作者:Ben Poole、Ajay Jain、Jonathan T. Barron、Ben Mildenhall
单位:Google Research、UC Berkeley
来源:ICLR
时间:2023
一、研究背景及意义
①当前AIGC在text-to-image以及image-to-image这些领域取得了飞速进展。而相比于2D视觉,3D视觉近几年得到了更多的关注,从近几年CVPR的Oral甚至Best paper candidate也能看出这个趋势。所以将AIGC从2D领域引入到3D领域,无论从学术研究还是企业落地,都是值得探索的。
②3D生成任务要比2D生成任务难得多。图像数据的来源是广泛的,无论是数据生产还是互联网图像的爬取,甚至是在现有的开源数据集中,2D数据都要比3D数据多的多,这便在数据层面上限制了3D生成工作的推进。如何将现有的Diffusion model(DM)用起来,并规避3D数据匮乏的缺陷,是text-to-3D任务所面临的,也是要解决的。
③3D对象的表示,现有的3D表示方法可以大致分成显式和隐式两类。显式表示依赖拓扑结构固定的模板,这种表示方法对于人体(SMPL)或人手(MANO)比较友好,但是在通用对象的生成任务上则显得比较鸡肋,因为我们不可能对于每一类物体都去得到对应的模板,在可行性上便一票否定了。所以,隐式地表示生成对象的几何对于本任务更合理。
二、研究思路及方法
(1)模型
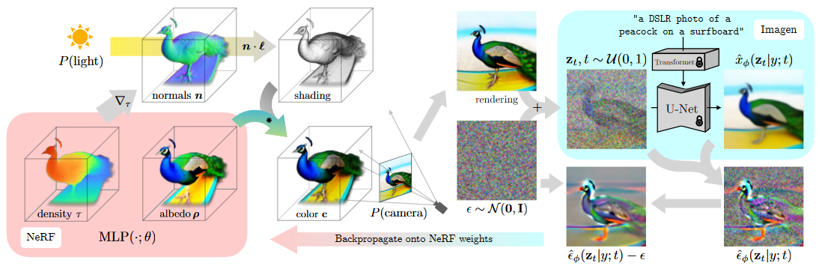
DreamFusion模型结构图
①生成
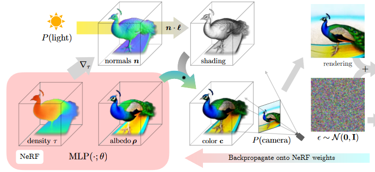
DreamFusion采用的扩散模型出自谷歌的Imagen,Imagen通过扩散模型可以实现text-to-image的效果。DreamFusion将Imagen作为文生图的“工具”,希望在给定的文本text作为输入的情况下,得到文本对应的图像。在图像的生成过程中,不同视角的生成受到文本中与方向有关的描述所控制。
②表示
对于生成对象的3D表示,DreamFusion采用了Mip-NeRF。
(2)整体流程
①给定一段输入的文本(以pipeline中的“a DSLR photo of a peacock on a surfboard”为例),并将其送到训练好的Imagen中,此时可以得到该文本所对应的生成图像。
②另一方面,随机初始化NeRF,然后在球坐标中随机采样一个相机参数P并在相机周围采样点光源,这时我们便可以在相机P下对NeRF场进行渲染(render),从而得到该相机参数P下对应的render图。注意,这里render的图像分辨率也是64*64的,从而保证与Imagen的输出保持一致。不同的相机参数P影响了对输入文本的更改,从而控制Imagen的生成过程。
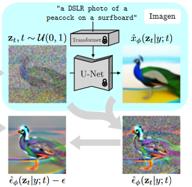
③通过上面两步,可以得到了Imagen的输出a,NeRF的render结果b。现在要做的是,怎么利用a和b,从而优化NeRF的网络参数,并得到最终预期结果。
④具体来说,首先是扩散模型固有的加噪过程。通过不断地往render结果b上加高斯噪声b’,最终可以得到纯噪声c。此时对这个纯噪声c执行去噪过程(个人认为这时可以把Imagen当作VAE的解码器),并得到a’。我们知道,扩散模型的去噪过程实际上是在估计噪声,然后估计的噪声和添加的噪声之间求loss。所以a’与加入的高斯噪声b’相减,便有了c’。c’将直接用来更新NeRF的权重,从而使render的结果b更加真实,如此迭代下去。。。便可以得到text-to-3D的效果。
(3)SDS LOSS

SDS的原理
①对于一个用θ_i表示的参数化网络(对应本文的参数化NeRF)
②通过可微的图像生成器g(θ_i)得到了变换后的x_i,在上图中把这里的g(·)表示成flip(·)(对应本文NeRF的可微渲染过程)
③将生成器g(θ_i)得到的x_i与真值的x ̂_i求损失L(x_i)并通过梯度下降的方式更新θ_i,从而使满足预期要求(对应本文的通过c’来更新NeRF的参数)。
三、结果

四、总结与思考
(1)总结
DreamFusion将比较火热的大语言模型引入到3D内容生成中;
扩散模型和NeRF两大热点相结合;
分辨率和生成效率问题是短板;
用带有方向信息的文本来控制不同视角的生成,这种做法对拓扑结构简单的对象是可行的,但是如果更换成更加复杂的对象(比如人体、人手),其生成结果会变得很糟糕。
(2)思考
因为Imagen的输出分辨率是有限的,所以可能导致DreamFusion的分辨率受到限制。
对于不同视角,本文采用粗略的描述可能会导致NeRF中render的图像与Imagen生成的图像不一致。
如何保证不同视角之间的一致性在本文中没有过多关注,但是对于本任务却是重要的;