来一些计算开销。
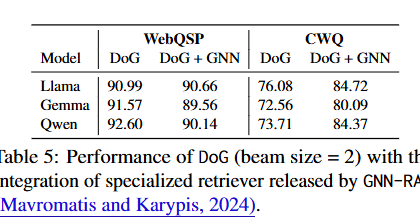
表5展示了DoG与GNN-RAG检索器结合的结果。在CWQ数据集上,这种结合带来了进一步的性能提升(如Llama上从76.08%提升到84.72%)。这表明DoG可以从高质量的子图中获益,但同时也说明完整KG中确实存在一定噪音。不过,考虑到专门检索器的训练成本和跨域适应问题,这种提升的实用性有限。
对齐思考
- 参考DoG中well-formed chain的思路,将复杂标签分解为有序的子标签序列,每个子标签必须基于前面已确定的标签信息,确保解构过程的逻辑一致性。可以设计标签依赖图来约束解构路径。
- 借鉴图感知约束解码的思想,在标签解构过程中引入领域知识作为硬约束,限制每一步可选的标签分解方向,避免生成不合理的标签组合。
- 参考beam search的思路,在标签解构时保持多个候选路径,通过一致性检验选择最优的解构方案。